索引、事务、锁相关知识点总结
索引、事务、锁相关知识点总结
当时认真的学过,现在也忘的差不多了。
一、索引
1.聚簇索引(主键使用)2.二级/辅助索引
假设我们有一张消息表(msg),里面有3个字段。假设id是主键,token是非唯一索引,message没有索引。innodb对于主键使用了聚簇索引,这是一种数据存储方式,表数据是和主键一起存储,主键索引的叶结点存储行数据。对于普通索引,其叶子节点存储的是主键值。如图:

二、锁与事务
共享锁【S锁】
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁【X锁】
又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
事务隔离级别的概念:1)未提交读(Read uncommitted);2)已提交读(Read committed(RC));3)可重复读(Repeatable read(RR));4)可串行化(Serializable)。
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
我们较常使用的是RC和RR。
提交读(RC):只能读取到已经提交的数据。针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。(下文会介绍到)
可重复读(RR):在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
三、加锁实现情况分析
常见的加锁情况:
组合一:id列是主键,RC隔离级别
组合二:id列是二级唯一索引,RC隔离级别
组合三:id列是二级非唯一索引,RC隔离级别
组合四:id列上没有索引,RC隔离级别
组合五:id列是主键,RR隔离级别
组合六:id列是二级唯一索引,RR隔离级别
组合七:id列是二级非唯一索引,RR隔离级别
组合八:id列上没有索引,RR隔离级别
1.组合一:id主键+RC
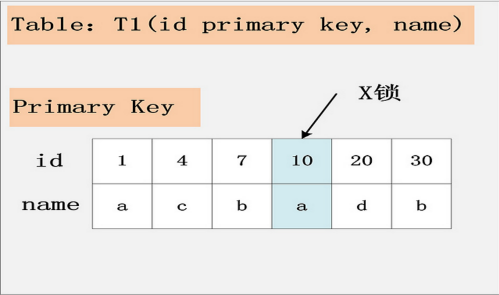
这个组合,是最简单,最容易分析的组合。id是主键,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上X锁即可。如下图所示:
结论:id是主键时,此SQL只需要在id=10这条记录上加X锁即可。
2.组合二:id唯一索引+RC
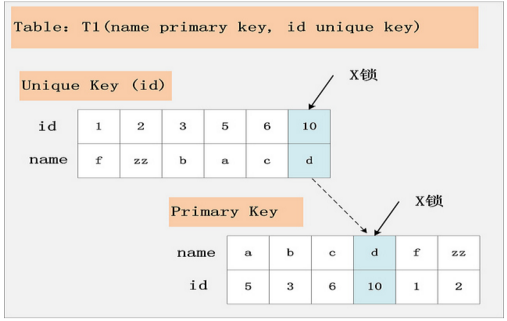
这个组合,id不是主键,而是一个Unique的二级索引键值。那么在RC隔离级别下,delete from t1 where id = 10; 需要加什么锁呢?见下图:
此组合中,id是unique索引,而主键是name列。此时,加锁的情况由于组合一有所不同。由于id是unique索引,因此delete语句会选择走id列的索引进行where条件的过滤,在找到id=10的记录后,首先会将unique索引上的id=10索引记录加上X锁,同时,会根据读取到的name列,回主键索引(聚簇索引),然后将聚簇索引上的name = ‘d’ 对应的主键索引项加X锁。为什么聚簇索引上的记录也要加锁?试想一下,如果并发的一个SQL,是通过主键索引来更新:update t1 set id = 100 where name = ‘d’; 此时,如果delete语句没有将主键索引上的记录加锁,那么并发的update就会感知不到delete语句的存在,违背了同一记录上的更新/删除需要串行执行的约束。
