《Java架构师的第一性原理》23Java基础之Java核心技术36讲(极客时间 杨晓峰)
第1讲 | 谈谈你对Java平台的理解?
1)今天我要问你的问题是,谈谈你对Java平台的理解?“Java是解释执行”,这句话正确吗?
2)典型回答
Java本身是一种面向对象的语言,最显著的特性有两个方面,一是所谓的“书写一次,到处运行”(Write once, run anywhere),能够非常容易地获得跨平台能力;另外就是垃圾收集(GC, Garbage Collection),Java通过垃圾收集器(Garbage Collector)回收分配内存,大部分情况下,程序员不需要自己操心内存的分配和回收。
对于“Java是解释执行”这句话,这个说法不太准确。我们开发的Java的源代码,首先通过Javac编译成为字节码(bytecode),然后,在运行时,通过 Java虚拟机(JVM)内嵌的 解释器将字节码转换成为最终的机器码。但是常见的JVM,比如我们大多数情况使用的Oracle JDK提供的Hotspot JVM,都提供了JIT(Just-In-Time)编译器,也就是通常所说的 动态编译器,JIT能够在运行时将热点代码编译成机器码,这种情况下部分热点代码就属于编译执行,而不是解释执行了。
3)考点分析
4)知识拓展
对于Java平台的理解,可以从很多方面简明扼要地谈一下,例如:Java语言特性,包括泛型、Lambda等语言特性;基础类库,包括集合、IO/NIO、网络、并发、安全 等基础类库。对于我们日常工作应用较多的类库,面试前可以系统化总结一下,有助于临场发挥。
第2讲 | Exception和Error有什么区别?
1)今天我要问你的问题是,请对比Exception和Error,另外,运行时异常与一般异常有什么区别?
2)典型回答
Exception和Error都是继承了Throwable类,在Java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
Exception和Error体现了Java平台设计者对不同异常情况的分类。
Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error是指在正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如OutOfMemoryError之类,都是Error的子类。
Exception又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。前面我介绍的不可查 的Error,是Throwable不是Exception。
不检查异常就是所谓的运行时异常,类似 NullPointerException、ArrayIndexOutOfBoundsException之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕 获,并不会在编译期强制要求。
第3讲 | 谈谈final、finally、 finalize有什么不同?
1)今天,我要问你的是一个经典的Java基础题目,谈谈final、finally、 finalize有什么不同?
2)典型回答
final可以用来修饰类、方法、变量,分别有不同的意义,fnal修饰的class代表不可以继承扩展,fnal的变量是不可以修改的,而fnal的方法也是不可以重写的(override)。
finally则是Java保证重点代码一定要被执行的一种机制。我们可以使用try-fnally或者try-catch-fnally来进行类似关闭JDBC连接、保证unlock锁等动作。
finalize是基础类java.lang.Object的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收。fnalize机制现在已经不推荐使用,并且在JDK 9开始被标记 为deprecated。
3)考点分析
4)知识拓展
(1)注意,fnal不是immutable!
(2)fnalize真的那么不堪?
(3)有什么机制可以替换fnalize吗?
Java平台目前在逐步使用java.lang.ref.Cleaner来替换掉原有的fnalize实现。Cleaner的实现利用了幻象引用(PhantomReference),这是一种常见的所谓post-mortem清理 机制。我会在后面的专栏系统介绍Java的各种引用,利用幻象引用和引用队列,我们可以保证对象被彻底销毁前做一些类似资源回收的工作,比如关闭文件描述符(操作系统有限的 资源),它比fnalize更加轻量、更加可靠。
吸取了fnalize里的教训,每个Cleaner的操作都是独立的,它有自己的运行线程,所以可以避免意外死锁等问题。
第4讲 | 强引用、软引用、弱引用、幻象引用有什么区别?
在Java语言中,除了原始数据类型的变量,其他所有都是所谓的引用类型,指向各种不同的对象,理解引用对于掌握Java对象生命周期和JVM内部相关机制非常有帮助。
1)今天我要问你的问题是,强引用、软引用、弱引用、幻象引用有什么区别?具体使用场景是什么?
2)典型回答
不同的引用类型,主要体现的是对象不同的可达性(reachable)状态和对垃圾收集的影响。
所谓强引用("Strong" Reference),就是我们最常见的普通对象引用,只要还有强引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰这种对象。对于一个普通的对 象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为null,就是可以被垃圾收集的了,当然具体回收时机还是要看垃圾收集策略。
软引用(SoftReference),是一种相对强引用弱化一些的引用,可以让对象豁免一些垃圾收集,只有当JVM认为内存不足时,才会去试图回收软引用指向的对象。JVM会确保在抛出OutOfMemoryError之前,清理软引用指向的对象。软引用通常用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
弱引用(WeakReference )并不能使对象豁免垃圾收集,仅仅是提供一种访问在弱引用状态下对象的途径。这就可以用来构建一种没有特定约束的关系,比如,维护一种非强制性 的映射关系,如果试图获取时对象还在,就使用它,否则重现实例化。它同样是很多缓存实现的选择。
对于幻象引用,有时候也翻译成虚引用,你不能通过它访问对象。幻象引用仅仅是提供了一种确保对象被fnalize以后,做某些事情的机制,比如,通常用来做所谓的Post- Mortem清理机制,我在专栏上一讲中介绍的Java平台自身Cleaner机制等,也有人利用幻象引用监控对象的创建和销毁。
3)考点分析
4)知识拓展
(1)对象可达性状态流转分析
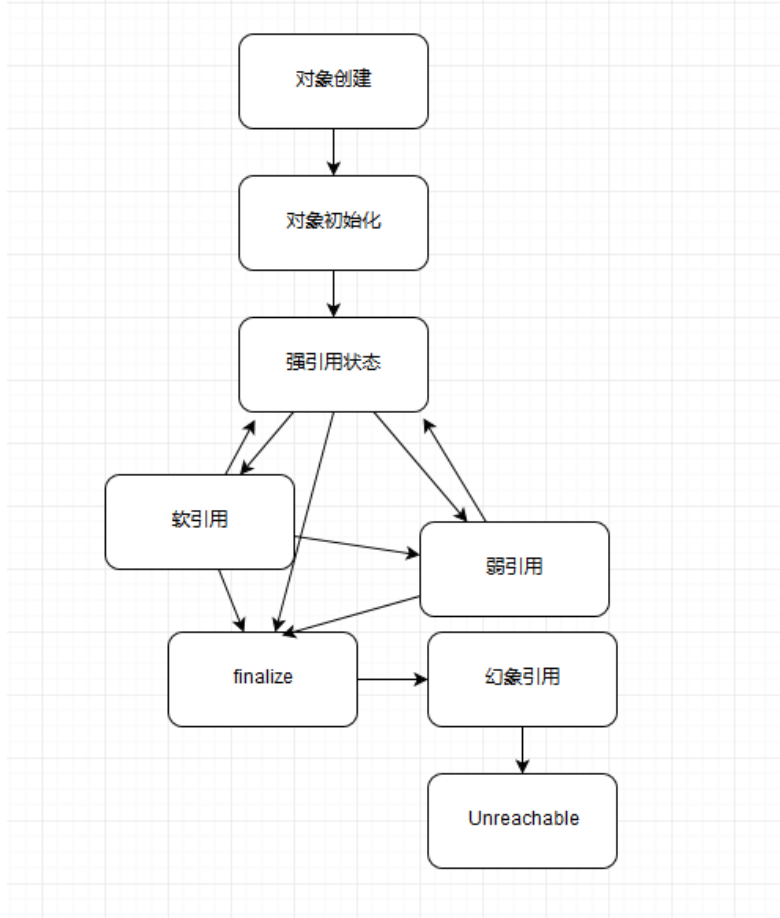
我来解释一下上图的具体状态,这是Java定义的不同可达性级别(reachability level),具体如下:
- 强可达(Strongly Reachable),就是当一个对象可以有一个或多个线程可以不通过各种引用访问到的情况。比如,我们新创建一个对象,那么创建它的线程对它就是强可达。
- 软可达(Softly Reachable),就是当我们只能通过软引用才能访问到对象的状态。
- 弱可达(Weakly Reachable),类似前面提到的,就是无法通过强引用或者软引用访问,只能通过弱引用访问时的状态。这是十分临近fnalize状态的时机,当弱引用被清除的 时候,就符合fnalize的条件了。
- 幻象可达(Phantom Reachable),上面流程图已经很直观了,就是没有强、软、弱引用关联,并且fnalize过了,只有幻象引用指向这个对象的时候。
- 当然,还有一个最后的状态,就是不可达(unreachable),意味着对象可以被清除了。
判断对象可达性,是JVM垃圾收集器决定如何处理对象的一部分考虑。
所有引用类型,都是抽象类java.lang.ref.Reference 的子类,你可能注意到它提供了get()方法:

除了幻象引用(因为get永远返回null),如果对象还没有被销毁,都可以通过get方法获取原有对象。这意味着,利用软引用和弱引用,我们可以将访问到的对象,重新指向强引用,也就是人为的改变了对象的可达性状态!这也是为什么我在上面图里有些地方画了双向箭头。
所以,对于软引用、弱引用之类,垃圾收集器可能会存在二次确认的问题,以保证处于弱引用状态的对象,没有改变为强引用。
但是,你觉得这里有没有可能出现什么问题呢?
不错,如果我们错误的保持了强引用(比如,赋值给了static变量),那么对象可能就没有机会变回类似弱引用的可达性状态了,就会产生内存泄漏。所以,检查弱引用指向对象是 否被垃圾收集,也是诊断是否有特定内存泄漏的一个思路,如果我们的框架使用到弱引用又怀疑有内存泄漏,就可以从这个角度检查。
(2)引用队列(ReferenceQueue)使用
谈到各种引用的编程,就必然要提到引用队列。我们在创建各种引用并关联到响应对象时,可以选择是否需要关联引用队列,JVM会在特定时机将引用enqueue到队列里,我们可以 从队列里获取引用(remove方法在这里实际是有获取的意思)进行相关后续逻辑。尤其是幻象引用,get方法只返回null,如果再不指定引用队列,基本就没有意义了。
看看下面的 示例代码。利用引用队列,我们可以在对象处于相应状态时(对于幻象引用,就是前面说的被fnalize了,处于幻象可达状态),执行后期处理逻辑。
Object counter = new Object(); ReferenceQueue refQueue = new ReferenceQueue<>(); PhantomReference<Object> p = new PhantomReference<>(counter, refQueue); counter = null; Sysem.gc(); try { // Remove是一个阻塞方法,可以指定timeout,或者选择一直阻塞 Reference<Object> ref = refQueue.remove(1000L); if (ref != null) { // do something } } catch (InterruptedException e) { // Handle it }
(3)显式地影响软引用垃圾收集
前面泛泛提到了引用对垃圾收集的影响,尤其是软引用,到底JVM内部是怎么处理它的,其实并不是非常明确。那么我们能不能使用什么方法来影响软引用的垃圾收集呢?
答案是有的。软引用通常会在最后一次引用后,还能保持一段时间,默认值是根据堆剩余空间计算的(以M bytes为单位)。从Java 1.3.1开始,提供了- XX:SoftRefLRUPolicyMSPerMB 参数,我们可以以毫秒(milliseconds)为单位设置。比如,下面这个示例就是设置为3秒(3000毫秒)。
-XX:SoftRefLRUPolicyMSPerMB=3000
这个剩余空间,其实会受不同JVM模式影响,对于Client模式,比如通常的Windows 32 bit JDK,剩余空间是计算当前堆里空闲的大小,所以更加倾向于回收;而对于server模 式JVM,则是根据-Xmx指定的最大值来计算。
本质上,这个行为还是个黑盒,取决于JVM实现,即使是上面提到的参数,在新版的JDK上也未必有效,另外Client模式的JDK已经逐步退出历史舞台。所以在我们应用时,可以参 考类似设置,但不要过于依赖它。
(4)诊断JVM引用情况
如果你怀疑应用存在引用(或fnalize)导致的回收问题,可以有很多工具或者选项可供选择,比如HotSpot JVM自身便提供了明确的选项(PrintReferenceGC)去获取相关信 息,我指定了下面选项去使用JDK 8运行一个样例应用:
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintReferenceGC
这是JDK 8使用ParrallelGC收集的垃圾收集日志,各种引用数量非常清晰。
0.403: [GC (Allocation Failure) 0.871: [SoftReference, 0 refs, 0.0000393 secs]0.871: [WeakReference, 8 refs, 0.0000138 secs]0.871: [FinalReference, 4 refs, 0.0000094 secs]0.871: [PhantomReference, 0 refs, 0 refs, 0.0000085 secs]0.871: [JNI Weak Reference, 0.0000071 secs][PSYoungGen: 76272K->10720K(141824K)] 128286K->128422K(316928K), 0.4683919 secs] [Times: user=1.17 sys=0.03, real=0.47 secs]
注意:JDK 9对JVM和垃圾收集日志进行了广泛的重构,类似PrintGCTimeStamps和PrintReferenceGC已经不再存在,我在专栏后面的垃圾收集主题里会更加系统的阐述。
(5)Reachability Fence
除了我前面介绍的几种基本引用类型,我们也可以通过底层API来达到强引用的效果,这就是所谓的设置reachability fence。
为什么需要这种机制呢?考虑一下这样的场景,按照Java语言规范,如果一个对象没有指向强引用,就符合垃圾收集的标准,有些时候,对象本身并没有强引用,但是也许它的部分 属性还在被使用,这样就导致诡异的问题,所以我们需要一个方法,在没有强引用情况下,通知JVM对象是在被使用的。说起来有点绕,我们来看看Java 9中提供的案例。
在Java 9之前,实现类似类似功能相对比较繁琐,有的时候需要采取一些比较隐晦的小技巧。幸好,java.lang.ref.Reference给我们提供了新方法,它是JEP 193: Variable Handles的一部分,将Java平台底层的一些能力暴露出来:
static void reachabilityFence(Object ref)
在JDK源码中,reachabilityFence大多使用在Executors或者类似新的HTTP/2客户端代码中,大部分都是异步调用的情况。编程中,可以按照上面这个例子,将需 要reachability保障的代码段利用try-fnally包围起来,在fnally里明确声明对象强可达。
第5讲 | String、StringBufer、StringBuilder有什么区别?
1)今天我要问你的问题是,理解Java的字符串,String、StringBufer、StringBuilder有什么区别?
2)典型回答
String是Java语言非常基础和重要的类,提供了构造和管理字符串的各种基本逻辑。它是典型的Immutable类,被声明成为fnal class,所有属性也都是fnal的。也由于它的不可 变性,类似拼接、裁剪字符串等动作,都会产生新的String对象。由于字符串操作的普遍性,所以相关操作的效率往往对应用性能有明显影响。
StringBufer是为解决上面提到拼接产生太多中间对象的问题而提供的一个类,我们可以用append或者add方法,把字符串添加到已有序列的末尾或者指定位置。StringBufer本 质是一个线程安全的可修改字符序列,它保证了线程安全,也随之带来了额外的性能开销,所以除非有线程安全的需要,不然还是推荐使用它的后继者,也就是StringBuilder。
StringBuilder是Java 1.5中新增的,在能力上和StringBufer没有本质区别,但是它去掉了线程安全的部分,有效减小了开销,是绝大部分情况下进行字符串拼接的首选。
3)考点分析
第6讲 | 动态代理是基于什么原理?
1)今天我要问你的问题是,谈谈Java反射机制,动态代理是基于什么原理?
