Python机器学习之数据探索可视化库yellowbrick
# 背景介绍
从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维。陆续使用过plotly、seaborn,最终定格在了Bokeh,因为它可以与Flask完美的结合,数据看板的开发难度降低了很多。
前阵子看到这个库可以较为便捷的实现数据探索,今天得空打算学习一下。原本访问的是英文文档,结果发现已经有人在做汉化,虽然看起来也像是谷歌翻译的,本着拿来主义,少费点精力的精神,就半抄半学,还是发现了一些与文档不太一致的地方。
```python
# http://www.scikit-yb.org/zh/latest/quickstart.html
# http://www.scikit-yb.org/en/latest/quickstart.html
```
```python
import pandas as pd
data = pd.read_csv('data/bikeshare/bikeshare.csv')
X = data[[
"season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"
]]
y = data["riders"]
```
```python
from yellowbrick.features import Rank2D
visualizer = Rank2D(algorithm="pearson")
visualizer.fit_transform(X.values)
visualizer.poof() # 在notebook显示
# visualizer.poof(outpath="pcoords.jpg",clear_figure=True) # 输出为png、jpg格式
```
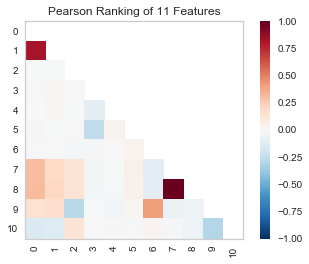
由上图可以看出特征向量7、8为强相关;0、1相关系数也比较高。
下面再来通过曲线拟合看看两者的相关度。
```python
from yellowbrick.features import JointPlotVisualizer
visualizer = JointPlotVisualizer(feature='temp', target='feelslike')
visualizer.fit(X['temp'], X['feelslike'])
visualizer.poof()
```
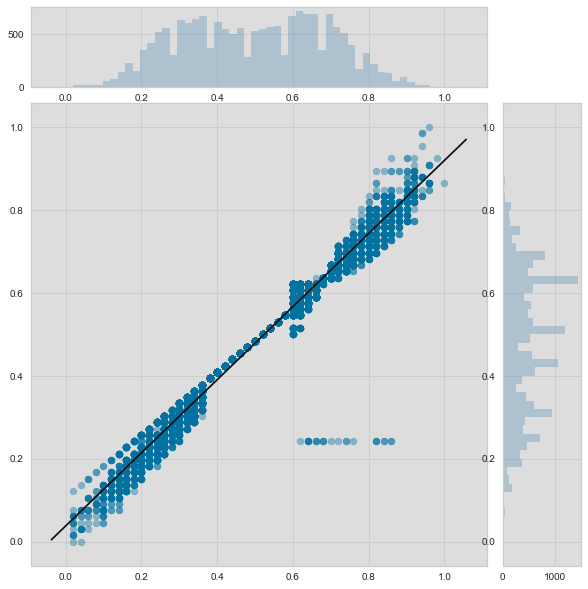
JointPlotVisualizer 让我们能快速浏览有强相关性的特征,以及各个特征的范围和分布情况。需要注意的是图中的各个轴都已经标准化到0到1之间的值,这是机器学习中一中非常常用的减少一个特征对另一个影响的技术。
```python
from yellowbrick.regressor import ResidualsPlot
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1
)
visualizer = ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
```
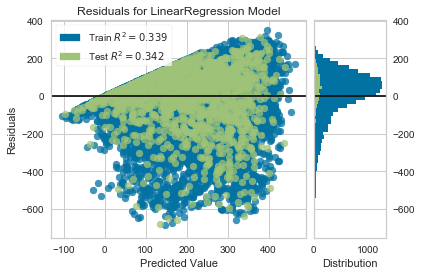
残差图还向我们展示了模型的误差是怎么产生的:那根加粗的水平线表示的是 residuals = 0 ,也就是没有误差;线上方或者下方的点则表示误差值的大小。比如大部分残差是负值,并且其值是由 actual - expected 算得,也就是说大部分时间预测值比实际值要大,比如和实际相比我们的模型总是预测有更多的骑手。|
```python
import numpy as np
from sklearn.linear_model import RidgeCV
from yellowbrick.regressor import AlphaSelection
# RidgeCV:多个阿尔法,得出多个对应最佳的w,然后得到最佳的w及对应的阿尔法
alphas = np.logspace(-10, 1, 200)
visualizer = AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.poof()
```
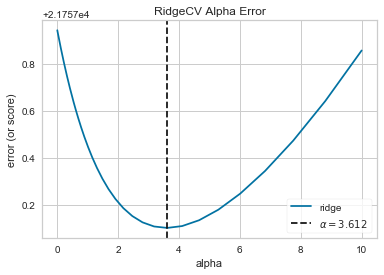
```python
alpha = visualizer.alpha_
visualizer.alpha_
```
3.612342699709438
在探索模型家族的过程中,第一个要考虑的是模型是怎样变得更*复杂*的。当模型的复杂度增加,由于方差增加形成的误差也相应增加,因为模型会变得过拟合并且不能泛化到未知数据上。然而,模型越简单由于偏差造成的误差就会越大;模型欠拟合,因此有更多的未中靶预测。大部分机器学习的目的就是要产生一个*复杂度适中*的模型,在偏差和方差之间找到一个中间点。
对一个线性模型来说,复杂度来自于特征本身以及根据模型赋予它们的值。因此对线性模型期望用*最少的特征*达到最好的阐释结果。*正则化*是实现如上目标的其中一种技术,即引入一个alpha参数来对其相互之间系数的权重进行标准化并且惩罚其复杂度。Alpha和复杂度之间是一个负相关。alpha值越大,复杂度越小,反之亦然。
我们现在可以训练我们最终的模型并且用 PredictionError 对其进行可视化了:
```python
from sklearn.linear_model import Ridge
from yellowbrick.regressor import PredictionError
visualizer = PredictionError(Ridge(alpha=alpha))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
```
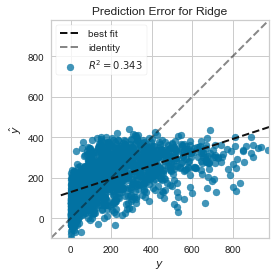
用预测误差visualizer将实际(测量)值对期望(预测)值进行可视化。黑色的45度虚线表示误差为0的点。和残差图一样,这让我们可以看到误差在何处出现,值为多大。
在这个图上,我们可以看到大部分的点集中在小于200骑手的位置。我们也许想要尝试用正交匹配追踪算法(OMP)或者样条(spline)来训练一个将更多区域性考虑进来的回归模型。我们还可以看到残差图中奇怪的拓扑结构好像已被Ridge回归纠正,而且在我们的模型中大值和小值之间有了更多的平衡。Ridge正则化可能纠正了两个特征之间的协方差问题。当我们用其他模型的形式将我们的数据分析推进的同时,我们可以继续visualizers来快速比较并且可视化我们的结果。
希望这个流程让你对怎样将Visualizers通过Scikit-Learn整合到机器学习中去有一个概念,并且给你启发让你将其运用到你的工作中!如果想要了解更多的有关怎样开始使用Yellowbrick的信息,请查看 模型选择教程 。然后你就在 Visualizers and API 上快速查看更多的特定visualizers了。
```python
```
Python Life

 浙公网安备 33010602011771号
浙公网安备 33010602011771号