MySQL基础 - 基于成本的优化
什么是成本
I/O成本
我们的表经常使用的MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中然后再操作。这个从磁盘到内存这个加载的过程损耗的时间称之为I/O成本。
CPU成本
读取以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称之为CPU成本。
对于InnoDB存储引擎来说,页是磁盘和内存之间交互的基本单位,设计MySQL的大叔规定读取一个页面花费的成本默认是1.0,读取以及检测一条记录是否符合搜索条件的成本默认是0.2。1.0、0.2这些数字称之为成本常数
单表查询的成本
CREATE TABLE single_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3) ) Engine=InnoDB CHARSET=utf8;
基于成本的优化步骤
SELECT * FROM single_table WHERE key1 IN ('a', 'b', 'c') AND key2 > 10 AND key2 < 1000 AND key3 > key2 AND key_part1 LIKE '%hello%' AND common_field = '123';
1. 根据搜索条件,找出所有可能使用的索引
上边的查询语句可能用到的索引,也就是possible keys只有idx_key1和idx_key2。
2. 计算全表扫描的代价
由于查询成本=I/O成本+CPU成本,所以计算全表扫描的代价需要两个信息:
聚簇索引占用的页面数 和 该表中的记录数
mysql> USE xiaohaizi; Database changed mysql> SHOW TABLE STATUS LIKE 'single_table'\G *************************** 1. row *************************** Name: single_table Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 9693 Avg_row_length: 163 Data_length: 1589248 Max_data_length: 0 Index_length: 2752512 Data_free: 4194304 Auto_increment: 10001 Create_time: 2018-12-10 13:37:23 Update_time: 2018-12-10 13:38:03 Check_time: NULL Collation: utf8_general_ci Checksum: NULL Create_options: Comment:
Rows
对于使用MyISAM存储引擎的表来说,该值是准确的,对于使用InnoDB存储引擎的表来说,该值是一个估计值。
Data_length
Data_length = 聚簇索引的页面数量 x 每个页面的大小(16*1024)
聚簇索引的页面数量 = 1589248 ÷ 16 ÷ 1024 = 97
I/O成本
97 x 1.0 + 1.1 = 98.1
//97指的是聚簇索引占用的页面数,1.0指的是加载一个页面的成本常数,后边的1.1是一个微调值,我们不用在意。
CPU成本:
9693 x 0.2 + 1.0 = 1939.6