2)典型回答
反射机制是Java语言提供的一种基础功能,赋予程序在运行时自省(introspect,官方用语)的能力。通过反射我们可以直接操作类或者对象,比如获取某个对象的类定义,获取类 声明的属性和方法,调用方法或者构造对象,甚至可以运行时修改类定义。
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装RPC调用、面向切面的编程(AOP)。
实现动态代理的方式很多,比如JDK自身提供的动态代理,就是主要利用了上面提到的反射机制。还有其他的实现方式,比如利用传说中更高性能的字节码操作机制,类
似ASM、cglib(基于ASM)、Javassist等。
3)考点分析
4)知识拓展
(1)反射机制及其演进
对于Java语言的反射机制本身,如果你去看一下java.lang或java.lang.refect包下的相关抽象,就会有一个很直观的印象了。Class、Field、Method、Constructor等,这些完全 就是我们去操作类和对象的元数据对应。反射各种典型用例的编程,相信有太多文章或书籍进行过详细的介绍,我就不再赘述了,至少你需要掌握基本场景编程,这里是官方提供的 参考文档:https://docs.oracle.com/javase/tutorial/refect/index.html 。
关于反射,有一点我需要特意提一下,就是反射提供的AccessibleObject.setAccessible(boolean fag)。它的子类也大都重写了这个方法,这里的所谓accessible可以理解成修饰 成员的public、protected、private,这意味着我们可以在运行时修改成员访问限制!
setAccessible的应用场景非常普遍,遍布我们的日常开发、测试、依赖注入等各种框架中。比如,在O/R Mapping框架中,我们为一个Java实体对象,运行时自动生 成setter、getter的逻辑,这是加载或者持久化数据非常必要的,框架通常可以利用反射做这个事情,而不需要开发者手动写类似的重复代码。
另一个典型场景就是绕过API访问控制。我们日常开发时可能被迫要调用内部API去做些事情,比如,自定义的高性能NIO框架需要显式地释放DirectBufer,使用反射绕开限制是一 种常见办法。
但是,在Java 9以后,这个方法的使用可能会存在一些争议,因为Jigsaw项目新增的模块化系统,出于强封装性的考虑,对反射访问进行了限制。Jigsaw引入了所谓Open的概念, 只有当被反射操作的模块和指定的包对反射调用者模块Open,才能使用setAccessible;否则,被认为是不合法(illegal)操作。如果我们的实体类是定义在模块里面,我们需要在 模块描述符中明确声明:
因为反射机制使用广泛,根据社区讨论,目前,Java 9仍然保留了兼容Java 8的行为,但是很有可能在未来版本,完全启用前面提到的针对setAccessible的限制,即只有当被反射 操作的模块和指定的包对反射调用者模块Open,才能使用setAccessible,我们可以使用下面参数显式设置。
(2)动态代理
第7讲 | int和Integer有什么区别?
1)今天我要问你的问题是,int和Integer有什么区别?谈谈Integer的值缓存范围。
2)典型回答
int是我们常说的整形数字,是Java的8个原始数据类型(Primitive Types,boolean、byte 、short、char、int、foat、double、long)之一。Java语言虽然号称一切都是对象, 但原始数据类型是例外。
Integer是int对应的包装类,它有一个int类型的字段存储数据,并且提供了基本操作,比如数学运算、int和字符串之间转换等。在Java 5中,引入了自动装箱和自动拆箱功能 (boxing/unboxing),Java可以根据上下文,自动进行转换,极大地简化了相关编程。
关于Integer的值缓存,这涉及Java 5中另一个改进。构建Integer对象的传统方式是直接调用构造器,直接new一个对象。但是根据实践,我们发现大部分数据操作都是集中在有 限的、较小的数值范围,因而,在Java 5中新增了静态工厂方法valueOf,在调用它的时候会利用一个缓存机制,带来了明显的性能改进。按照Javadoc,这个值默认缓存 是-128到127之间。
3)考点分析
第8讲 | 对比Vector、ArrayList、LinkedList有何区别?
1)今天我要问你的是有关集合框架方面的问题,对比Vector、ArrayList、LinkedList有何区别?
第9讲 | 对比Hashtable、HashMap、TreeMap有什么不同?
1)今天我要问你的问题是,对比Hashtable、HashMap、TreeMap 有什么不同?谈谈你对HashMap的掌握。
第10讲 | 如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全?
1)今天我要问你的问题是,如何保证容器是线程安全的?ConcurrentHashMap如何实现高效地线程安全?
2)典型回答
3)考点分析
4)知识拓展
我们再来看看ConcurrentHashMap是如何设计实现的,为什么它能大大提高并发效率。
首先,我这里强调,ConcurrentHashMap的设计实现其实一直在演化,比如在Java 8中就发生了非常大的变化(Java 7其实也有不少更新),所以,我这里将比较分析结构、实现机 制等方面,对比不同版本的主要区别。
早期ConcurrentHashMap,其实现是基于:
- 分离锁,也就是将内部进行分段(Segment),里面则是HashEntry的数组,和HashMap类似,哈希相同的条目也是以链表形式存放。
- HashEntry内部使用volatile的value字段来保证可见性,也利用了不可变对象的机制以改进利用Unsafe提供的底层能力,比如volatile access,去直接完成部分操作,以最优化 性能,毕竟Unsafe中的很多操作都是JVM intrinsic优化过的。
你可以参考下面这个早期ConcurrentHashMap内部结构的示意图,其核心是利用分段设计,在进行并发操作的时候,只需要锁定相应段,这样就有效避免了类似Hashtable整体同 步的问题,大大提高了性能。
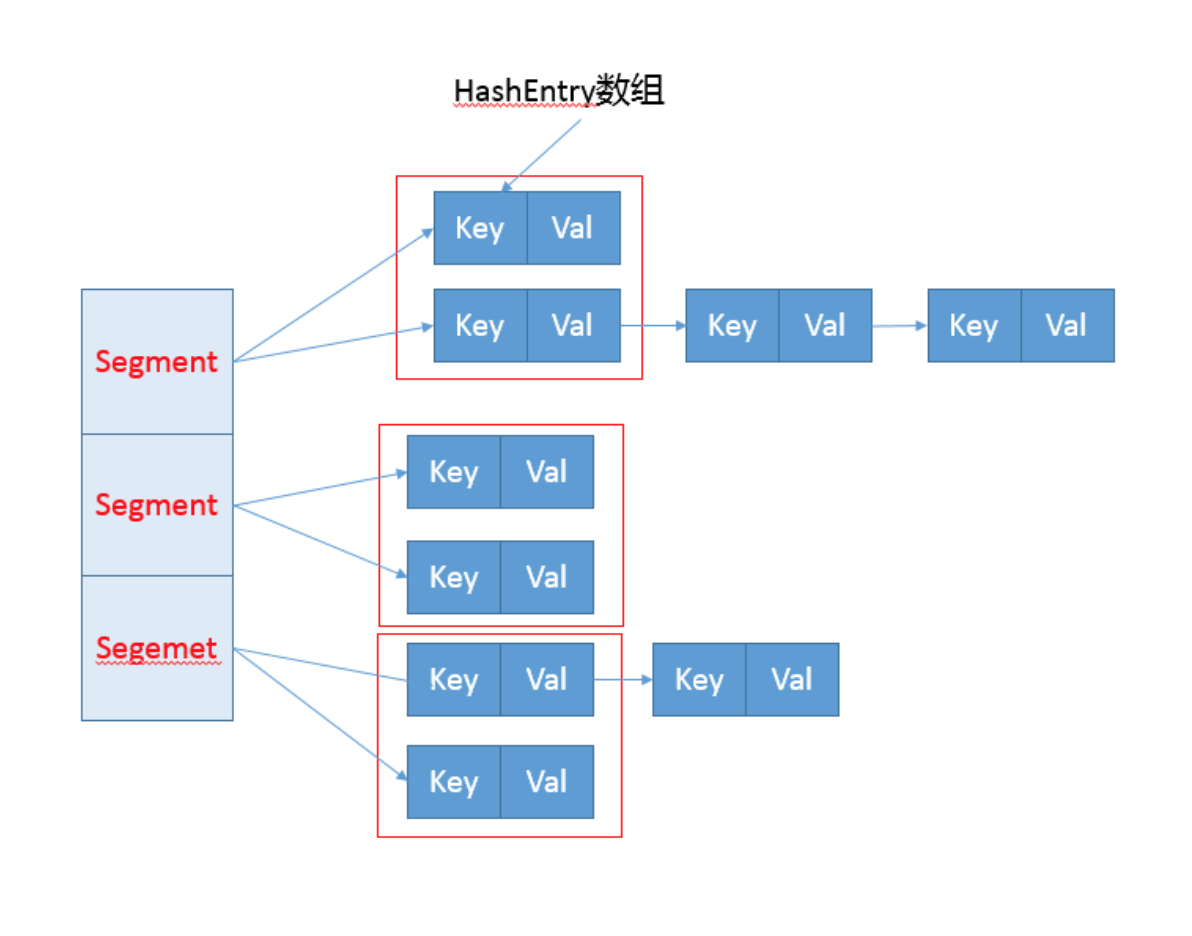
在构造的时候,Segment的数量由所谓的concurrentcyLevel决定,默认是16,也可以在相应构造函数直接指定。注意,Java需要它是2的幂数值,如果输入是类似15这种非幂 值,会被自动调整到16之类2的幂数值。
具体情况,我们一起看看一些Map基本操作的源码,这是JDK 7比较新的get代码。针对具体的优化部分,为方便理解,我直接注释在代码段里,get操作需要保证的是可见性,所以 并没有什么同步逻辑。
public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; int h = hash(key.hashCode()); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }
而对于put操作,首先是通过二次哈希避免哈希冲突,然后以Unsafe调用方式,直接获取相应的Segment,然后进行线程安全的put操作:
public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key.hashCode()); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }
其核心逻辑实现在下面的内部方法中:
final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
所以,从上面的源码清晰的看出,在进行并发写操作时:
- ConcurrentHashMap会获取再入锁,以保证数据一致性,Segment本身就是基于ReentrantLock的扩展实现,所以,在并发修改期间,相应Segment是被锁定的。
- 在最初阶段,进行重复性的扫描,以确定相应key值是否已经在数组里面,进而决定是更新还是放置操作,你可以在代码里看到相应的注释。重复扫描、检测冲突 是ConcurrentHashMap的常见技巧。
- 我在专栏上一讲介绍HashMap时,提到了可能发生的扩容问题,在ConcurrentHashMap中同样存在。不过有一个明显区别,就是它进行的不是整体的扩容,而是单独 对Segment进行扩容,细节就不介绍了。
另外一个Map的size方法同样需要关注,它的实现涉及分离锁的一个副作用。
试想,如果不进行同步,简单的计算所有Segment的总值,可能会因为并发put,导致结果不准确,但是直接锁定所有Segment进行计算,就会变得非常昂贵。其实,分离锁也限制了Map的初始化等操作。
所以,ConcurrentHashMap的实现是通过重试机制(RETRIES_BEFORE_LOCK,指定重试次数2),来试图获得可靠值。如果没有监控到发生变化(通过对比Segment.modCount),就直接返回,否则获取锁进行操作。
下面我来对比一下,在Java 8和之后的版本中,ConcurrentHashMap发生了哪些变化呢?
- 总体结构上,它的内部存储变得和我在专栏上一讲介绍的HashMap结构非常相似,同样是大的桶(bucket)数组,然后内部也是一个个所谓的链表结构(bin),同步的粒度要 更细致一些。
- 其内部仍然有Segment定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
- 因为不再使用Segment,初始化操作大大简化,修改为lazy-load形式,这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
- 数据存储利用volatile来保证可见性。
- 使用CAS等操作,在特定场景进行无锁并发操作。
- 使用Unsafe、LongAdder之类底层手段,进行极端情况的优化。
先看看现在的数据存储内部实现,我们可以发现Key是fnal的,因为在生命周期中,一个条目的Key发生变化是不可能的;与此同时val,则声明为volatile,以保证可见性。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; //... }
我这里就不再介绍get方法和构造函数了,相对比较简单,直接看并发的put是如何实现的。
/** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
初始化操作实现在initTable 里面,这是一个典型的CAS使用场景,利用volatile的sizeCtl作为互斥手段:如果发现竞争性的初始化,就spin在那里,等待条件恢复;否则利用CAS设 置排他标志。如果成功则进行初始化;否则重试。
/** * Initializes table, using the size recorded in sizeCtl. */ private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } break; } } return tab; }
当bin为空时,同样是没有必要锁定,也是以CAS操作去放置。 你有没有注意到,在同步逻辑上,它使用的是synchronized,而不是通常建议的ReentrantLock之类,这是为什么呢?现代JDK中,synchronized已经被不断优化,可以不再过分
担心性能差异,另外,相比于ReentrantLock,它可以减少内存消耗,这是个非常大的优势。
与此同时,更多细节实现通过使用Unsafe进行了优化,例如tabAt就是直接利用getObjectAcquire,避免间接调用的开销。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); }
再看看,现在是如何实现size操作的。阅读代码你会发现,真正的逻辑是在sumCount方法中, 那么sumCount做了什么呢?
final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
我们发现,虽然思路仍然和以前类似,都是分而治之的进行计数,然后求和处理,但实现却基于一个奇怪的CounterCell。 难道它的数值,就更加准确吗?数据一致性是怎么保证 的?
其实,对于CounterCell的操作,是基于java.util.concurrent.atomic.LongAdder进行的,是一种JVM利用空间换取更高效率的方法,利用了Striped64内部的复杂逻辑。这个东 西非常小众,大多数情况下,建议还是使用AtomicLong,足以满足绝大部分应用的性能需求。
今天我从线程安全问题开始,概念性的总结了基本容器工具,分析了早期同步容器的问题,进而分析了Java 7和Java 8中ConcurrentHashMap是如何设计实现的,希 望ConcurrentHashMap的并发技巧对你在日常开发可以有所帮助。
第11讲 | Java提供了哪些IO方式? NIO如何实现多路复用?
1)今天我要问你的问题是,Java提供了哪些IO方式? NIO如何实现多路复用?
2)典型回答
3)考点分析
4)知识拓展
- 区分同步或异步(synchronous/asynchronous)。简单来说,同步是一种可靠的有序运行机制,当我们进行同步操作时,后续的任务是等待当前调用返回,才会进行下一步; 而异步则相反,其他任务不需要等待当前调用返回,通常依靠事件、回调等机制来实现任务间次序关系。
- 区分阻塞与非阻塞(blocking/non-blocking)。在进行阻塞操作时,当前线程会处于阻塞状态,无法从事其他任务,只有当条件就绪才能继续,比如ServerSocket新连接建立 完毕,或数据读取、写入操作完成;而非阻塞则是不管IO操作是否结束,直接返回,相应操作在后台继续处理。
Java NIO概览
- Bufer,高效的数据容器,除了布尔类型,所有原始数据类型都有相应的Bufer实现。 Channel,类似在Linux之类操作系统上看到的文件描述符,是NIO中被用来支持批量式IO操作的一种抽象。
- File或者Socket,通常被认为是比较高层次的抽象,而Channel则是更加操作系统底层的一种抽象,这也使得NIO得以充分利用现代操作系统底层机制,获得特定场景的性能优 化,例如,DMA(Direct Memory Access)等。不同层次的抽象是相互关联的,我们可以通过Socket获取Channel,反之亦然。
- Selector,是NIO实现多路复用的基础,它提供了一种高效的机制,可以检测到注册在Selector上的多个Channel中,是否有Channel处于就绪状态,进而实现了单线程对 多Channel的高效管理。
Selector同样是基于底层操作系统机制,不同模式、不同版本都存在区别,例如,在最新的代码库里,相关实现如下:
Linux上依赖于epoll(http://hg.openjdk.java.net/jdk/jdk/fle/d8327f838b88/src/java.base/linux/classes/sun/nio/ch/EPollSelectorImpl.java )。
Windows上NIO2(AIO)模式则是依赖于iocp(http://hg.openjdk.java.net/jdk/jdk/fle/d8327f838b88/src/java.base/windows/classes/sun/nio/ch/Iocp.java )。
- Chartset,提供Unicode字符串定义,NIO也提供了相应的编解码器等,例如,通过下面的方式进行字符串到ByteBufer的转换:
Charset.defaultCharset().encode("Hello world!"));
第12讲 | Java有几种文件拷贝方式?哪一种最高效?
1)今天我要问你的问题是,Java有几种文件拷贝方式?哪一种最高效?
2)典型回答
- 利用java.io类库,直接为源文件构建一个FileInputStream读取,然后再为目标文件构建一个FileOutputStream,完成写入工作。
- 或者,利用java.nio类库提供的transferTo 或transferFrom方法实现。
从实践角度,我前面并没有明确说NIO transfer的方案一定最快,真实情况也确实未必如此。我们可以根据理论分析给出可行的推断,保持合理的怀疑,给出验证结论的思路,有时 候面试官考察的就是如何将猜测变成可验证的结论,思考方式远比记住结论重要。
从技术角度展开,下面这些方面值得注意:
- 不同的copy方式,底层机制有什么区别?
- 为什么零拷贝(zero-copy)可能有性能优势?