结论:若id列是unique列,其上有unique索引。那么SQL需要加两个X锁,一个对应于id unique索引上的id = 10的记录,另一把锁对应于聚簇索引上的[name=’d’,id=10]的记录。
3.组合三:id非唯一索引+RC
隔离级别仍旧是RC不变,但是id列上的约束又降低了,id列不再唯一,只有一个普通的索引。假设delete from t1 where id = 10; 语句,仍旧选择id列上的索引进行过滤where条件,那么此时会持有哪些锁?同样见下图:
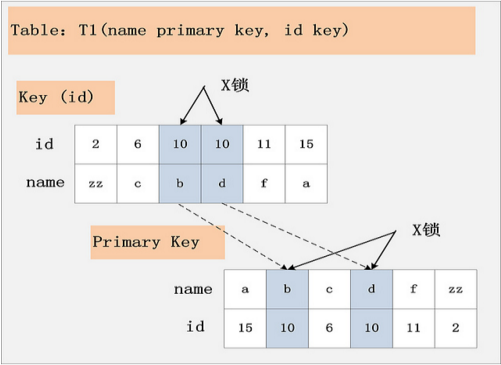
根据此图,可以看到,首先,id列索引上,满足id = 10查询条件的记录,均已加锁。同时,这些记录对应的主键索引上的记录也都加上了锁。与组合二唯一的区别在于,组合二最多只有一个满足等值查询的记录,而组合三会将所有满足查询条件的记录都加锁。
结论:若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
4.组合四:id无索引+RC
id列上没有索引,where id = 10;这个过滤条件,没法通过索引进行过滤,那么只能走全表扫描做过滤。如下图:
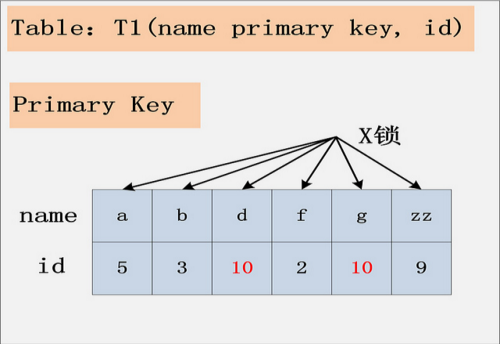
由于id列上没有索引,因此只能走聚簇索引,进行全部扫描。从图中可以看到,满足删除条件的记录有两条,但是,聚簇索引上所有的记录,都被加上了X锁。无论记录是否满足条件,全部被加上X锁。既不是加表锁,也不是在满足条件的记录上加行锁。
结论:若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
注:2PL:传统RDBMS加锁的一个原则,就是2PL (二阶段锁):Two-Phase Locking。相对而言,2PL比较容易理解,说的是锁操作分为两个阶段:加锁阶段与解锁阶段,并且保证加锁阶段与解锁阶段不相交。以MySQL为例,来简单看看2PL在MySQL中的实现。

从上图可以看出,2PL就是将加锁/解锁分为两个完全不相交的阶段。加锁阶段:只加锁,不放锁。解锁阶段:只放锁,不加锁。
5.组合五:id主键+RR
id列是主键列,Repeatable Read隔离级别,针对delete from t1 where id = 10; 这条SQL,加锁与组合一:[id主键,Read Committed]一致。
6.组合六:id唯一索引+RR
与组合五类似,组合六的加锁,与组合二:[id唯一索引,Read Committed]一致。两个X锁,id唯一索引满足条件的记录上一个,对应的聚簇索引上的记录一个。
7.组合七:id非唯一索引+RR
RC隔离级别允许幻读,而RR隔离级别,不允许存在幻读。但是在组合五、组合六中,加锁行为又是与RC下的加锁行为完全一致。那么RR隔离级别下,如何防止幻读呢?问题的答案,就在组合七中揭晓。
组合七,Repeatable Read隔离级别,id上有一个非唯一索引,执行delete from t1 where id = 10; 假设选择id列上的索引进行条件过滤,最后的加锁行为,是怎么样的呢?同样看下面这幅图:
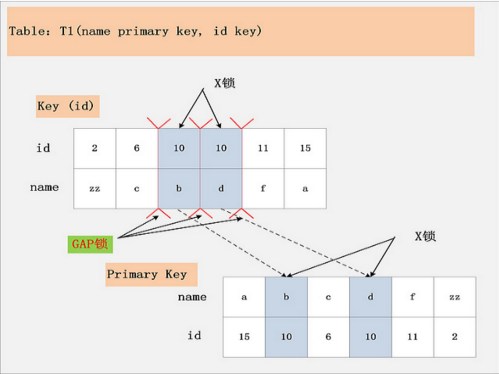
此图,相对于组合三:[id列上非唯一锁,Read Committed]看似相同,其实却有很大的区别。最大的区别在于,这幅图中多了一个GAP锁,而且GAP锁看起来也不是加在记录上的,倒像是加载两条记录之间的位置,GAP锁有何用?
