《Java架构师的第一性原理》41存储之MySQL第11篇数据库调优
1 MySQL死锁分析
1.1 InnoDB调试死锁的方法
1)【配置的确认与修改】
要测试InnoDB的锁互斥,以及死锁,有几个配置务必要提前确认:
-
区间锁是否关闭
-
事务自动提交(auto commit)是否关闭
-
事务的隔离级别(isolation level)
间隙锁是否关闭
区间锁(间隙锁,临键锁)是InnoDB特有施加在索引记录区间的锁,MySQL5.6可以手动关闭区间锁,它由innodb_locks_unsafe_for_binlog参数控制:
-
设置为ON,表示关闭区间锁,此时一致性会被破坏(所以是unsafe)
-
设置为OFF,表示开启区间锁
事务自动提交
MySQL默认把每一个单独的SQL语句作为一个事务,自动提交。
事务的隔离级别
不同事务的隔离级别,InnoDB的锁实现是不一样。
-- 查询间隙锁是否关闭,默认为OFF
show global variables like "innodb_locks%";
-- 查询事务是否自动提交,默认为ON
show global variables like "autocommit";
-- 查询事务的隔离级别,默认为REPEATABLE-READ
show global variables like "tx_isolation";
-- 设置事务手动控制
set session autocommit=0;
-- 设置事务的隔离级别
set session transaction isolation level X;
X取:
read uncommitted
read committed
repeatable read
serializable
2)做实验
【实验一,间隙锁互斥】
【实验二,共享排他锁死锁】
【实验三,并发间隙锁的死锁】
锁的调试:
-
并发事务,间隙锁可能互斥
(1)A删除不存在的记录,获取共享间隙锁;
(2)B插入,必须获得排他间隙锁,故互斥;
-
并发插入相同记录,可能死锁(某一个回滚)
-
并发插入,可能出现间隙锁死锁(难排查)
-
show engine innodb status; 可以查看InnoDB的锁情况,也可以调试死锁
2)工具1:查询锁的情况
show engine innodb status;
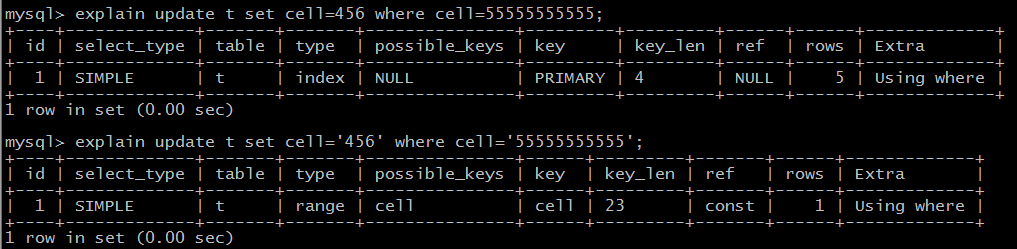
3)工具2:explain
explain update t set cell=456 where cell=55555555555;
explain update t set cell= '456 ' where cell= '55555555555 ';
死锁是MySQL中非常难调试的问题,常见的思路与方法有:
(1)通过多终端模拟并发事务,复现死锁;
(2)通过show engine innodb status; 可以查看事务与锁的信息;
(3)通过explain可以查看执行计划;
2 MySQL中索引失效的常见场景与规避方法
2.1 两类非常隐蔽的全表扫描,不能命中索引
第一类:“列类型”与“where值类型”不符,不能命中索引,会导致全表扫描(full table scan)。
第二类:相join的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算(nested loop)。
2.2 数据库允许空值(null),往往是悲剧的开始
-- 1. 准备数据
create table user (
id int,
name varchar(20),
index(id)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
-- 知识点1:负向查询不能命中索引,会导致全表扫描
explain select * from user where id!=1;
-- 插入id为NULL的一行记录
insert into user(name) values('wangwu');
-- 知识点2:允许空值,不等于(!=)查询,可能导致不符合预期的结果,建表时加上默认(default)值,这样能避免空值的坑;
explain select * from user where id!=1;
-- 预期结果有3条数据,实际只有2条数据
select * from user where id!=1;
-- 获取正确结果的SQL
select * from user where id!=1 or id is null;
-- 知识点3:某些or条件,又可能导致全表扫描,此时应该优化为union
explain select * from user where id=1;
explain select * from user where id is null;
explain select * from user where id=1 or id is null;
explain select * from user where id=1
union
select * from user where id is null;
4 Explain查看执行计划
4.1 explain的type
create table user (
id int primary key,
name varchar(20)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
create table user_ex (
id int primary key,
age int
)engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);
-- explain结果中的type字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式
-- system
explain select * from mysql.time_zone;
explain select * from (select * from user where id=1) tmp;
-- const
explain select * from user where id = 1;
-- eq_ref
explain select * from user,user_ex where user.id=user_ex.id;
-- ref
explain select * from user,user_ex where user.id=user_ex.id;
-- range
explain select * from user where id between 1 and 4;
explain select * from user where id in(1,2,3);
explain select * from user where id>3;
-- index
explain select count(*) from user;
-- ALL
explain select * from user,user_ex where user.id=user_ex.id;
4.2 explain的Extra
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
insert into user values(1, 'shenjian','no');
insert into user values(2, 'zhangsan','no');
insert into user values(3, 'lisi', 'yes');
insert into user values(4, 'lisi', 'no');
-- explain的Extra字段
-- 【Using where】
explain select * from user where sex='no';
-- 【Using index】
explain select id,name from user where name='shenjian';
-- 【Using index condition】,如何优化为Using index呢?
explain select id,name,sex from user
where name='shenjian';
-- 【Using filesort】
explain select * from user order by sex;
-- 【Using temporary】
explain select * from user group by name order by sex;