- Bufer分类与使用。
- Direct Bufer对垃圾收集等方面的影响与实践选择。
(1)拷贝实现机制分析
先来理解一下,前面实现的不同拷贝方法,本质上有什么明显的区别。
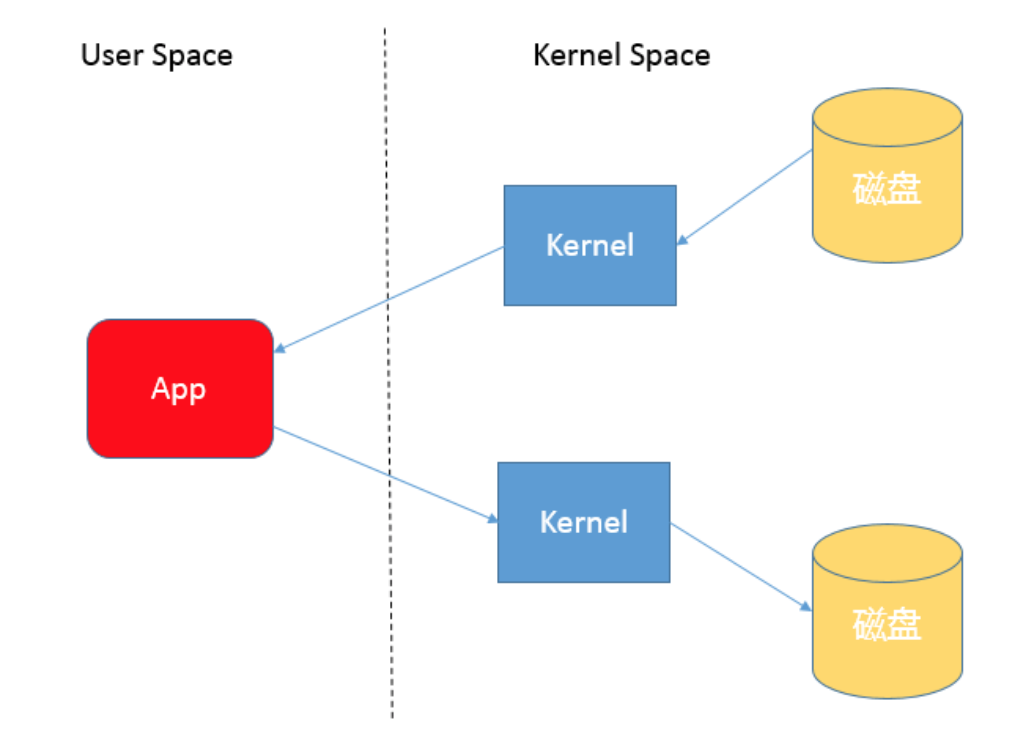
首先,你需要理解用户态空间(User Space)和内核态空间(Kernel Space),这是操作系统层面的基本概念,操作系统内核、硬件驱动等运行在内核态空间,具有相对高的特 权;而用户态空间,则是给普通应用和服务使用。你可以参考:https://en.wikipedia.org/wiki/User_space。
当我们使用输入输出流进行读写时,实际上是进行了多次上下文切换,比如应用读取数据时,先在内核态将数据从磁盘读取到内核缓存,再切换到用户态将数据从内核缓存读取到用 户缓存。
写入操作也是类似,仅仅是步骤相反,你可以参考下面这张图。
所以,这种方式会带来一定的额外开销,可能会降低IO效率。
而基于NIO transferTo的实现方式,在Linux和Unix上,则会使用到零拷贝技术,数据传输并不需要用户态参与,省去了上下文切换的开销和不必要的内存拷贝,进而可能提高应用拷贝性能。注意,transferTo 不仅仅是可以用在文件拷贝中,与其类似的,例如读取磁盘文件,然后进行Socket发送,同样可以享受这种机制带来的性能和扩展性提高。
transferTo 的传输过程是:
(2)Java IO/NIO源码结构
前面我在典型回答中提了第三种方式,即Java标准库也提供了文件拷贝方法(java.nio.fle.Files.copy)。如果你这样回答,就一定要小心了,因为很少有问题的答案是仅仅调用某 个方法。从面试的角度,面试官往往会追问:既然你提到了标准库,那么它是怎么实现的呢?有的公司面试官以喜欢追问而出名,直到追问到你说不知道。
我这里重点介绍两种特别的Bufer。
- Direct Bufer:如果我们看Bufer的方法定义,你会发现它定义了isDirect()方法,返回当前Bufer是否是Direct类型。这是因为Java提供了堆内和堆外(Direct)Bufer,我 们可以以它的allocate或者allocateDirect方法直接创建。
- MappedByteBufer:它将文件按照指定大小直接映射为内存区域,当程序访问这个内存区域时将直接操作这块儿文件数据,省去了将数据从内核空间向用户空间传输的损耗。我 们可以使用FileChannel.map创建MappedByteBufer,它本质上也是种Direct Bufer。
在实际使用中,Java会尽量对Direct Bufer仅做本地IO操作,对于很多大数据量的IO密集操作,可能会带来非常大的性能优势,因为:
- Direct Bufer生命周期内内存地址都不会再发生更改,进而内核可以安全地对其进行访问,很多IO操作会很高效。
- 减少了堆内对象存储的可能额外维护工作,所以访问效率可能有所提高。
但是请注意,Direct Bufer创建和销毁过程中,都会比一般的堆内Bufer增加部分开销,所以通常都建议用于长期使用、数据较大的场景。
使用Direct Bufer,我们需要清楚它对内存和JVM参数的影响。首先,因为它不在堆上,所以Xmx之类参数,其实并不能影响Direct Bufer等堆外成员所使用的内存额度,我们可 以使用下面参数设置大小:
-XX:MaxDirectMemorySize=512M
从参数设置和内存问题排查角度来看,这意味着我们在计算Java可以使用的内存大小的时候,不能只考虑堆的需要,还有Direct Bufer等一系列堆外因素。如果出现内存不足,堆 外内存占用也是一种可能性。
另外,大多数垃圾收集过程中,都不会主动收集Direct Bufer,它的垃圾收集过程,就是基于我在专栏前面所介绍的Cleaner(一个内部实现)和幻象引用 (PhantomReference)机制,其本身不是public类型,内部实现了一个Deallocator负责销毁的逻辑。对它的销毁往往要拖到full GC的时候,所以使用不当很容易导 致OutOfMemoryError。
对于Direct Bufer的回收,我有几个建议:
- 在应用程序中,显式地调用System.gc()来强制触发。
- 另外一种思路是,在大量使用Direct Bufer的部分框架中,框架会自己在程序中调用释放方法,Netty就是这么做的,有兴趣可以参考其实现(PlatformDependent0)。
- 重复使用Direct Bufer。
(5)跟踪和诊断Direct Bufer内存占用?
因为通常的垃圾收集日志等记录,并不包含Direct Bufer等信息,所以Direct Bufer内存诊断也是个比较头疼的事情。幸好,在JDK 8之后的版本,我们可以方便地使用Native Memory Tracking(NMT)特性来进行诊断,你可以在程序启动时加上下面参数:
-XX:NativeMemoryTracking={summary|detail}
注意,激活NMT通常都会导致JVM出现5%~10%的性能下降,请谨慎考虑。
运行时,可以采用下面命令进行交互式对比:
// 打印NMT信息 jcmd <pid> VM.native_memory detail // 进行baseline,以对比分配内存变化 jcmd <pid> VM.native_memory baseline // 进行baseline,以对比分配内存变化 jcmd <pid> VM.native_memory detail.dif
我们可以在Internal部分发现Direct Bufer内存使用的信息,这是因为其底层实际是利用unsafe_allocatememory。严格说,这不是JVM内部使用的内存,所以在JDK 11以后, 其实它是归类在other部分里。
JDK 9的输出片段如下,“+”表示的就是dif命令发现的分配变化:
-Internal (reserved=679KB +4KB, committed=679KB +4KB) (malloc=615KB +4KB #1571 +4) (mmap: reserved=64KB, committed=64KB)
注意:JVM的堆外内存远不止Direct Bufer,NMT输出的信息当然也远不止这些,我在专栏后面有综合分析更加具体的内存结构的主题。
今天我分析了Java IO/NIO底层文件操作数据的机制,以及如何实现零拷贝的高性能操作,梳理了Bufer的使用和类型,并针对Direct Bufer的生命周期管理和诊断进行了较详细
的分析。
第13讲 | 谈谈接口和抽象类有什么区别?
Java是非常典型的面向对象语言,曾经有一段时间,程序员整天把面向对象、设计模式挂在嘴边。虽然如今大家对这方面已经不再那么狂热,但是不可否认,掌握面向对象设计原则 和技巧,是保证高质量代码的基础之一。
面向对象提供的基本机制,对于提高开发、沟通等各方面效率至关重要。考察面向对象也是面试中的常见一环,下面我来聊聊面向对象设计基础。
1)今天我要问你的问题是,谈谈接口和抽象类有什么区别?
2)典型回答
接口和抽象类是Java面向对象设计的两个基础机制。
接口是对行为的抽象,它是抽象方法的集合,利用接口可以达到API定义和实现分离的目的。
抽象类是不能实例化的类,用abstract关键字修饰class,其目的主要是代码重用。
第14讲 | 谈谈你知道的设计模式?
1)今天我要问你的问题是,谈谈你知道的设计模式?请手动实现单例模式,Spring等框架中使用了哪些模式?
2)典型回答
大致按照模式的应用目标分类,设计模式可以分为创建型模式、结构型模式和行为型模式。
(动作)创建型模式,是对对象创建过程的各种问题和解决方案的总结,包括各种工厂模式(Factory、Abstract Factory)、单例模式(Singleton)、构建器模式(Builder)、原型模式(ProtoType )。
(结果)结构型模式,是针对软件设计结构的总结,关注于类、对象继承、组合方式的实践经验。常见的结构型模式,包括桥接模式(Bridge)、适配器模式(Adapter)、装饰者模式 (Decorator)、代理模式(Proxy)、组合模式(Composite)、外观模式(Facade)、享元模式(Flyweight)等。
(过程)行为型模式,是从类或对象之间交互、职责划分等角度总结的模式。比较常见的行为型模式有策略模式(Strategy)、解释器模式(Interpreter)、命令模式(Command)、观察者模式(Observer)、迭代器模式(Iterator)、模板方法模式(Template Method)、访问者模式(Visitor)。
3)考点分析
这个问题主要是考察你对设计模式的了解和掌握程度,更多相关内容你可以参考:https://en.wikipedia.org/wiki/Design_Patterns。
InputStream 典型的装饰器模式应用案例
创建HttpRequest的过程,就是典型的构建器模式(Builder),通常会被实现成fuent风格的API,也有人叫它方法链。
双重检查的单例模型
第15讲 | synchronized和ReentrantLock有什么区别呢?
1)今天我要问你的问题是, synchronized和ReentrantLock有什么区别?有人说synchronized最慢,这话靠谱吗?
2)典型回答
synchronized是Java内建的同步机制,所以也有人称其为Intrinsic Locking,它提供了互斥的语义和可见性,当一个线程已经获取当前锁时,其他试图获取的线程只能等待或者阻 塞在那里。
3)考点分析
- 带超时的获取锁尝试。
- 可以判断是否有线程,或者某个特定线程,在排队等待获取锁。
- 可以响应中断请求。
第15讲 | 谈谈我对Java学习和面试的看法
- 动手实践是必要一步,如果连上手操作都不肯,你会发现自己的理解很难有深度。
- 在交流的过程中你会发现,很多似是而非的理解,竟然在试图组织语言的时候,突然就想明白了,而且别人的观点也验证了自己的判断。技术领域尤其如此,把自己的理解整理成 文字,输出、交流是个非常好的提高方法,甚至我认为这是技术工作者成长的必经之路。
- 根据实践统计,工程师实际工作中,阅读代码的时间其实大大超过写代码的时间,这意味着阅读、总结能力,会直接影响我们的工作效率!这东西有没有捷径呢,也许吧,我的心 得是:“无他,但手熟尔”。
- 参考别人的架构、实现,分析其历史上掉过的坑,这是天然的好材料,具体阅读时可以从其修正过的问题等角度入手。
- 现代软件工程,节奏越来越快,需求复杂而多变,越来越凸显出白盒方式的重要性。快速定位问题往往需要黑盒结合白盒能力,对内部一无所知,可能就没有思路。与此同时,通 用平台、开源框架,不见得能够非常符合自己的业务需求,往往只有深入源代码层面进行定制或者自研,才能实现。我认为这也是软件工程师地位不断提高的原因之一。
- 带着问题和明确目的去阅读,比如,以debug某个问题的角度,结合实践去验证,让自己能够感到收获,既加深理解,也有实际帮助,激励我们坚持下来。
- 一定要有输出,至少要写下来,整理心得,交流、验证、提高。这和我们日常工作是类似的,千万不要做了好长一段时间后和领导说,没什么结论。
我前面提到了白盒方式的重要性,但是,需要慎重决定对内部的依赖,分清是Hack还是Solution。出来混,总是要还的!如果以某种hack方式解决问题,临时性的当然可以,长久 会积累并成为升级的障碍,甚至堆积起来愈演愈烈。比如说,我在实验Cassandra的时候,发现它在并发部分引用了Unsafe.monitorEnter()/moniterExit(),这会导致它无法平 滑运行在新版的JDK上,因为相应内部API被移除了,比较幸运的是这个东西有公共API可以替代。
最后谈谈我在面试时会看中候选人的哪些素质和能力。
结合我在实际工作中的切身体会,面试时有几个方面我会特别在乎:
- 技术素养好,能够进行深度思考,而不是跳脱地夸夸其谈,所以我喜欢问人家最擅长的东西,如果在最擅长的领域尚且不能仔细思考,怎么能保证在下一份工作中踏实研究呢。当然这种思考,并不是说非要死扣底层和细节,能够看出业务中平凡事情背后的工程意义,同样是不错的。毕竟,除了特别的岗位,大多数任务,如果有良好的技术素养和工作热情, 再配合一定经验,基本也就能够保证胜任了。
- 职业精神,是否表现出认真对待每一个任务。我们是职场打拼的专业人士,不是幼儿园被呵护的小朋友,如果有人太挑活儿,团队往往就无法做到基本的公平。有经验的管理角色, 大多是把自己的管理精力用在团队的正面建设,而不是把精力浪费在拖团队后腿的人身上,难以协作的人,没有人会喜欢。有人说你的职业高度取决于你“填坑”的能力,我觉得很有道理。现实工作中很少有理想化的完美任务,既目标清晰又有挑战,恰好还是我擅长,这种任务不多见。能够主动地从不清晰中找出清晰,切实地解决问题,是非常重要的能力。
- 是否hands-on,是否主动。我一般不要求当前需要的方面一定是很hands-on,但至少要表现出能够做到。
第16讲 | synchronized底层如何实现?什么是锁的升级、降级?
为了简化便于理解,我这里会专注于通用的基类实现:
- sharedRuntime.cpp/hpp,它是解释器和编译器运行时的基类。
- synchronizer.cpp /hpp,JVM同步相关的各种基础逻辑。
Handle h_obj(THREAD, obj); if (UseBiasedLocking) { // Retry fast entry if bias is revoked to avoid unnecessary inflation ObjectSynchronizer::fast_enter(h_obj, lock, true, CHECK); } else { ObjectSynchronizer::slow_enter(h_obj, lock, CHECK); }
- UseBiasedLocking是一个检查,因为,在JVM启动时,我们可以指定是否开启偏斜锁。
还有一方面是,偏斜锁会延缓JIT 预热的进程,所以很多性能测试中会显式地关闭偏斜锁,命令如下:
-XX:-UseBiasedLocking
- fast_enter是我们熟悉的完整锁获取路径,slow_enter则是绕过偏斜锁,直接进入轻量级锁获取逻辑。
// ----------------------------------------------------------------------------- // Fast Monitor Enter/Exit // This the fast monitor enter. The interpreter and compiler use // some assembly copies of this code. Make sure update those code // if the following function is changed. The implementation is // extremely sensitive to race condition. Be careful. void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) { if (UseBiasedLocking) { if (!SafepointSynchronize::is_at_safepoint()) { BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD); if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) { return; } } else { assert(!attempt_rebias, "can not rebias toward VM thread"); BiasedLocking::revoke_at_safepoint(obj); } assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now"); } slow_enter(obj, lock, THREAD); }
我来分析下这段逻辑实现:
- biasedLocking定义了偏斜锁相关操作,revoke_and_rebias是获取偏斜锁的入口方法,revoke_at_safepoint则定义了当检测到安全点时的处理逻辑。
- 如果获取偏斜锁失败,则进入slow_enter。
- 这个方法里面同样检查是否开启了偏斜锁,但是从代码路径来看,其实如果关闭了偏斜锁,是不会进入这个方法的,所以算是个额外的保障性检查吧。
另外,如果你仔细查看synchronizer.cpp 里,会发现不仅仅是synchronized的逻辑,包括从本地代码,也就是JNI,触发的Monitor动作,全都可以在里面找到 (jni_enter/jni_exit)。
关于biasedLocking的更多细节我就不展开了,明白它是通过CAS设置Mark Word就完全够用了,对象头中Mark Word的结构,可以参考下图:

顺着锁升降级的过程分析下去,偏斜锁到轻量级锁的过程是如何实现的呢?