其实这个多出来的GAP锁,就是RR隔离级别,相对于RC隔离级别,不会出现幻读的关键。确实,GAP锁锁住的位置,也不是记录本身,而是两条记录之间的GAP。所谓幻读,就是同一个事务,连续做两次当前读 (例如:select * from t1 where id = 10 for update;),那么这两次当前读返回的是完全相同的记录 (记录数量一致,记录本身也一致),第二次的当前读,不会比第一次返回更多的记录 (幻象)。
如何保证两次当前读返回一致的记录,那就需要在第一次当前读与第二次当前读之间,其他的事务不会插入新的满足条件的记录并提交。为了实现这个功能,GAP锁应运而生。
如图中所示,有哪些位置可以插入新的满足条件的项 (id = 10),考虑到B+树索引的有序性,满足条件的项一定是连续存放的。记录[6,c]之前,不会插入id=10的记录;[6,c]与[10,b]间可以插入[10, aa];[10,b]与[10,d]间,可以插入新的[10,bb],[10,c]等;[10,d]与[11,f]间可以插入满足条件的[10,e],[10,z]等;而[11,f]之后也不会插入满足条件的记录。因此,为了保证[6,c]与[10,b]间,[10,b]与[10,d]间,[10,d]与[11,f]不会插入新的满足条件的记录,MySQL选择了用GAP锁,将这三个GAP给锁起来。
Insert操作,如insert [10,aa],首先会定位到[6,c]与[10,b]间,然后在插入前,会检查这个GAP是否已经被锁上,如果被锁上,则Insert不能插入记录。因此,通过第一遍的当前读,不仅将满足条件的记录锁上 (X锁),与组合三类似。同时还是增加3把GAP锁,将可能插入满足条件记录的3个GAP给锁上,保证后续的Insert不能插入新的id=10的记录,也就杜绝了同一事务的第二次当前读,出现幻象的情况。
结论:Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
8.组合八:id无索引+RR
组合八,Repeatable Read隔离级别下的最后一种情况,id列上没有索引。此时SQL:delete from t1 where id = 10; 没有其他的路径可以选择,只能进行全表扫描。最终的加锁情况,如下图所示:
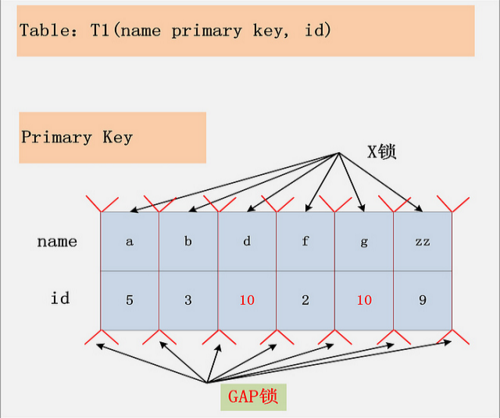
如图,这是一个很恐怖的现象。首先,聚簇索引上的所有记录,都被加上了X锁。其次,聚簇索引每条记录间的间隙(GAP),也同时被加上了GAP锁。这个示例表,只有6条记录,一共需要6个记录锁,7个GAP锁。试想,如果表上有1000万条记录呢?
在这种情况下,这个表上,除了不加锁的快照度,其他任何加锁的并发SQL,均不能执行,不能更新,不能删除,不能插入,全表被锁死。
结论:在Repeatable Read隔离级别下,如果进行全表扫描的当前读,那么会锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。
四、死锁原理与分析
下面,来看看两个死锁的例子 (一个是两个Session的两条SQL产生死锁;另一个是两个Session的一条SQL,产生死锁):


上面的两个死锁用例
第一个非常好理解,也是最常见的死锁,每个事务执行两条SQL,分别持有了一把锁,然后加另一把锁,产生死锁。
第二个用例,虽然每个Session都只有一条语句,仍旧会产生死锁。要分析这个死锁,首先必须用到本文前面提到的MySQL加锁的规则。针对Session 1,从name索引出发,读到的[hdc, 1],[hdc, 6]均满足条件,不仅会加name索引上的记录X锁,而且会加聚簇索引上的记录X锁,加锁顺序为先[1,hdc,100],后[6,hdc,10]。而Session 2,从pubtime索引出发,[10,6],[100,1]均满足过滤条件,同样也会加聚簇索引上的记录X锁,加锁顺序为[6,hdc,10],后[1,hdc,100]。发现没有,跟Session 1的加锁顺序正好相反,如果两个Session恰好都持有了第一把锁,请求加第二把锁,死锁就发生了。
结论:死锁的发生与否,并不在于事务中有多少条SQL语句,死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。而使用本文上面提到的,分析MySQL每条SQL语句的加锁规则,分析出每条语句的加锁顺序,然后检查多个并发SQL间是否存在以相反的顺序加锁的情况,就可以分析出各种潜在的死锁情况,也可以分析出线上死锁发生的原因。
Nice to see you all!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号