//9693指的是统计数据中表的记录数,对于InnoDB存储引擎来说是一个估计值,0.2指的是访问一条记录所需的成本常数,后边的1.0是一个微调值,我们不用在意。
总成本:
98.1 + 1939.6 = 2037.7
综上所述,对于single_table的全表扫描所需的总成本就是2037.7。
3. 计算使用不同索引执行查询的代价
使用idx_key2执行查询的成本分析
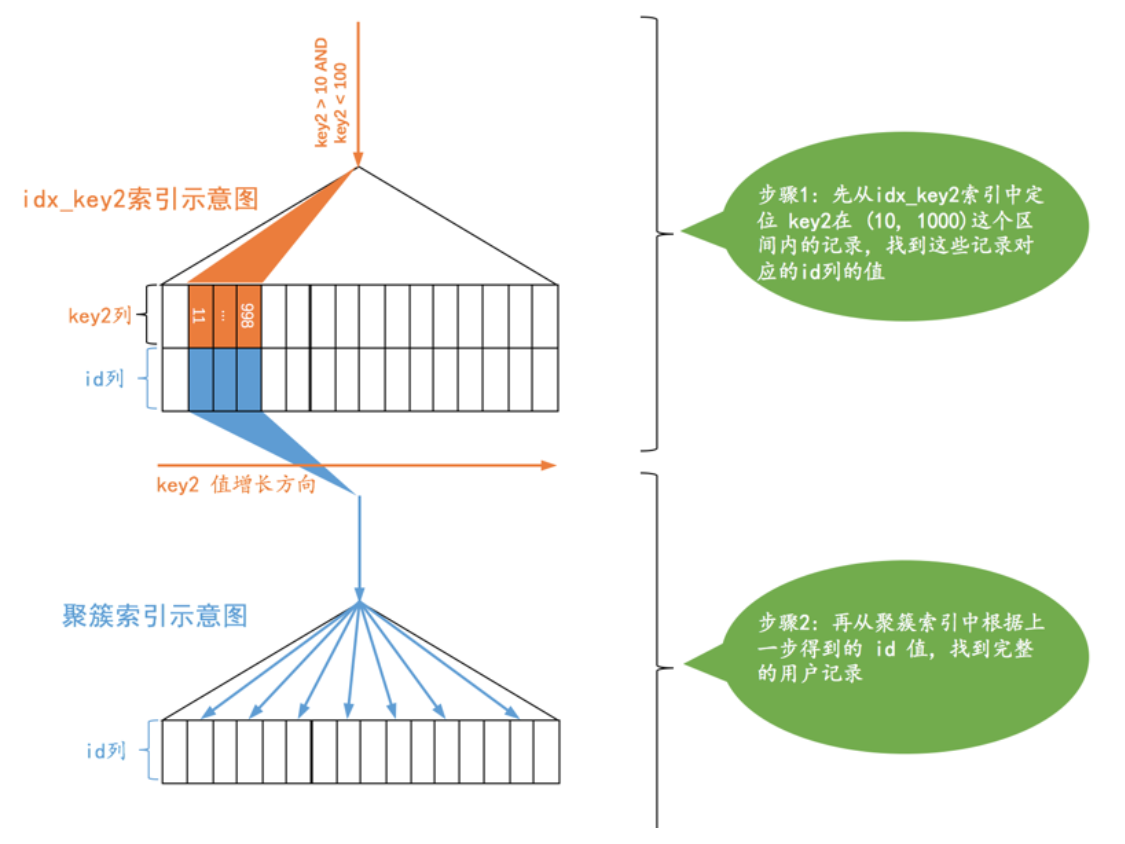
范围区间数量
不论某个范围区间的二级索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。本例中使用idx_key2的范围区间只有一个:(10, 1000),所以相当于访问这个范围区间的二级索引付出的I/O成本就是:
1 x 1.0 = 1.0
需要回表的记录数
步骤1:找到满足key2 > 10这个条件的第一条记录,我们把这条记录称之为区间最左记录
步骤2:找到满足key2 < 1000这个条件的最后一条记录,我们把这条记录称之为区间最右记录
步骤3:找到满足key2 > 10这个条件的第一条记录,我们把这条记录称之为区间最左记录
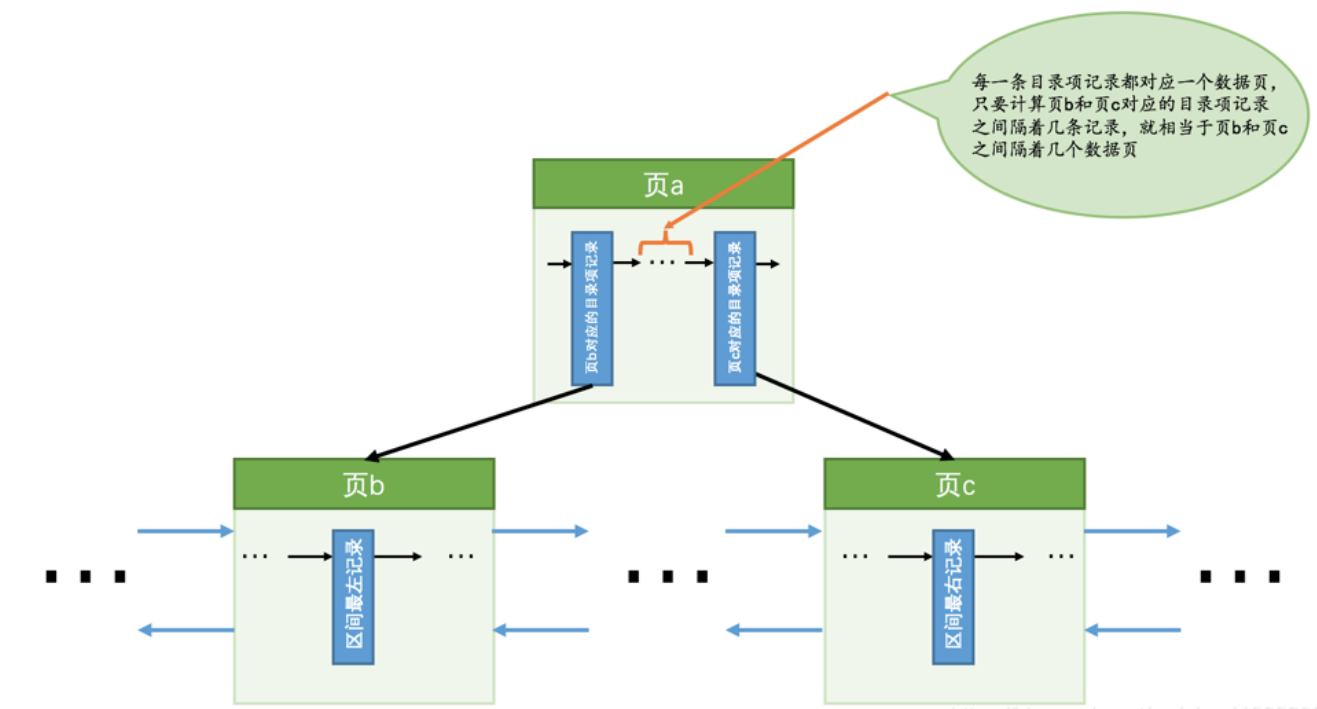
idx_key2在区间(10, 1000)之间大约有95条记录。
访问这个范围区间的二级索引付出的I/O成本就是: 1 x 1.0 = 1.0
回表操作带来的I/O成本就是:95 x 1.0 = 95.0
读取这95条二级索引记录需要付出的CPU成本就是:95 x 0.2 + 0.01 = 19.01
回表操作带来的CPU成本就是: 95 x 0.2 = 19.0
综上所述,使用idx_key2执行查询的总成本就是:
96.0 + 38.01 = 134.01
使用idx_key1执行查询的成本分析
I/O成本: 3.0 + 118 x 1.0 = 121.0 (范围区间的数量 + 预估的二级索引记录条数)
CPU成本:: 118 x 0.2 + 0.01 + 118 x 0.2 = 47.21 (读取二级索引记录的成本 + 读取并检测回表后聚簇索引记录的成本)
综上所述,使用idx_key1执行查询的总成本就是:
121.0 + 47.21 = 168.21
4.对比各种执行方案的代价,找出成本最低的那一个
全表扫描的成本:2037.7
使用idx_key2的成本:134.01
使用idx_key1的成本:168.21
所以当然选择idx_key2来执行查询喽。
基于索引统计数据的成本计算
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录。通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index dive。
当IN语句中的参数个数大于或等于系统变量eq_range_index_dive_limit的值的话,就不会使用index dive的方式计算各个单点区间对应的索引记录条数,而是使用索引统计数据。
索引统计数据的致命弱点就是不精确,得出的查询成本可能和实际执行成本相差较大。
ps:mysql5.7.3及之前版本,eq_range_index_dive_limit默认为10,之后的版本是200.
对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。
SHOW INDEX FROM 表名 查看索引统计数据。Cardinality 该列中不重复的得数量。一个值的重复次数 ≈ Rows ÷ Cardinality