我们来看看slow_enter到底做了什么。
// ----------------------------------------------------------------------------- // Interpreter/Compiler Slow Case // This routine is used to handle interpreter/compiler slow case // We don't need to use fast path here, because it must have been // failed in the interpreter/compiler code. void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) { markOop mark = obj->mark(); assert(!mark->has_bias_pattern(), "should not see bias pattern here"); if (mark->is_neutral()) { // Anticipate successful CAS -- the ST of the displaced mark must // be visible <= the ST performed by the CAS. lock->set_displaced_header(mark); if (mark == obj()->cas_set_mark((markOop) lock, mark)) { TEVENT(slow_enter: release stacklock); return; } // Fall through to inflate() ... } else if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) { assert(lock != mark->locker(), "must not re-lock the same lock"); assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock"); lock->set_displaced_header(NULL); return; } // The object header will never be displaced to this lock, // so it does not matter what the value is, except that it // must be non-zero to avoid looking like a re-entrant lock, // and must not look locked either. lock->set_displaced_header(markOopDesc::unused_mark()); ObjectSynchronizer::inflate(THREAD, obj(), inflate_cause_monitor_enter)->enter(THREAD); }
请结合我在代码中添加的注释,来理解如何从试图获取轻量级锁,逐步进入锁膨胀的过程。你可以发现这个处理逻辑,和我在这一讲最初介绍的过程是十分吻合的。
- 设置Displaced Header,然后利用cas_set_mark设置对象Mark Word,如果成功就成功获取轻量级锁。
- 否则Displaced Header,然后进入锁膨胀阶段,具体实现在infate方法中。
今天就不介绍膨胀的细节了,我这里提供了源代码分析的思路和样例,考虑到应用实践,再进一步增加源代码解读意义不大,有兴趣的同学可以参考我提供的synchronizer.cpp 链接,例如:
- defate_idle_monitors是分析锁降级逻辑的入口,这部分行为还在进行持续改进,因为其逻辑是在安全点内运行,处理不当可能拖长JVM停顿(STW,stop-the-world)的时间。
- fast_exit或者slow_exit是对应的锁释放逻辑。
第17讲 | 一个线程两次调用start()方法会出现什么情况?
第18讲 | 什么情况下Java程序会产生死锁?如何定位、修复?
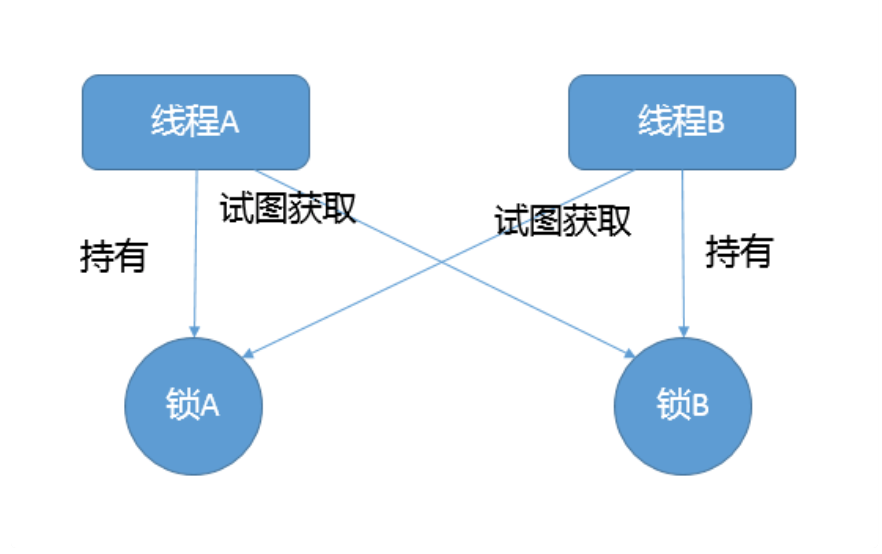
1)今天我要问你的问题是,什么情况下Java程序会产生死锁?如何定位、修复?
3)考点分析
- 互斥条件,类似Java中Monitor都是独占的,要么是我用,要么是你用。
- 互斥条件是长期持有的,在使用结束之前,自己不会释放,也不能被其他线程抢占。
- 循环依赖关系,两个或者多个个体之间出现了锁的链条环。
第二种方法
如果必须使用多个锁,尽量设计好锁的获取顺序。
第三种方法
使用带超时的方法,为程序带来更多可控性。
第19讲 | Java并发包提供了哪些并发工具类?
- 提供了比synchronized更加高级的各种同步结构,包括CountDownLatch、CyclicBarrier、Semaphore等,可以实现更加丰富的多线程操作,比如利用Semaphore作为资源控制器,限制同时进行工作的线程数量。
- 各种线程安全的容器,比如最常见的ConcurrentHashMap、有序的ConcunrrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。
- 各种并发队列实现,如各种BlockedQueue实现,比较典型的ArrayBlockingQueue、 SynchorousQueue或针对特定场景的PriorityBlockingQueue等。
- 强大的Executor框架,可以创建各种不同类型的线程池,调度任务运行等,绝大部分情况下,不再需要自己从头实现线程池和任务调度器。
第20讲 | 并发包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么区别?
- Concurrent类型基于lock-free,在常见的多线程访问场景,一般可以提供较高吞吐量。
- 而LinkedBlockingQueue内部则是基于锁,并提供了BlockingQueue的等待性方法。
3)考点分析
第21讲 | Java并发类库提供的线程池有哪几种? 分别有什么特点?
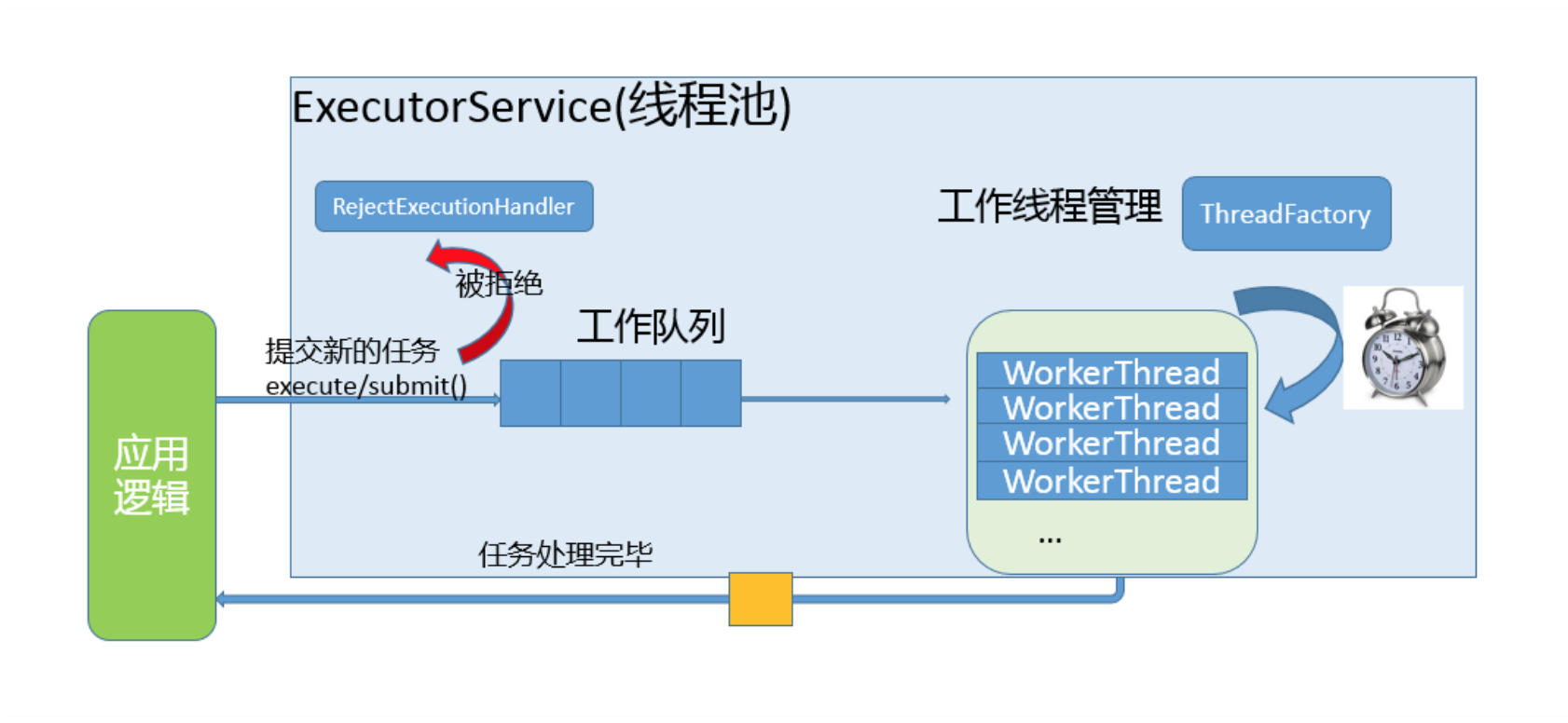
第22讲 | AtomicInteger底层实现原理是什么?如何在自己的产品代码中应用CAS操作?
1)今天我要问你的问题是,AtomicInteger底层实现原理是什么?如何在自己的产品代码中应用CAS操作?
2)典型回答
4)AQS
第23讲 | 请介绍类加载过程,什么是双亲委派模型?
public class CLPreparation { public static int a = 100; public static final int INT_CONSTANT = 1000; public static final Integer INTEGER_CONSTANT = Integer.valueOf(10000); }
javac CLPreparation.java
javap –v CLPreparation.class
0: bipush 100 2: putsatic 5: sipush 10000 8: invokesatic #3 11: putsatic #4 // Field a:I // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; // Field INTEGER_CONSTANT:Ljava/lang/Integer;
- 如果要真正理解双亲委派模型,需要理解Java中类加载器的架构和职责,至少要懂具体有哪些内建的类加载器,这些是我上面的回答里没有提到的;以及如何自定义类加载器?
- 从应用角度,解决某些类加载问题,例如我的Java程序启动较慢,有没有办法尽量减小Java类加载的开销?
4)拓展知识
第24讲 | 有哪些方法可以在运行时动态生成一个Java类?
1)今天我要问你的问题是,有哪些方法可以在运行时动态生成一个Java类?
2)典型回答
前面的方法,本质上还是在当前程序进程之外编译的,那么还有没有不这么low的办法呢?
你可以考虑使用Java Compiler API,这是JDK提供的标准API,里面提供了与javac对等的编译器功能,具体请参考java.compiler相关文档。
- 字节码和类加载到底是怎么无缝进行转换的?发生在整个类加载过程的哪一步?
- 如何利用字节码操纵技术,实现基本的动态代理逻辑?
- 除了动态代理,字节码操纵技术还有那些应用场景?
4)知识拓展
protected fnal Class<?> defneClass(String name, byte[] b, int of, int len, ProtectionDomain protectionDomain) protected fnal Class<?> defneClass(String name, java.nio.ByteBufer b, ProtectionDomain protectionDomain)
static native Class<?> defneClass1(ClassLoader loader, String name, byte[] b, int of, int len, ProtectionDomain pd, String source); static native Class<?> defneClass2(ClassLoader loader, String name, java.nio.ByteBufer b, int of, int len, ProtectionDomain pd, String source);
byte[] proxyClassFile = ProxyGenerator.generateProxyClass( proxyName, interfaces.toArray(EMPTY_CLASS_ARRAY), accessFlags); try { Class<?> pc = UNSAFE.defneClass(proxyName, proxyClassFile, 0, proxyClassFile.length, loader, null); reverseProxyCache.sub(pc).putIfAbsent(loader, Boolean.TRUE); return pc; } catch (ClassFormatError e) { // 如果出现ClassFormatError,很可能是输入参数有问题,比如,ProxyGenerator有bug }
/** * Generate code for a load or store instruction for the given local * variable. The code is written to the supplied stream. * * "opcode" indicates the opcode form of the desired load or store * instruction that takes an explicit local variable index, and * "opcode_0" indicates the corresponding form of the instruction * with the implicit index 0. */ private void codeLocalLoadStore(int lvar, int opcode, int opcode_0, DataOutputStream out) throws IOException { assert lvar >= 0 && lvar <= 0xFFFF; if (lvar <= 3) { out.writeByte(opcode_0 + lvar); } else if (lvar <= 0xFF) { out.writeByte(opcode); out.writeByte(lvar & 0xFF); } else { /* * Use the "wide" instruction modifier for local variable * indexes that do not fit into an unsigned byte. */ out.writeByte(opc_wide); out.writeByte(opcode); out.writeShort(lvar & 0xFFFF); } }
- 提供一个基础的接口,作为被调用类型(com.mycorp.HelloImpl)和代理类之间的统一入口,如com.mycorp.Hello。
- 实现InvocationHandler,对代理对象方法的调用,会被分派到其invoke方法来真正实现动作。
- 通过Proxy类,调用其newProxyInstance方法,生成一个实现了相应基础接口的代理类实例,可以看下面的方法签名。
public satic Object newProxyInsance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
- 各种Mock框架
- ORM框架
- IOC容器
- 部分Profler工具,或者运行时诊断工具等
- 生成形式化代码的工具
以考虑使用更加高层次视角的类库,例如Byte Buddy等。
第25讲 | 谈谈JVM内存区域的划分,哪些区域可能发生OutOfMemoryError?
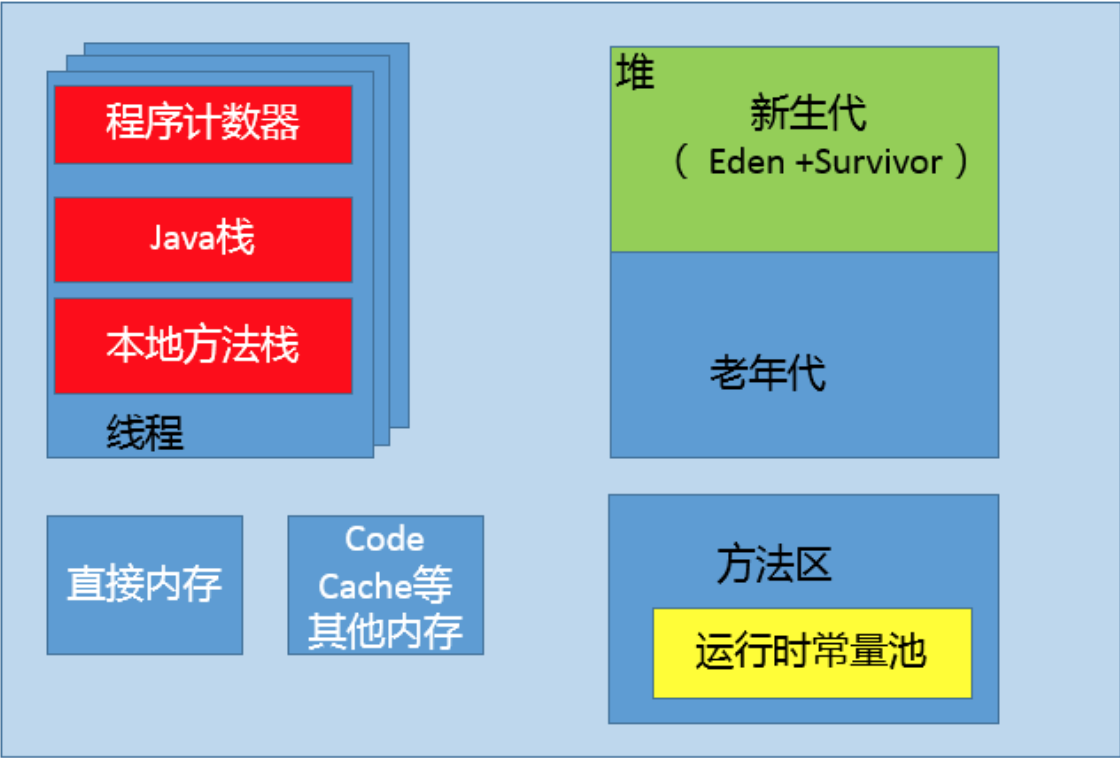
- 堆内存不足是最常见的OOM原因之一,抛出的错误信息是“java.lang.OutOfMemoryError:Java heap space”,原因可能千奇百怪,例如,可能存在内存泄漏问题;也很有可能就是堆的大小不合理,比如我们要处理比较可观的数据量,但是没有显式指定JVM堆大小或者指定数值偏小;或者出现JVM处理引用不及时,导致堆积起来,内存无法释放等。
- 而对于Java虚拟机栈和本地方法栈,这里要稍微复杂一点。如果我们写一段程序不断的进行递归调用,而且没有退出条件,就会导致不断地进行压栈。类似这种情况,JVM实际会抛出StackOverFlowError;当然,如果JVM试图去扩展栈空间的的时候失败,则会抛出OutOfMemoryError。
- 对于老版本的Oracle JDK,因为永久代的大小是有限的,并且JVM对永久代垃圾回收(如,常量池回收、卸载不再需要的类型)非常不积极,所以当我们不断添加新类型的时 候,永久代出现OutOfMemoryError也非常多见,尤其是在运行时存在大量动态类型生成的场合;类似Intern字符串缓存占用太多空间,也会导致OOM问题。对应的异常信息, 会标记出来和永久代相关:“java.lang.OutOfMemoryError: PermGen space”。
- 随着元数据区的引入,方法区内存已经不再那么窘迫,所以相应的OOM有所改观,出现OOM,异常信息则变成了:“java.lang.OutOfMemoryError: Metaspace”。
- 直接内存不足,也会导致OOM,这个已经专栏第11讲介绍过。
第26讲 | 如何监控和诊断JVM堆内和堆外内存使用?