-- 【Using join buffer (Block Nested Loop)】
explain select * from user where id in(select id from user where sex='no');
4.3 回表查询和索引覆盖
1)什么是回表查询
所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
2)什么是索引覆盖
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
3)如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
-- Extra:Using index
explain select id,name from user where name='shenjian';
-- Extra:Using index condition
explain select id,name,sex from user where name='shenjian';
-- 把(name)单列索引升级为联合索引(name, sex)
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;
4)哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
场景2:列查询回表优化
场景3:分页查询
5 慢查询定位
5.1 慢查询日志概念
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10S以上的语句。默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
5.2 慢查询日志相关参数
MySQL 慢查询的相关参数解释:slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭。
slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭。 log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志。 log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。 log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据<br>库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需<br>要能够获得更高的系统性能,那么建议优先记录到文件。
慢查询日志配置
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启,如下所示:
mysql> show variables like '%slow_query_log%'; +---------------------+------------------------------------------+ | Variable_name | Value | +---------------------+------------------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /usr/local/mysql/data/localhost-slow.log | +---------------------+------------------------------------------+ 2 rows in set (0.00 sec) mysql> set global slow_query_log=1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like '%slow_query_log%'; +---------------------+------------------------------------------+ | Variable_name | Value | +---------------------+------------------------------------------+ | slow_query_log | ON | | slow_query_log_file | /usr/local/mysql/data/localhost-slow.log | +---------------------+------------------------------------------+ 2 rows in set (0.00 sec) #使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,MySQL重启后则会失效。如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)
修改my.cnf文件,增加或修改参数slow_query_log 和slow_query_log_file后,然后重启MySQL服务器,如下所示:
slow_query_log =1 slow_query_log_file=/usr/local/mysql/data/localhost-slow.log mysql> show variables like 'slow_query%'; +---------------------+---------------------+ | Variable_name | Value | +---------------------+---------------------+ | slow_query_log | ON | | slow_query_log_file | /usr/local/mysql/data/localhost-slow.log | +---------------------+---------------------+ 2 rows in set (0.00 sec) mysql> #慢查询的参数slow_query_log_file ,它指定慢查询日志文件的存放路径,系统默认会给一个缺省的文件host_name-slow.log
那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢? 这个是由参数long_query_time控制,默认情况下long_query_time的值为10秒,可以使用命令修改,也可以在my.cnf参数里面修改。关于运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。从MySQL 5.1开始,long_query_time开始以微秒记录SQL语句运行时间,之前仅用秒为单位记录。如果记录到表里面,只会记录整数部分,不会记录微秒部分。
mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql> mysql> set global long_query_time=4; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql>
如上所示,我修改了变量long_query_time,但是查询变量long_query_time的值还是10,难道没有修改到呢?注意:使用命令 set global long_query_time=4修改后,需要重新连接或新开一个会话才能看到修改值。你用show variables like 'long_query_time'查看是当前会话的变量值,你也可以不用重新连接会话,而是用show global variables like 'long_query_time'; 如下所示:
mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql> mysql> show global variables like 'long_query_time'; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 4.000000 | +-----------------+----------+ 1 row in set (0.00 sec) mysql>
log_output 参数是指定日志的存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件.