基于索引统计数据的成本计算 成本 = 一个值的重复次数 *(IN语句中数量)
多表查询的成本
1. 条件过滤Condition filtering
两表连接查询来说,它的查询成本由下边两个部分构成:
- 单次查询驱动表的成本
- 多次查询被驱动表的成本(具体查询多少次取决于对驱动表查询的结果集中有多少条记录)
我们把查询驱动表得到的记录条数称为驱动表的扇出(fanout),显然驱动表的扇出值越小,对驱动表的查询次数就越小,连接查询成本就越低。当查询优化器想计算整个连接查询所需成本就需要计算驱动表的扇出值。
1. 如果使用全表扫描,那么计算驱动表扇出值需要猜测满足全部搜索条件的记录到底有多少条。
2. 如果使用索引来执行单表查询,那么计算驱动表扇出值时需要猜测除了满足形成扫描区间的搜索条件外,还满足其他搜索条件的记录有多少条。
MySQL把猜测的过程称为Condition filtering 条件过滤。
ps:
5.7之前版本中:全表扫描直接使用表中记录的数量作为扇出值;索引执行查询,就直接使用扫描区间中的记录条数作为扇出值。
5.7开始:引入条件过滤,就是还要猜一猜剩余那些搜索条件能把驱动表中的记录再过滤多少条,其实本质就是为了让成本估算更为准确。
2. 两表连接的成本分析
连接查询的成本计算公式: 连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 * 单次访问被驱动表的成本
对于外关联连接查询来讲:它们的驱动表是固定的,所以只需要考虑驱动表和被驱动表选择成本最低的访问方法就可以得到最优的查询方案。
对于内关联连接查询来讲,驱动表和被驱动表的位置是可以互换的,因此需要考虑两个方面的问题:
1. 当不同的表作为驱动表时,最终的查询成本可能不同,也就是需要考虑最优的表连接顺序。
2. 然后分别作为驱动表和被驱动表选择查询成本最低的访问方法。
连接查询的重点在于:1.尽量减少驱动表的扇出。 2. 访问被驱动表的成本要低。
ps: 如果可以被驱动表的连接列最好是该表的主键或者唯一二级索引,这样就可以把访问被驱动表的成本降至更低了。
3. 多表连接的成本分析
在分析多表连接的成本之前,首先要考虑多表连接可能会产生多少种顺序。
在N个表进行连接的时候,可能会产生N种连接排序,MySQL会逐一进行连接顺序下的查询成本比较。
* 提前结束某种连接顺序的成本评估:
MySQL在计算各种连接顺序的成本前,会先维护一个全局变量存储当前最小连接成本,如果分析某个连接顺序成本时已经超过当前连接最小成本则不再考虑。
* optimizer_search_depth
查询优化器执行的最大搜索深度。大于查询中关系数的值会产生更好的查询计划,但编译查询需要更长的时间。小于关系中表数的值会导致更快的优化,但可能会产生非常糟糕的查询计划。如果设置为 0,系统会自动选取一个合理的值. 当它设置为 0 时,优化器会尝试选择一个合理的搜索深度。目前,它通过将搜索深度设置为查询中使用的表数来实现这一点,最大值为 7。
启发式规则 :通过系统变量optimizer_prune_level决定是否开启,MySQL设计者根据经验设计了一些规则,凡是不满足这些规则的 内连接 顺序不会进行成本分析
* optimizer_prune_level