1)今天我要问你的问题是,如何监控和诊断JVM堆内和堆外内存使用?
2)典型回答
- 也可以使用命令行工具进行运行时查询,如jstat和jmap等工具都提供了一些选项,可以查看堆、方法区等使用数据。
- 或者,也可以使用jmap等提供的命令,生成堆转储(Heap Dump)文件,然后利用jhat或Eclipse MAT等堆转储分析工具进行详细分析。
- 如果你使用的是Tomcat、Weblogic等Java EE服务器,这些服务器同样提供了内存管理相关的功能。
- 另外,从某种程度上来说,GC日志等输出,同样包含着丰富的信息。
3)知识拓展
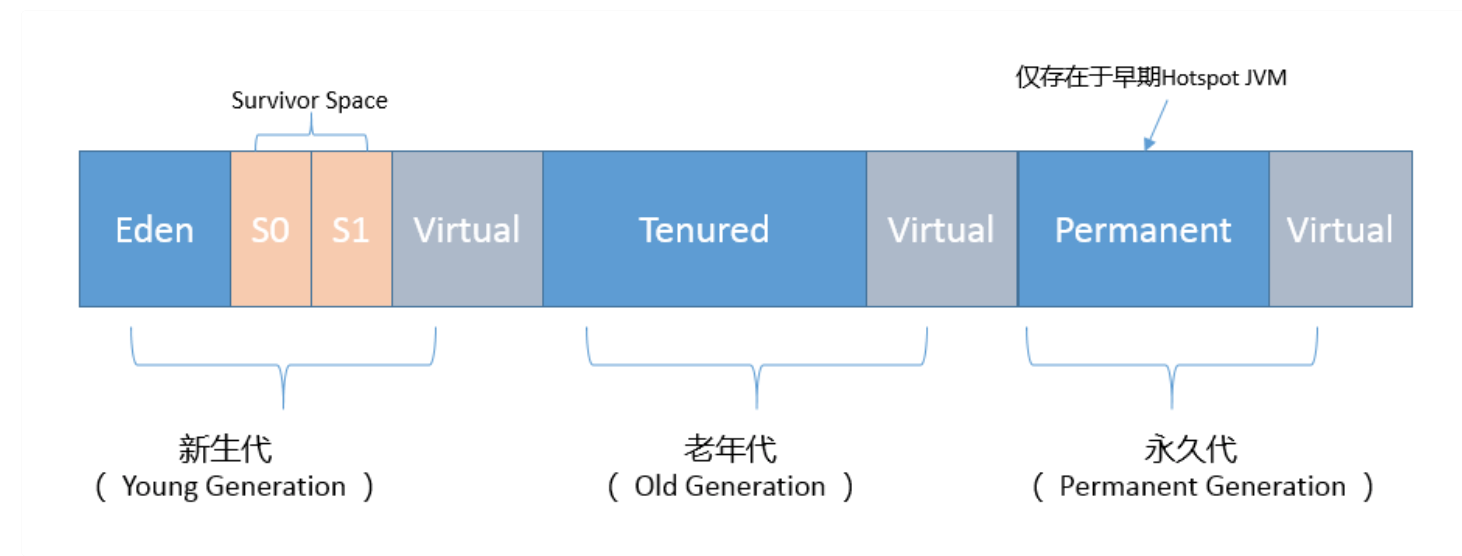
- JVM会随意选取一个Survivor区域作为“to”,然后会在GC过程中进行区域间拷贝,也就是将Eden中存活下来的对象和from区域的对象,拷贝到这个“to”区域。这种设计主要是为 了防止内存的碎片化,并进一步清理无用对象。
-
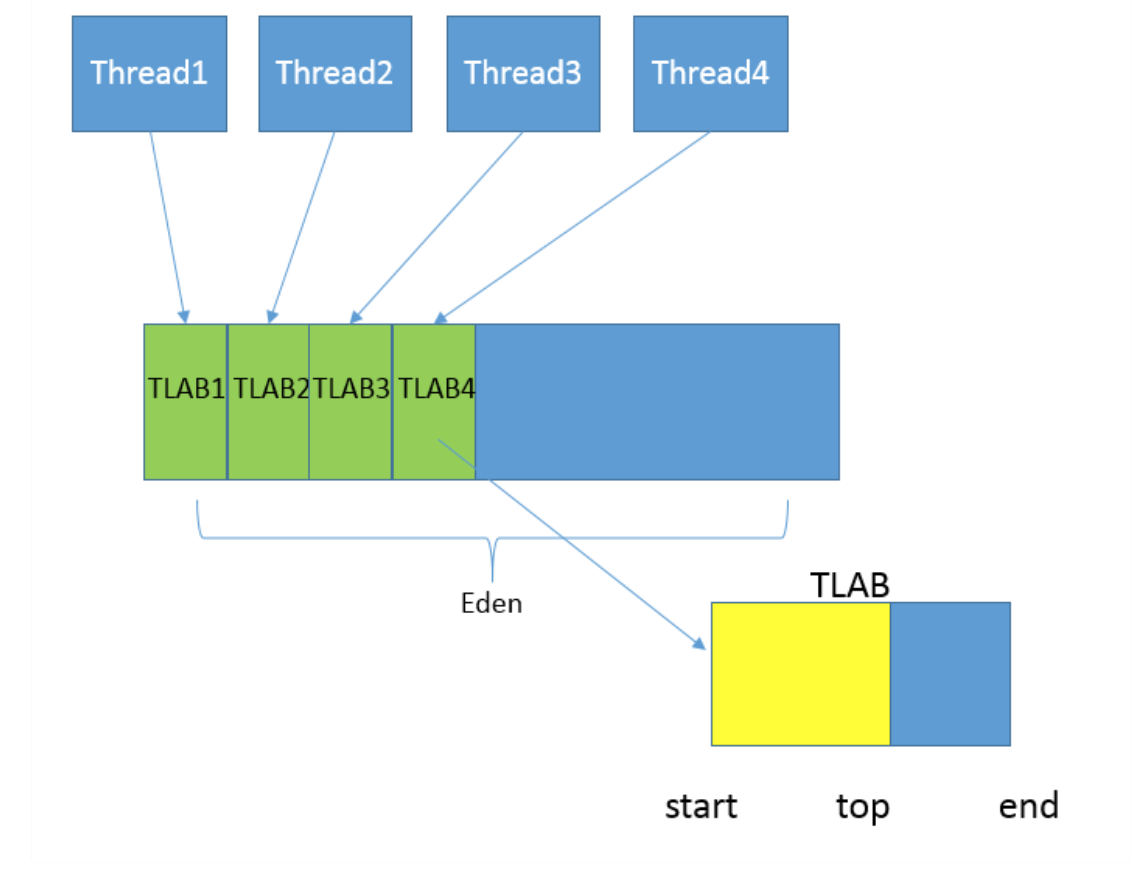
从内存模型而不是垃圾收集的角度,对Eden区域继续进行划分,Hotspot JVM还有一个概念叫做Thread Local Allocation Bufer(TLAB),据我所知所有OpenJDK衍生出来 的JVM都提供了TLAB的设计。这是JVM为每个线程分配的一个私有缓存区域,否则,多线程同时分配内存时,为避免操作同一地址,可能需要使用加锁等机制,进而影响分配速 度,你可以参考下面的示意图。从图中可以看出,TLAB仍然在堆上,它是分配在Eden区域内的。其内部结构比较直观易懂,start、end就是起始地址,top(指针)则表示已经 分配到哪里了。所以我们分配新对象,JVM就会移动top,当top和end相遇时,即表示该缓存已满,JVM会试图再从Eden里分配一块儿。
(2)老年代
(3)永久代
不知道你有没有注意到,我在年代视角的堆结构示意图也就是第一张图中,还标记出了Virtual区域,这是块儿什么区域呢?
在JVM内部,如果Xms小于Xmx,堆的大小并不会直接扩展到其上限,也就是说保留的空间(reserved)大于实际能够使用的空间(committed)。当内存需求不断增长的时 候,JVM会逐渐扩展新生代等区域的大小,所以Virtual区域代表的就是暂时不可用(uncommitted)的空间。
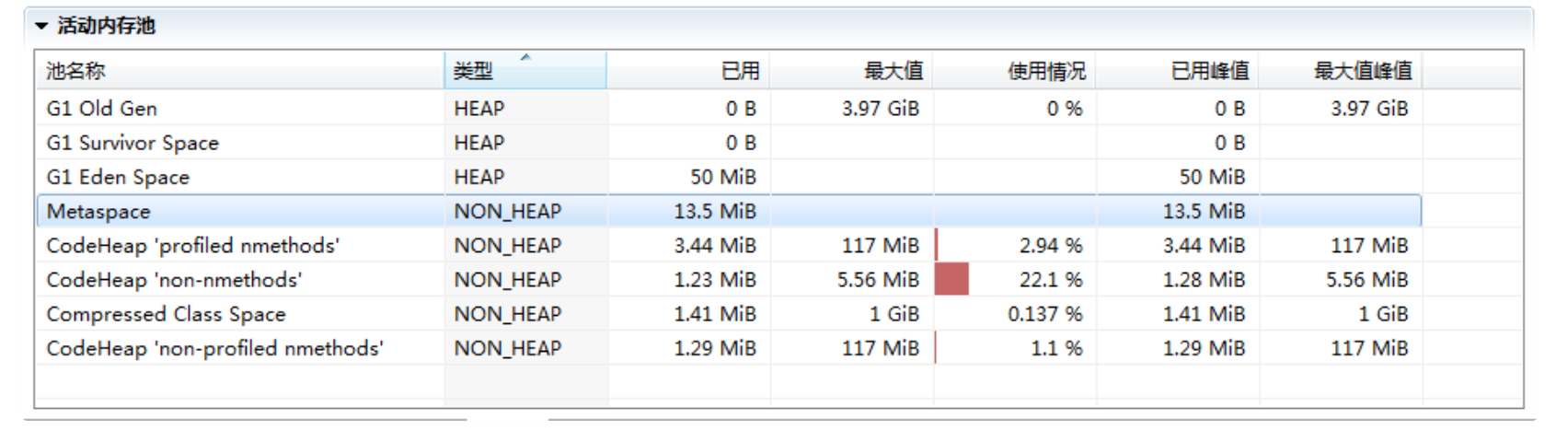
第二,分析完堆内空间,我们一起来看看JVM堆外内存到底包括什么? 在JMC或JConsole的内存管理界面,会统计部分非堆内存,但提供的信息相对有限,下图就是JMC活动内存池的截图。
接下来我会依赖NMT特性对JVM进行分析,它所提供的详细分类信息,非常有助于理解JVM内部实现。
首先来做些准备工作,开启NMT并选择summary模式,
-XX:NativeMemoryTracking=summary
-XX:+UnlockDiagnosicVMOptions -XX:+PrintNMTStatisics
然后,执行一个简单的在标准输出打印HelloWorld的程序,就可以得到下面的输出。
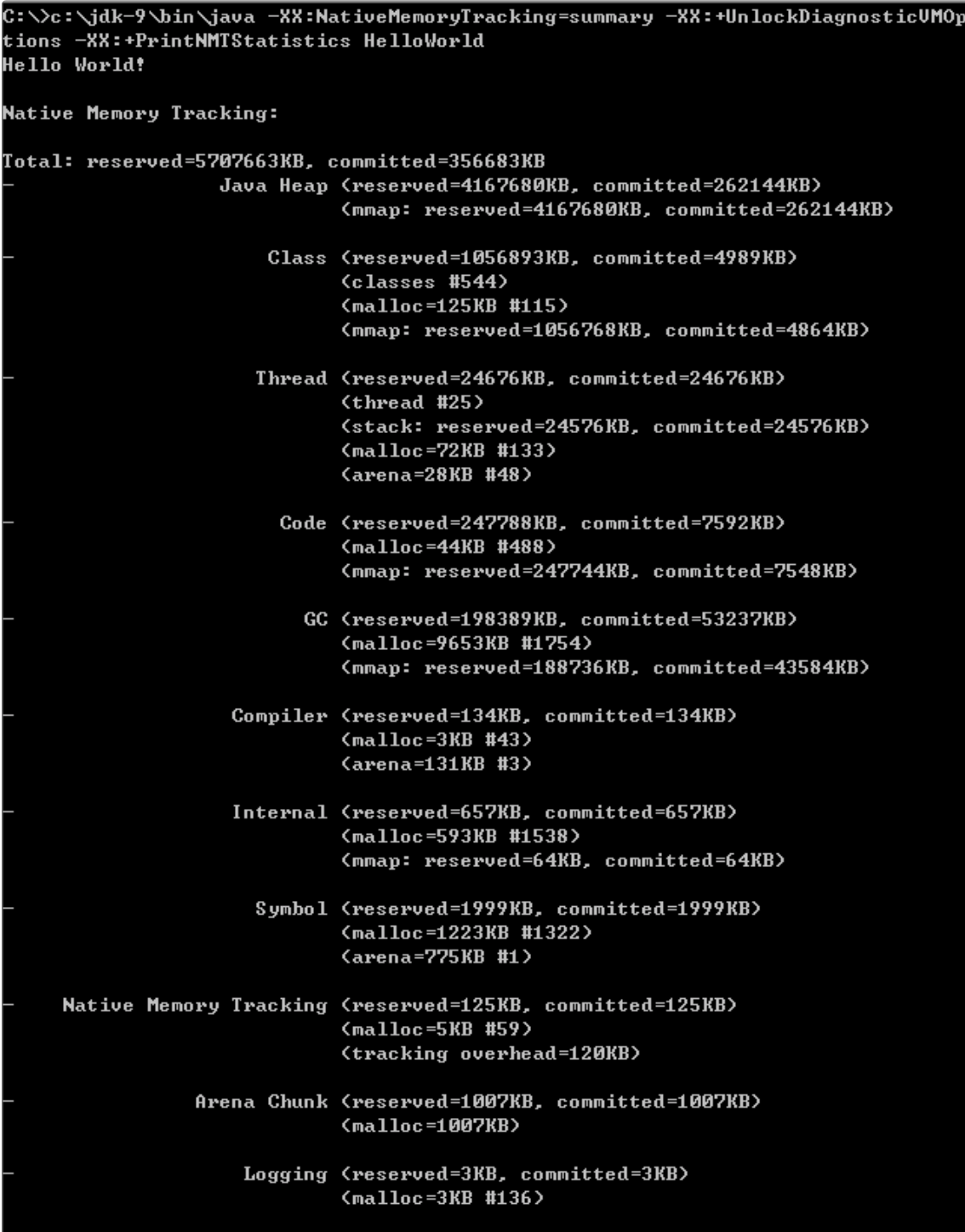
我来仔细分析一下,NMT所表征的JVM本地内存使用:
- 第一部分非常明显是Java堆,我已经分析过使用什么参数调整,不再赘述。
- 第二部分是Class内存占用,它所统计的就是Java类元数据所占用的空间,JVM可以通过类似下面的参数调整其大小:
-XX:MaxMetaspaceSize=value
-XX:InitialBootClassLoaderMetaspaceSize=30720
- 下面是Thread,这里既包括Java线程,如程序主线程、Cleaner线程等,也包括GC等本地线程。你有没有注意到,即使是一个HelloWorld程序,这个线程数量竟然还有25。似乎有很多浪费,设想我们要用Java作为Serverless运行时,每个function是非常短暂的,如何降低线程数量呢?
如果你充分理解了专栏讲解的内容,对JVM内部有了充分理解,思路就很清晰了:
JDK 9的默认GC是G1,虽然它在较大堆场景表现良好,但本身就会比传统的Parallel GC或者Serial GC之类复杂太多,所以要么降低其并行线程数目,要么直接切换GC类型; JIT编译默认是开启了TieredCompilation的,将其关闭,那么JIT也会变得简单,相应本地线程也会减少。
我们来对比一下,这是默认参数情况的输出:

下面是替换了默认GC,并关闭TieredCompilation的命令行

得到的统计信息如下,线程数目从25降到了17,消耗的内存也下降了大概1/3。

- 接下来是Code统计信息,显然这是CodeCache相关内存,也就是JIT compiler存储编译热点方法等信息的地方,JVM提供了一系列参数可以限制其初始值和最大值等,例如:
-XX:InitialCodeCacheSize=value
-XX:ReservedCodeCacheSize=value
你可以设置下列JVM参数,也可以只设置其中一个,进一步判断不同参数对CodeCache大小的影响。


很明显,CodeCache空间下降非常大,这是因为我们关闭了复杂的TieredCompilation,而且还限制了其初始大小。
- 下面就是GC部分了,就像我前面介绍的,G1等垃圾收集器其本身的设施和数据结构就非常复杂和庞大,例如Remembered Set通常都会占用20%~30%的堆空间。如果我把GC明确修改为相对简单的Serial GC,会有什么效果呢?
使用命令:
-XX:+UseSerialGC
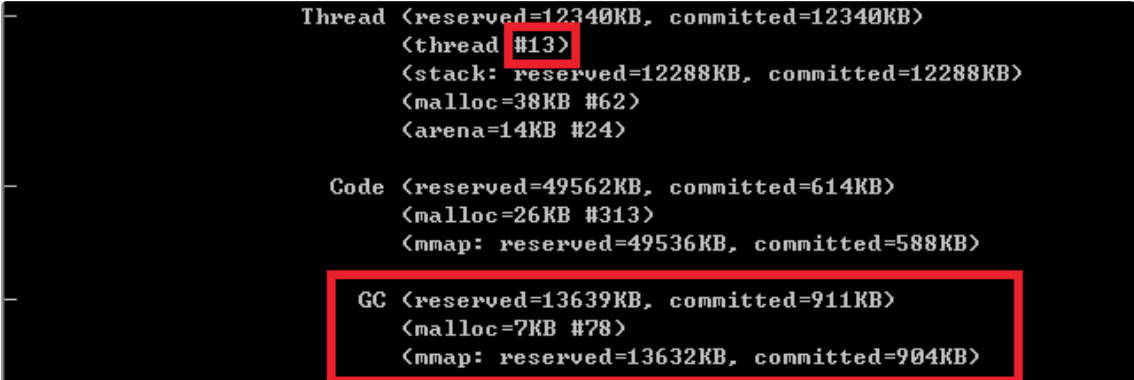
可见,不仅总线程数大大降低(25 → 13),而且GC设施本身的内存开销就少了非常多。据我所知,AWS Lambda中Java运行时就是使用的Serial GC,可以大大降低单 个function的启动和运行开销。
- Compiler部分,就是JIT的开销,显然关闭TieredCompilation会降低内存使用。
- 其他一些部分占比都非常低,通常也不会出现内存使用问题,请参考官方文档。唯一的例外就是Internal(JDK 11以后在Other部分)部分,其统计信息包含着Direct Bufer的直 接内存,这其实是堆外内存中比较敏感的部分,很多堆外内存OOM就发生在这里,请参考专栏第12讲的处理步骤。原则上Direct Bufer是不推荐频繁创建或销毁的,如果你怀疑 直接内存区域有问题,通常可以通过类似instrument构造函数等手段,排查可能的问题。
JVM内部结构就介绍到这里,主要目的是为了加深理解,很多方面只有在定制或调优JVM运行时才能真正涉及,随着微服务和Serverless等技术的兴起,JDK确实存在着为新特征的 工作负载进行定制的需求。
第27讲 | Java常见的垃圾收集器有哪些?
1)今天我要问你的问题是,Java常见的垃圾收集器有哪些?
2)典型回答
第28讲 | 谈谈你的GC调优思路?
我发现,目前不少外部资料对G1的介绍大多还停留在JDK 7或更早期的实现,很多结论已经存在较大偏差,甚至一些过去的GC选项已经不再推荐使用。所以,今天我会选取新 版JDK中的默认G1 GC作为重点进行详解,并且我会从调优实践的角度,分析典型场景和调优思路。下面我们一起来更新下这方面的知识。
1)今天我要问你的问题是,谈谈你的GC调优思路?
2)典型回答
谈到调优,这一定是针对特定场景、特定目的的事情, 对于GC调优来说,首先就需要清楚调优的目标是什么?
从性能的角度看,通常关注三个方面,内存占用(footprint)、延时 (latency)和吞吐量(throughput)。大多数情况下调优会侧重于其中一个或者两个方面的目标,很少有情况可以兼顾三个不同的角度。当然,除了上面通常的三个方面,也可能 需要考虑其他GC相关的场景,例如,OOM也可能与不合理的GC相关参数有关;或者,应用启动速度方面的需求,GC也会是个考虑的方面。
基本的调优思路可以总结为:
- 理解应用需求和问题,确定调优目标。假设,我们开发了一个应用服务,但发现偶尔会出现性能抖动,出现较长的服务停顿。评估用户可接受的响应时间和业务量,将目标简化为,希望GC暂停尽量控制在200ms以内,并且保证一定标准的吞吐量。
- 掌握JVM和GC的状态,定位具体的问题,确定真的有GC调优的必要。具体有很多方法,比如,通过jstat等工具查看GC等相关状态,可以开启GC日志,或者是利用操作系统提供的诊断工具等。例如,通过追踪GC日志,就可以查找是不是GC在特定时间发生了长时间的暂停,进而导致了应用响应不及时。
- 这里需要思考,选择的GC类型是否符合我们的应用特征,如果是,具体问题表现在哪里,是Minor GC过长,还是Mixed GC等出现异常停顿情况;如果不是,考虑切换到什么类型,如CMS和G1都是更侧重于低延迟的GC选项。
- 通过分析确定具体调整的参数或者软硬件配置。 验证是否达到调优目标,如果达到目标,即可以考虑结束调优;否则,重复完成分析、调整、验证这个过程。
3)考点分析
今天考察的GC调优问题是JVM调优的一个基础方面,很多JVM调优需求,最终都会落实在GC调优上或者与其相关,我提供的是一个常见的思路。 真正快速定位和解决具体问题,还是需要对JVM和GC知识
的掌握,以及实际调优经验的总结,有的时候甚至是源自经验积累的直觉判断。面试官可能会继续问项目中遇到的真实问题,如果你能清楚、简要地介绍其上下文,然后将诊断思路和调优实践过程表述出
来,会是个很好的加分项。
4)知识拓展
首先,先来整体了解一下G1 GC的内部结构和主要机制。 从内存区域的角度,G1同样存在着年代的概念,但是与我前面介绍的内存结构很不一样,其内部是类似棋盘状的一个个region组成,请参考下面的示意图。
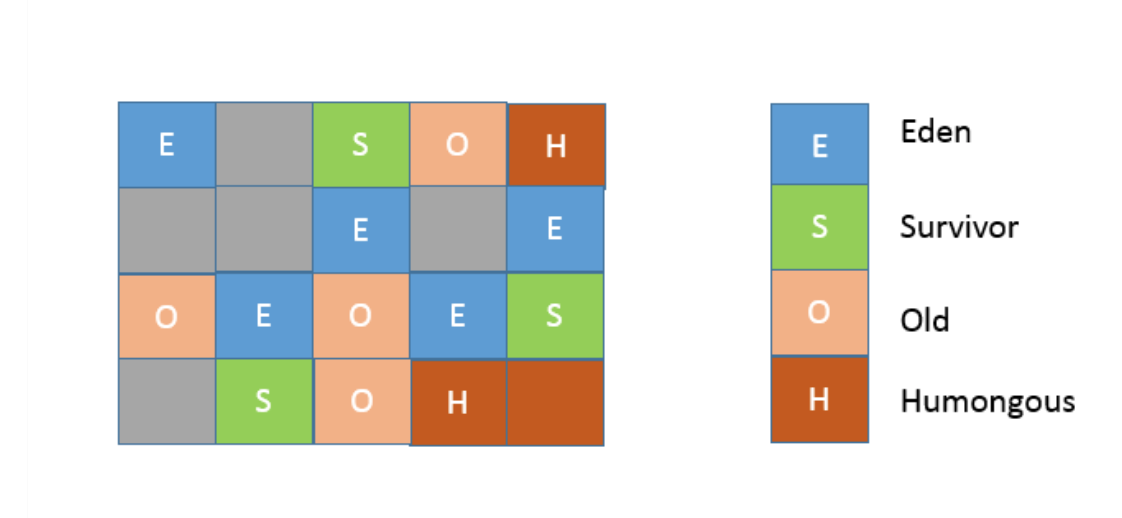
region的大小是一致的,数值是在1M到32M字节之间的一个2的幂值数,JVM会尽量划分2048个左右、同等大小的region,这点可以从源码heapRegionBounds.hpp中看到。当然这个数字既可以手动调整,G1也会根据堆大小自动进行调整。
在G1实现中,年代是个逻辑概念,具体体现在,一部分region是作为Eden,一部分作为Survivor,除了意料之中的Old region,G1会将超过region 50%大小的对象(在应用 中,通常是byte或char数组)归类为Humongous对象,并放置在相应的region中。逻辑上,Humongous region算是老年代的一部分,因为复制这样的大对象是很昂贵的操作, 并不适合新生代GC的复制算法。
你可以思考下region设计有什么副作用?
例如,region大小和大对象很难保证一致,这会导致空间的浪费。不知道你有没有注意到,我的示意图中有的区域是Humongous颜色,但没有用名称标记,这是为了表示,特别大 的对象是可能占用超过一个region的。并且,region太小不合适,会令你在分配大对象时更难找到连续空间,这是一个长久存在的情况,请参考OpenJDK社区的讨论。这本质也可 以看作是JVM的bug,尽管解决办法也非常简单,直接设置较大的region大小,参数如下:
-XX:G1HeapRegionSize=<N, 例如16>M
从GC算法的角度,G1选择的是复合算法,可以简化理解为:
- 在新生代,G1采用的仍然是并行的复制算法,所以同样会发生Stop-The-World 的暂停。
- 在老年代,大部分情况下都是并发标记,而整理(Compact)则是和新生代GC时捎带进行,并且不是整体性的整理,而是增量进行的。
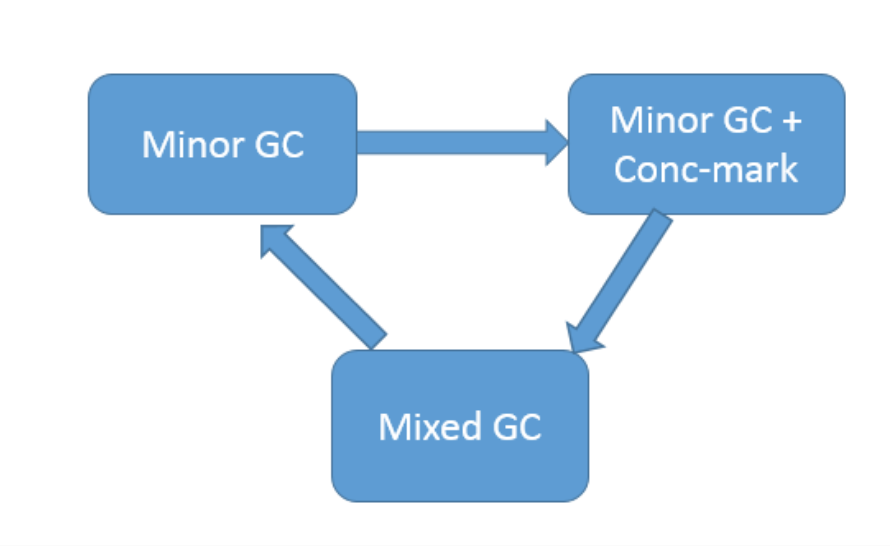
我在上一讲曾经介绍过,习惯上人们喜欢把新生代GC(Young GC)叫作Minor GC,老年代GC叫作Major GC,区别于整体性的Full GC。但是现代GC中,这种概念已经不再准 确,对于G1来说:
- Minor GC仍然存在,虽然具体过程会有区别,会涉及Remembered Set等相关处理。
- 老年代回收,则是依靠Mixed GC。并发标记结束后,JVM就有足够的信息进行垃圾收集,Mixed GC不仅同时会清理Eden、Survivor区域,而且还会清理部分Old区域。可以通 过设置下面的参数,指定触发阈值,并且设定最多被包含在一次Mixed GC中的region比例。
–XX:G1MixedGCLiveThresholdPercent –XX:G1OldCSetRegionThresholdPercent
从G1内部运行的角度,下面的示意图描述了G1正常运行时的状态流转变化,当然,在发生逃逸失败等情况下,就会触发Full GC。
G1相关概念非常多,有一个重点就是Remembered Set,用于记录和维护region之间对象的引用关系。为什么需要这么做呢?试想,新生代GC是复制算法,也就是说,类似对象 从Eden或者Survivor到to区域的“移动”,其实是“复制”,本质上是一个新的对象。在这个过程中,需要必须保证老年代到新生代的跨区引用仍然有效。下面的示意图说明了相关设 计。
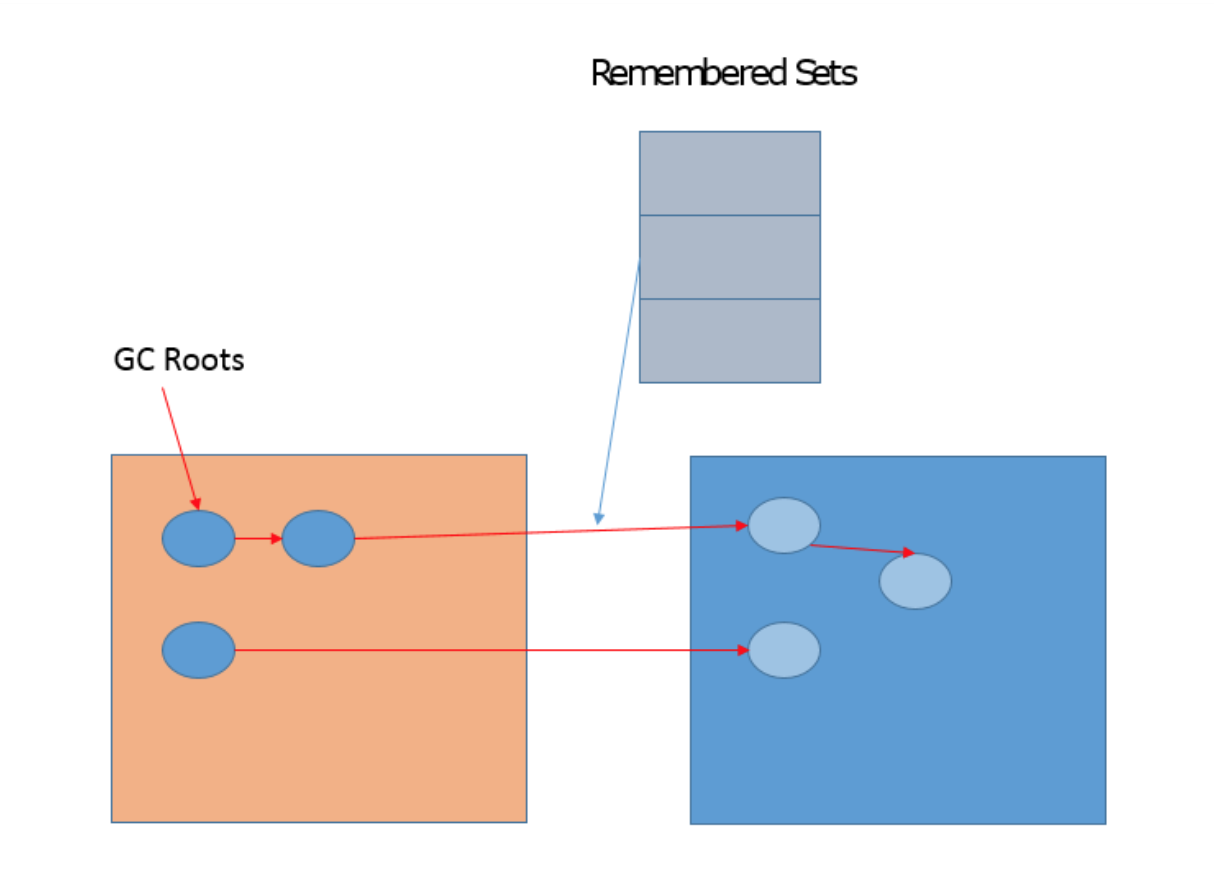
G1的很多开销都是源自Remembered Set,例如,它通常约占用Heap大小的20%或更高,这可是非常可观的比例。并且,我们进行对象复制的时候,因为需要扫描和更改Card Table 的信息,这个速度影响了复制的速度,进而影响暂停时间。
描述G1内部的资料很多,我就不重复了,如果你想了解更多内部结构和算法等,我建议参考一些具体的介绍,书籍方面我推荐Charlie Hunt等撰写的《Java Performance Companion》。
接下来,我介绍下大家可能还不了解的G1行为变化,它们在一定程度上解决了专栏其他讲中提到的部分困扰,如类型卸载不及时的问题。
- 上面提到了Humongous对象的分配和回收,这是很多内存问题的来源,Humongous region作为老年代的一部分,通常认为它会在并发标记结束后才进行回收,但是在新 版G1中,Humongous对象回收采取了更加激进的策略。 我们知道G1记录了老年代region间对象引用,Humongous对象数量有限,所以能够快速的知道是否有老年代对象引用它。如果没有,能够阻止它被回收的唯一可能,就是新生 代是否有对象引用了它,但这个信息是可以在Young GC时就知道的,所以完全可以在Young GC中就进行Humongous对象的回收,不用像其他老年代对象那样,等待并发标记 结束。
- 我在专栏第5讲,提到了在8u20以后字符串排重的特性,在垃圾收集过程中,G1会把新创建的字符串对象放入队列中,然后在Young GC之后,并发地(不会STW)将内部数据 (char数组,JDK 9以后是byte数组)一致的字符串进行排重,也就是将其引用同一个数组。你可以使用下面参数激活:
-XX:+UseStringDeduplication
注意,这种排重虽然可以节省不少内存空间,但这种并发操作会占用一些CPU资源,也会导致Young GC稍微变慢。
- 类型卸载是个长期困扰一些Java应用的问题,在专栏第25讲中,我介绍了一个类只有当加载它的自定义类加载器被回收后,才能被卸载。元数据区替换了永久代之后有所改善,但还是可能出现问题。
G1的类型卸载有什么改进吗?很多资料中都谈到,G1只有在发生Full GC时才进行类型卸载,但这显然不是我们想要的。你可以加上下面的参数查看类型卸载:
-XX:+TraceClassUnloading
幸好现代的G1已经不是如此了,8u40以后,G1增加并默认开启下面的选项:
-XX:+ClassUnloadingWithConcurrentMark
也就是说,在并发标记阶段结束后,JVM即进行类型卸载。
- 我们知道老年代对象回收,基本要等待并发标记结束。这意味着,如果并发标记结束不及时,导致堆已满,但老年代空间还没完成回收,就会触发Full GC,所以触发并发标记的 时机很重要。早期的G1调优中,通常会设置下面参数,但是很难给出一个普适的数值,往往要根据实际运行结果调整
-XX:InitiatingHeapOccupancyPercent
在JDK 9之后的G1实现中,这种调整需求会少很多,因为JVM只会将该参数作为初始值,会在运行时进行采样,获取统计数据,然后据此动态调整并发标记启动时机。对应的JVM参 数如下,默认已经开启:
-XX:+G1UseAdaptiveIHOP
- 在现有的资料中,大多指出G1的Full GC是最差劲的单线程串行GC。其实,如果采用的是最新的JDK,你会发现Full GC也是并行进行的了,在通用场景中的表现还优于Parallel GC的Full GC实现。
当然,还有很多其他的改变,比如更快的Card Table扫描等,这里不再展开介绍,因为它们并不带来行为的变化,基本不影响调优选择。
前面介绍了G1的内部机制,并且穿插了部分调优建议,下面从整体上给出一些调优的建议。
首先,建议尽量升级到较新的JDK版本,从上面介绍的改进就可以看到,很多人们常常讨论的问题,其实升级JDK就可以解决了。
第二,掌握GC调优信息收集途径。掌握尽量全面、详细、准确的信息,是各种调优的基础,不仅仅是GC调优。我们来看看打开GC日志,这似乎是很简单的事情,可是你确定真的掌握了吗?