该optimizer_prune_level 变量告诉优化器根据对每个表访问的行数的估计跳过某些计划。我们的经验表明,这种“有根据的猜测”很少会错过最佳计划,并且可能会大大减少查询编译时间。这就是optimizer_prune_level=1默认情况下此选项启用 ( ) 的原因。但是,如果您认为优化器错过了更好的查询计划,则可以关闭此选项(optimizer_prune_level=0) 的风险是查询编译可能需要更长的时间。请注意,即使使用这种启发式方法,优化器仍会探索大致呈指数级数量的计划。
调节成本常数
mysql.server_cost表
成本常数名称默认值描述
disk_temptable_create_cost40.0创建基于磁盘的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。
disk_temptable_row_cost1.0向基于磁盘的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于磁盘的临时表。
key_compare_cost0.1两条记录做比较操作的成本,多用在排序操作上,如果增大这个值的话会提升filesort的成本,让优化器可能更倾向于使用索引完成排序而不是filesort
memory_temptable_create_cost2.0创建基于内存的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
memory_temptable_row_cost0.2向基于内存的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
row_evaluate_cost0.2这个就是我们之前一直使用的检测一条记录是否符合搜索条件的成本,增大这个值可能让优化器更倾向于使用索引而不是直接全表扫描。
mysql.engine_cost表
成本常数名称默认值描述
io_block_read_cost 默认值1.0从
描述:磁盘上读取一个块对应的成本。请注意我使用的是块,而不是页这个词儿。对于InnoDB存储引擎来说,一个页就是一个块,不过对于MyISAM存储引擎来说,默认是以4096字节作为一个块的。增大这个值会加重I/O成本,可能让优化器更倾向于选择使用索引执行查询而不是执行全表扫描。
memory_block_read_cost 默认值1.0
描述:与上一个参数类似,只不过衡量的是从内存中读取一个块对应的成本。
总结:
在MySQL中一个查询的成本是由I/O成本和CPU成本组成的。对于InnoDB存储引擎来说,读取一个页面的I/O成本默认是1.0,读取以及检测一条记录是否符合搜索条件的成本默认是0.2.
在单表查询中,优化器生成执行计划的步骤一般如下:
1. 根据搜索条件找出所有可能使用的索引。
2. 计算全表扫描的代价。
3. 计算使用不同索引执行的代价。
4. 对比各种执行方案的代价,找出成本最低的方案。
在优化器生成执行计划的过程中,需要依赖一些数据。这些数据可能是使用下面两种方式得到的:
a) index dive: 通过直接访问索引对应的B+树来获取数据。
b) 索引统计数据: 直接依赖对表或者索引的统计数据。
为了更精准的统计连接查询的成本,提出了条件过滤的概念,也就是采用某些规则来预测驱动表的扇出值。
对于内连接来说,为了生成成本最低的执行计划,需要考虑两方面的事情:
a) 选择最优的表连接顺序。
b) 为驱动表和被驱动表选择成本最低的访问方法。
我们可以通过手动修改mysql数据库下的engine_cost表或者server_cost表中的某些成本常数,更精确的控制在生成执行计划时的成本计算过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号