除了常用的两个选项,
-XX:+PrintGCDetails -XX:+PrintGCDateStamps
还有一些非常有用的日志选项,很多特定问题的诊断都是要依赖这些选项:
-XX:+PrintAdaptiveSizePolicy // 打印G1 Ergonomics相关信息
我们知道GC内部一些行为是适应性的触发的,利用PrintAdaptiveSizePolicy,我们就可以知道为什么JVM做出了一些可能我们不希望发生的动作。例如,G1调优的一个基本建议就 是避免进行大量的Humongous对象分配,如果Ergonomics信息说明发生了这一点,那么就可以考虑要么增大堆的大小,要么直接将region大小提高。
如果是怀疑出现引用清理不及时的情况,则可以打开下面选项,掌握到底是哪里出现了堆积。
-XX:+PrintReferenceGC
另外,建议开启选项下面的选项进行并行引用处理。
-XX:+ParallelRefProcEnabled
需要注意的一点是,JDK 9中JVM和GC日志机构进行了重构,其实我前面提到的PrintGCDetails已经被标记为废弃,而PrintGCDateStamps已经被移除,指定它会导致JVM无法启 动。可以使用下面的命令查询新的配置参数。
java -Xlog:help
最后,来看一些通用实践,理解了我前面介绍的内部结构和机制,很多结论就一目了然了,例如:
(1)如果发现Young GC非常耗时,这很可能就是因为新生代太大了,我们可以考虑减小新生代的最小比例。
-XX:G1NewSizePercent
降低其最大值同样对降低Young GC延迟有帮助。
-XX:G1MaxNewSizePercent
如果我们直接为G1设置较小的延迟目标值,也会起到减小新生代的效果,虽然会影响吞吐量。
(2)如果是Mixed GC延迟较长,我们应该怎么做呢?
还记得前面说的,部分Old region会被包含进Mixed GC,减少一次处理的region个数,就是个直接的选择之一。 我在上面已经介绍了G1OldCSetRegionThresholdPercent控制其最大值,还可以利用下面参数提高Mixed GC的个数,当前默认值是8,Mixed GC数量增多,意味着每次被包含 的region减少。
-XX:G1MixedGCCountTarget
今天的内容算是抛砖引玉,更多内容你可以参考G1调优指南等,远不是几句话可以囊括的。需要注意的是,也要避免过度调优,G1对大堆非常友好,其运行机制也需要浪费一定的 空间,有时候稍微多给堆一些空间,比进行苛刻的调优更加实用。
今天我梳理了基本的GC调优思路,并对G1内部结构以及最新的行为变化进行了详解。总的来说,G1的调优相对简单、直观,因为可以直接设定暂停时间等目标,并且其内部引入了 各种智能的自适应机制,希望这一切的努力,能够让你在日常应用开发时更加高效。
第29讲 | Java内存模型中的happen-before是什么?
- 线程内执行的每个操作,都保证happen-before后面的操作,这就保证了基本的程序顺序规则,这是开发者在书写程序时的基本约定。
- 对于volatile变量,对它的写操作,保证happen-before在随后对该变量的读取操作。
- 对于一个锁的解锁操作,保证happen-before加锁操作。
- 对象构建完成,保证happen-before于fnalizer的开始动作。
- 甚至是类似线程内部操作的完成,保证happen-before其他Thread.join()的线程等。
Java是最早尝试提供内存模型的语言,这是简化多线程编程、保证程序可移植性的一个飞跃。早期类似C、C++等语言,并不存在内存模型的概念(C++ 11中也引入了标准内存模型),其行为依赖于处理器本身的内存一致性模型,但不同的处理器可能差异很大,所以一段C++程序在处理器A上运行正常,并不能保证其在处理器B上也是一致的。
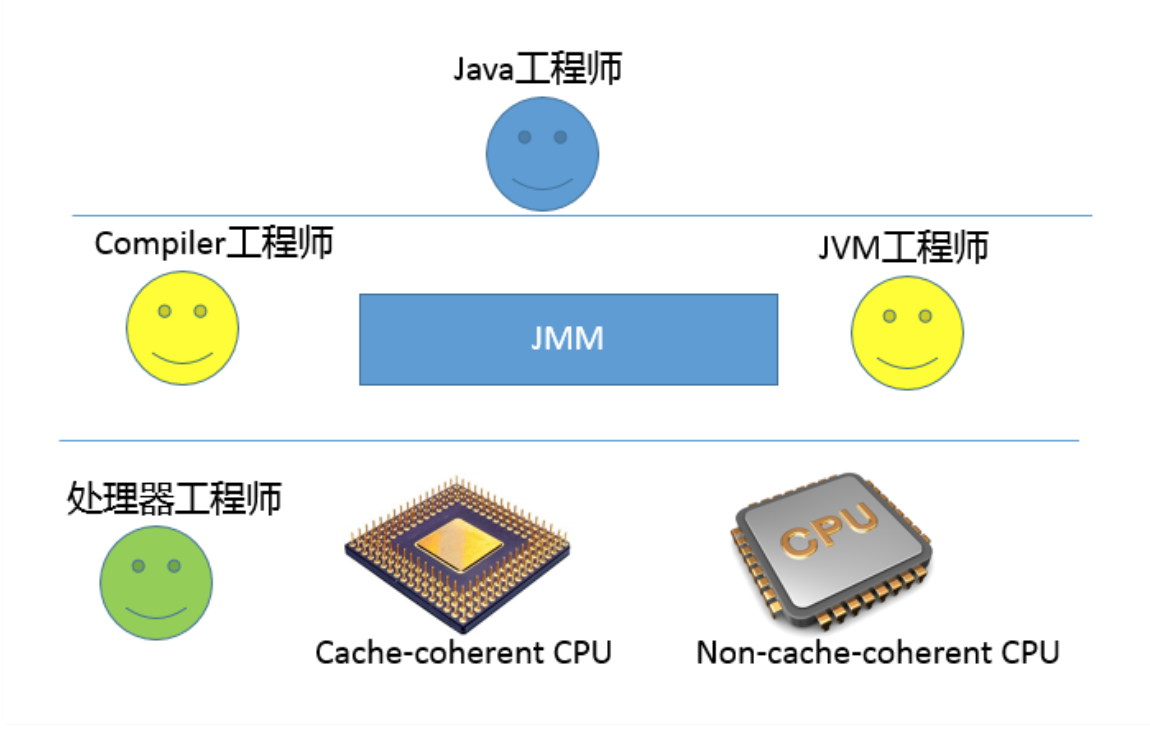
Java迫切需要一个完善的JMM,能够让普通Java开发者和编译器、JVM工程师,能够清晰地达成共识。换句话说,可以相对简单并准确地判断出,多线程程序什么样的执行序 列是符合规范的。
所以:
- 对于编译器、JVM开发者,关注点可能是如何使用类似内存屏障(Memory-Barrier)之类技术,保证执行结果符合JMM的推断。
- 对于Java应用开发者,则可能更加关注volatile、synchronized等语义,如何利用类似happen-before的规则,写出可靠的多线程应用,而不是利用一些“秘籍”去糊弄编译器、JVM。
JMM是怎么解决可见性等问题的呢?
在这里,我有必要简要介绍一下典型的问题场景。
我在第25讲里介绍了JVM内部的运行时数据区,但是真正程序执行,实际是要跑在具体的处理器内核上。你可以简单理解为,把本地变量等数据从内存加载到缓存、寄存器,然后运 算结束写回主内存。你可以从下面示意图,看这两种模型的对应。
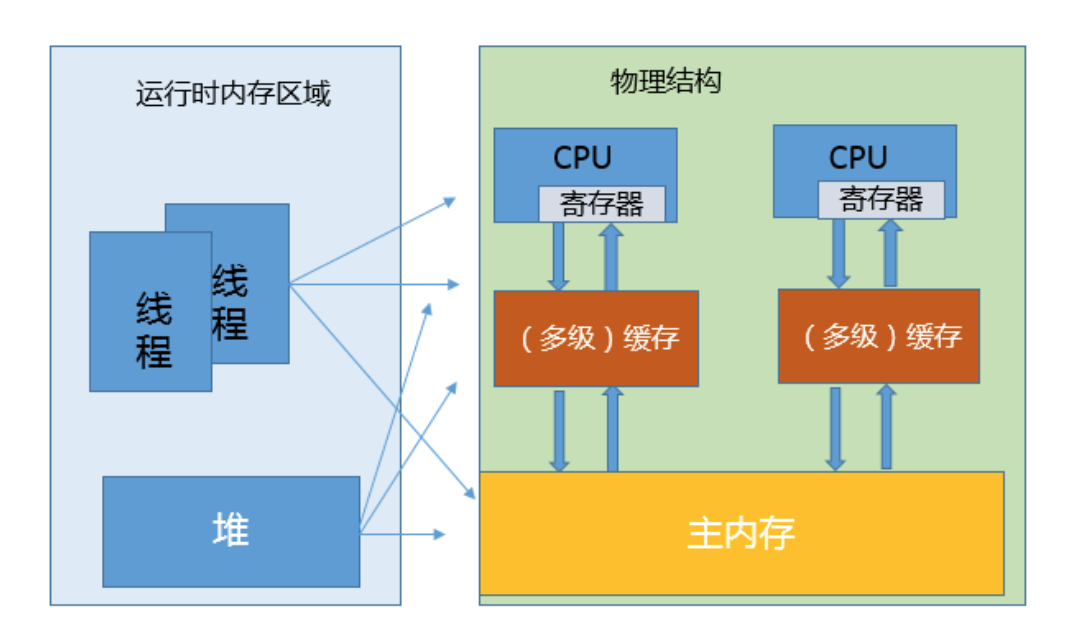
看上去很美好,但是当多线程共享变量时,情况就复杂了。试想,如果处理器对某个共享变量进行了修改,可能只是体现在该内核的缓存里,这是个本地状态,而运行在其他内核上 的线程,可能还是加载的旧状态,这很可能导致一致性的问题。从理论上来说,多线程共享引入了复杂的数据依赖性,不管编译器、处理器怎么做重排序,都必须尊重数据依赖性的 要求,否则就打破了正确性!这就是JMM所要解决的问题。
JMM内部的实现通常是依赖于所谓的内存屏障,通过禁止某些重排序的方式,提供内存可见性保证,也就是实现了各种happen-before规则。与此同时,更多复杂度在于,需要尽量确保各种编译器、各种体系结构的处理器,都能够提供一致的行为。
我以volatile为例,看看如何利用内存屏障实现JMM定义的可见性?
对于一个volatile变量:
- 对该变量的写操作之后,编译器会插入一个写屏障。
- 对该变量的读操作之前,编译器会插入一个读屏障。
内存屏障能够在类似变量读、写操作之后,保证其他线程对volatile变量的修改对当前线程可见,或者本地修改对其他线程提供可见性。换句话说,线程写入,写屏障会通过类似强迫 刷出处理器缓存的方式,让其他线程能够拿到最新数值。
第30讲 | Java程序运行在Docker等容器环境有哪些新问题?
- 如果未配置合适的JVM堆和元数据区、直接内存等参数,Java就有可能试图使用超过容器限制的内存,最终被容器OOM kill,或者自身发生OOM。
- 错误判断了可获取的CPU资源,例如,Docker限制了CPU的核数,JVM就可能设置不合适的GC并行线程数等。 从应用打包、发布等角度出发,JDK自身就比较大,生成的镜像就更为臃肿,当我们的镜像非常多的时候,镜像的存储等开销就比较明显了。
如果考虑到微服务、Serverless等新的架构和场景,Java自身的大小、内存占用、启动速度,都存在一定局限性,因为Java早期的优化大多是针对长时间运行的大型服务器端应用。
第31讲 | 你了解Java应用开发中的注入攻击吗?
Java工程师未必都要成为安全专家,但了解基础的安全领域常识,有利于发现和规避日常开发中的风险。今天我会侧重和Java开发相关的安全内容,希望可以起到一个抛砖引玉的作
用,让你对Java开发安全领域有个整体印象。 谈到Java应用安全,主要涉及哪些安全机制? 到底什么是安全漏洞?对于前面提到的SQL注入等典型攻击,我们在开发中怎么避免?
第32讲 | 如何写出安全的Java代码?
2)典型回答
- 如果使用的是早期的JDK和Applet等技术,攻击者构建合法但恶劣的程序就相对容易,例如,将其线程优先级设置为最高,做一些看起来无害但空耗资源的事情。幸运的是类似技 术已经逐步退出历史舞台,在JDK 9以后,相关模块就已经被移除。
- 上一讲中提到的哈希碰撞攻击,就是个典型的例子,对方可以轻易消耗系统有限的CPU和线程资源。从这个角度思考,类似加密、解密、图形处理等计算密集型任务,都要防范被 恶意滥用,以免攻击者通过直接调用或者间接触发方式,消耗系统资源。
- 利用Java构建类似上传文件或者其他接受输入的服务,需要对消耗系统内存或存储的上限有所控制,因为我们不能将系统安全依赖于用户的合理使用。其中特别注意的是涉及解压 缩功能时,就需要防范Zip bomb等特定攻击。
- 另外,Java程序中需要明确释放的资源有很多种,比如文件描述符、数据库连接,甚至是再入锁,任何情况下都应该保证资源释放成功,否则即使平时能够正常运行,也可能被攻 击者利用而耗尽某类资源,这也算是可能的DoS攻击来源。
3)考点分析
4)知识拓展
这种暴露还可能通过其他方式发生,比如某著名的编程技术网站,就被曝光过所有用户名和密码。这些信息都是明文存储,传输过程也未必进行加密,类似这种情况,暴露只是个时 间早晚的问题。
对于安全标准特别高的系统,甚至可能要求敏感信息被使用后,要立即明确在内存中销毁,以免被探测;或者避免在发生core dump时,意外暴露。
- 敏感信息不要被序列化!在编码中,建议使用transient关键字将其保护起来。
- 反序列化中,建议在readObject中实现与对象构件过程相同的安全检查和数据检查。
第33讲 | 后台服务出现明显“变慢”,谈谈你的诊断思路?
首先,我们来了解一下业界最广泛的性能分析方法论。 根据系统架构不同,分布式系统和大型单体应用也存在着思路的区别,例如,分布式系统的性能瓶颈可能更加集中。传统意义上的性能调优大多是针对单体应用的调优,专栏的侧重点也是如此,Charlie Hunt曾将其方法论总结为两类:
- 自上而下。从应用的顶层,逐步深入到具体的不同模块,或者更近一步的技术细节单元,找到可能的问题和解决办法。这是最常见的性能分析思路,也是大多数工程师的选择。
- 自下而上。从类似CPU这种硬件底层,判断类似Cache-Miss之类的问题和调优机会,出发点是指令级别优化。这往往是专业的性能工程师才能掌握的技能,并且需要专业工具配 合,大多数是移植到新的平台上,或需要提供极致性能时才会进行。
如果每秒上下文(cs,context switch)切换很高,并且比系统中断高很多(in,system interrupt),就表明很有可能是因为不合理的多线程调度所导致。当然还需要利 用pidstat等手段,进行更加具体的定位,我就不再进一步展开了。
除了CPU,内存和IO是重要的注意事项,比如: 利用free之类查看内存使用。
或者,进一步判断swap使用情况,top命令输出中Virt作为虚拟内存使用量,就是物理内存(Res)和swap求和,所以可以反推swap使用。显然,JVM是不希望发生大量 的swap使用的。
对于IO问题,既可能发生在磁盘IO,也可能是网络IO。例如,利用iostat等命令有助于判断磁盘的健康状况。我曾经帮助诊断过Java服务部署在国内的某云厂商机器上,其原因 就是IO表现较差,拖累了整体性能,解决办法就是申请替换了机器。
讲到这里,如果你对系统性能非常感兴趣,我建议参考Brendan Gregg提供的完整图谱。
第34讲 | 有人说“Lambda能让Java程序慢30倍”,你怎么看?
我认为,当需要对一个大型软件的某小部分的性能进行评估时,就可以考虑微基准测试。换句话说,微基准测试大多是API级别的验证,或者与其他简单用例场景的对比,例如:
你在开发共享类库,为其他模块提供某种服务的API等。 你的API对于性能,如延迟、吞吐量有着严格的要求,例如,实现了定制的HTTP客户端API,需要明确它对HTTP服务器进行大量GET请求时的吞吐能力,或者需要对比其他API,
保证至少对等甚至更高的性能标准。
所以微基准测试更是偏基础、底层平台开发者的需求,当然,也是那些追求极致性能的前沿工程师的最爱。
如何构建自己的微基准测试,选择什么样的框架比较好?
目前应用最为广泛的框架之一就是JMH,OpenJDK自身也大量地使用JMH进行性能对比,如果你是做Java API级别的性能对比,JMH往往是你的首选。
JMH是由Hotspot JVM团队专家开发的,除了支持完整的基准测试过程,包括预热、运行、统计和报告等,还支持Java和其他JVM语言。更重要的是,它针对Hotspot JVM提供了 各种特性,以保证基准测试的正确性,整体准确性大大优于其他框架,并且,JMH还提供了用近乎白盒的方式进行Profling等工作的能力。
使用JMH也非常简单,你可以直接将其依赖加入Maven工程,如下图:
第35讲 | JVM优化Java代码时都做了什么?
JVM在对代码执行的优化可分为运行时(runtime)优化和即时编译器(JIT)优化。
- 运行时优化主要是解释执行和动态编译通用的一些机制,比如说锁机制(如偏斜锁)、内存分配机制(如TLAB)等。除此之外,还有一些专门用于优化解释执行效率的,比如说模版解释器、内联缓存(inline cache,用于优化虚方法调用的动态绑定)。
- JVM的即时编译器优化是指将热点代码以方法为单位转换成机器码,直接运行在底层硬件之上。它采用了多种优化方式,包括静态编译器可以使用的如方法内联、逃逸分析,也包括基于程序运行profle的投机性优化(speculative/optimistic optimization)。
这个怎么理解呢?比如我有一条instanceof指令,在编译之前的执行过程中,测试对象的类一直是同一个,那么即时编译器可以假设编译之后的执行过程中还会是这一个类,并且根据这个类直接返回instanceof的结果。如果出现了其他类,那么就抛弃这段编译后的机器码,并且切换回解释执行。
第35讲 | 一份Java工程师必读书单
《Netty实战》
《Cloud Native Java》
《大型分布式网站架构设计与实践》
《深入分布式缓存:从原理到实践》
Charlie Hunt编撰的《Java Performance》或者Scott Oaks的《Java Performance:The Defnitive Guide》
第36讲 | 谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景?
反映到MySQL数据库应用开发中,悲观锁一般就是利用类似SELECT ... FOR UPDATE这样的语句,对数据加锁,避免其他事务意外修改数据。
乐观锁则与Java并发包中的AtomicFieldUpdater类似,也是利用CAS机制,并不会对数据加锁,而是通过对比数据的时间戳或者版本号,来实现乐观锁需要的版本判断。
我认为前面提到的MVCC,其本质就可以看作是种乐观锁机制,而排他性的读写锁、双阶段锁等则是悲观锁的实现。 有关它们的应用场景,你可以构建一下简化的火车余票查询和购票系统。同时查询的人可能很多,虽然具体座位票只能是卖给一个人,但余票可能很多,而且也并不能预测哪个查询者会购票,这个时候就更适合用乐观锁。
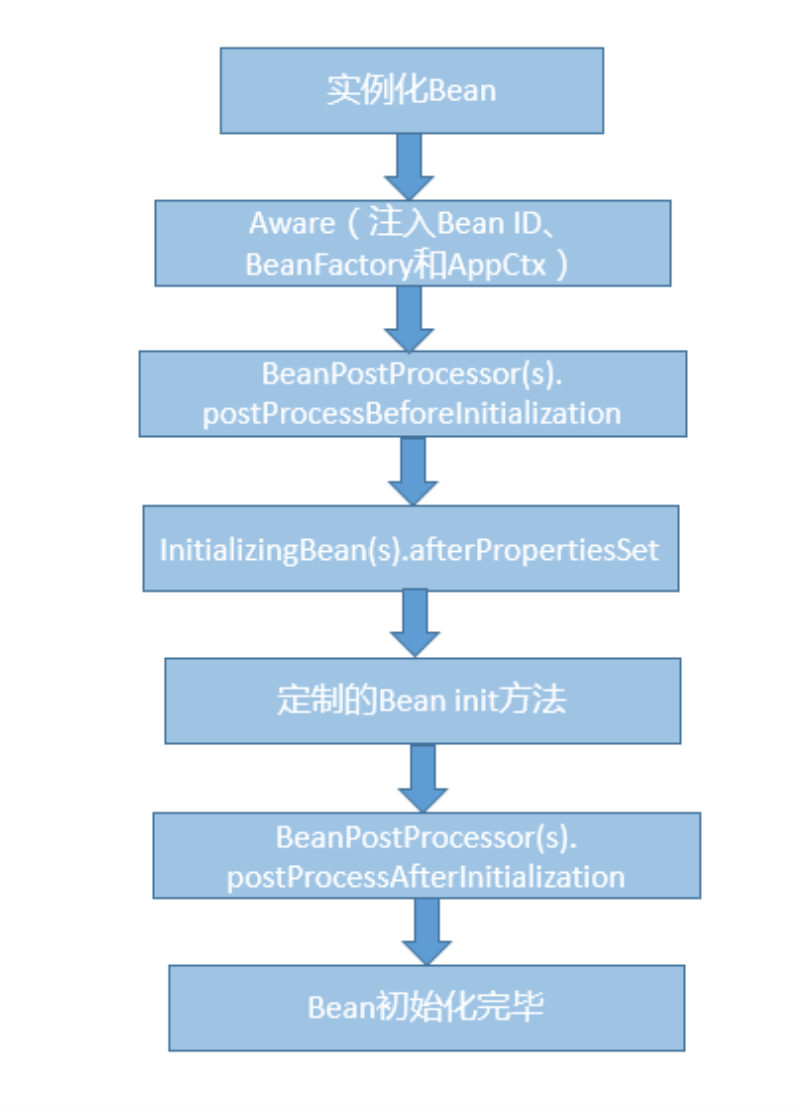
第37讲 | 谈谈Spring Bean的生命周期和作用域?
第38讲 | 对比Java标准NIO类库,你知道Netty是如何实现更高性能的吗?
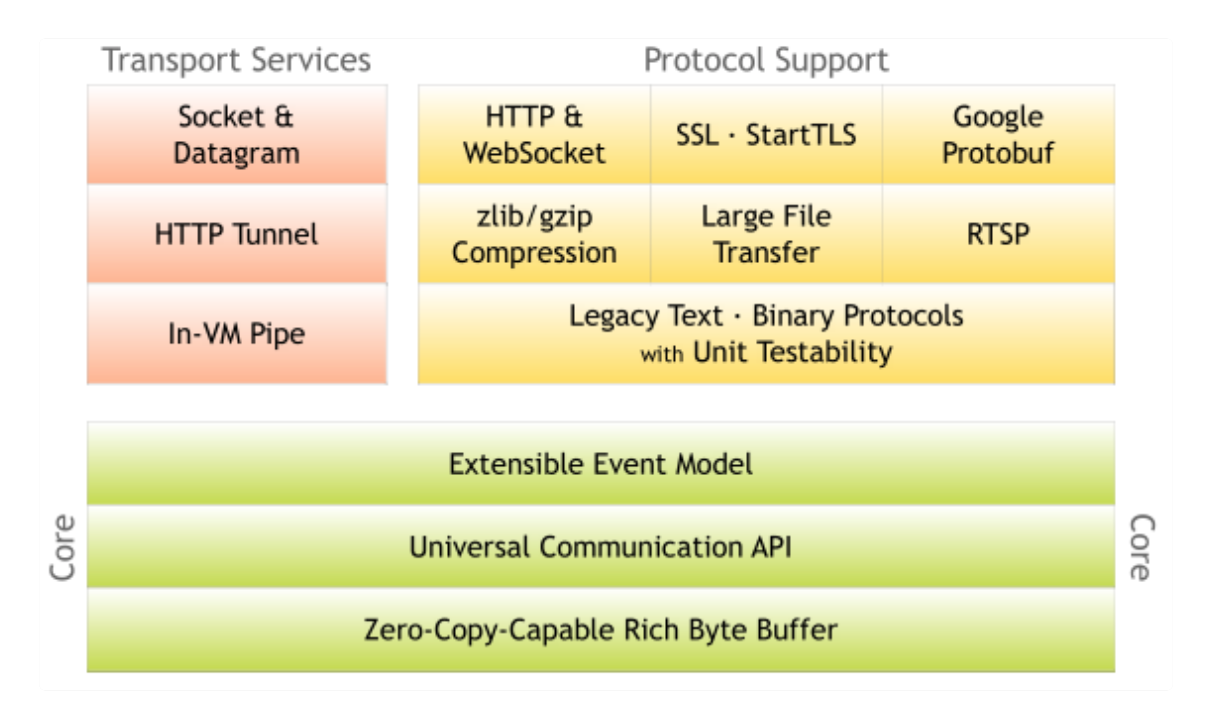
单独从性能角度,Netty在基础的NIO等类库之上进行了很多改进,例如:
- 更加优雅的Reactor模式实现、灵活的线程模型、利用EventLoop等创新性的机制,可以非常高效地管理成百上千的Channel。
- 充分利用了Java的Zero-Copy机制,并且从多种角度,“斤斤计较”般的降低内存分配和回收的开销。例如,使用池化的Direct Bufer等技术,在提高IO性能的同时,减少了对象的创建和销毁;利用反射等技术直接操纵SelectionKey,使用数组而不是Java容器等。
- 使用更多本地代码。例如,直接利用JNI调用Open SSL等方式,获得比Java内建SSL引擎更好的性能。
- 在通信协议、序列化等其他角度的优化。
这是一个比较开放的问题,我给出的回答是个概要性的举例说明。面试官很可能利用这种开放问题作为引子,针对你回答的一个或者多个点,深入探讨你在不同层次上的理解程度。 在面试准备中,兼顾整体性的同时,不要忘记选定个别重点进行深入理解掌握,最好是进行源码层面的深入阅读和实验。如果你希望了解更多从性能角度Netty在编码层面的手段,
可以参考Norman在Devoxx上的分享,其中的很多技巧对于实现极致性能的API有一定借鉴意义,但在一般的业务开发中要谨慎采用。
4)知识拓展
除了核心的事件机制等,Netty还额外提供了很多功能,例如:
- 从网络协议的角度,Netty除了支持传输层的UDP、TCP、SCTP协议,也支持HTTP(s)、WebSocket等多种应用层协议,它并不是单一协议的API。
- 在应用中,需要将数据从Java对象转换成为各种应用协议的数据格式,或者进行反向的转换,Netty为此提供了一系列扩展的编解码框架,与应用开发场景无缝衔接,并且性能良好。
- 它扩展了Java NIO Bufer,提供了自己的ByteBuf实现,并且深度支持Direct Bufer等技术,甚至hack了Java内部对Direct Bufer的分配和销毁等。同时,Netty也提供了更加完善的Scatter/Gather机制实现。
可以看到,Netty的能力范围大大超过了Java核心类库中的NIO等API,可以说它是一个从应用视角出发的产物。
第39讲 | 谈谈常用的分布式ID的设计方案?Snowfake是否受冬令时切换影响?
- 全局唯一,区别于单点系统的唯一,全局是要求分布式系统内唯一。
- 有序性,通常都需要保证生成的ID是有序递增的。例如,在数据库存储等场景中,有序ID便于确定数据位置,往往更加高效。
目前业界的方案很多,典型方案包括:
- 基于数据库自增序列的实现。这种方式优缺点都非常明显,好处是简单易用,但是在扩展性和可靠性等方面存在局限性。
- 基于Twitter 早期开源的Snowfake的实现,以及相关改动方案。这是目前应用相对比较广泛的一种方式,其结构定义你可以参考下面的示意图。
头部是1位的正负标识位。
紧跟着的高位部分包含41位时间戳,通常使用System.currentTimeMillis()。
后面是10位的WorkerID,标准定义是5位数据中心 + 5位机器ID,组成了机器编号,以区分不同的集群节点。
最后的12位就是单位毫秒内可生成的序列号数目的理论极限。
Snowfake的官方版本是基于Scala语言,Java等其他语言的参考实现有很多,是一种非常简单实用的方式,具体位数的定义是可以根据分布式系统的真实场景进行修改的,并不一 定要严格按
照示意图中的设计。
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号