mysql> show variables like '%log_output%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_output | TABLE | +---------------+-------+ 1 row in set (0.00 sec) mysql>
系统变量log-queries-not-using-indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。如果调优的话,建议开启这个选项。另外,开启了这个参数,其实使用full index scan的sql也会被记录到慢查询日志。
mysql> show variables like 'log_queries_not_using_indexes'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | log_queries_not_using_indexes | OFF | +-------------------------------+-------+ 1 row in set (0.00 sec) mysql> set global log_queries_not_using_indexes=1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'log_queries_not_using_indexes'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | log_queries_not_using_indexes | ON | +-------------------------------+-------+ 1 row in set (0.00 sec) mysql>
系统变量log_slow_admin_statements表示是否将慢管理语句例如ANALYZE TABLE和ALTER TABLE等记入慢查询日志
mysql> show variables like 'log_slow_admin_statements'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | log_slow_admin_statements | OFF | +---------------------------+-------+ 1 row in set (0.00 sec) mysql>
另外,如果你想查询有多少条慢查询记录,可以使用系统变量。
mysql> show global status like '%slow_queries%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Slow_queries | 0 | +---------------+-------+ 1 row in set (0.00 sec) mysql>
5.3 日志分析工具mysqldumpslow
在实际生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具mysqldumpslow
查看mysqldumpslow的帮助信息:
[root@DB-Server ~]# mysqldumpslow --help Usage: mysqldumpslow [ OPTS... ] [ LOGS... ] Parse and summarize the MySQL slow query log. Options are --verbose verbose --debug debug --help write this text to standard output -v verbose -d debug -s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default al: average lock time ar: average rows sent at: average query time c: count l: lock time r: rows sent t: query time -r reverse the sort order (largest last instead of first) -t NUM just show the top n queries -a don't abstract all numbers to N and strings to 'S' -n NUM abstract numbers with at least n digits within names -g PATTERN grep: only consider stmts that include this string -h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard), default is '*', i.e. match all -i NAME name of server instance (if using mysql.server startup script) -l don't subtract lock time from total time
-s, 是表示按照何种方式排序 c: 访问计数 l: 锁定时间 r: 返回记录 t: 查询时间 al:平均锁定时间 ar:平均返回记录数 at:平均查询时间 -t, 是top n的意思,即为返回前面多少条的数据; -g, 后边可以写一个正则匹配模式,大小写不敏感的; 比如: 得到返回记录集最多的10个SQL。 mysqldumpslow -s r -t 10 /database/mysql/mysql06_slow.log 得到访问次数最多的10个SQL mysqldumpslow -s c -t 10 /database/mysql/mysql06_slow.log 得到按照时间排序的前10条里面含有左连接的查询语句。 mysqldumpslow -s t -t 10 -g “left join” /database/mysql/mysql06_slow.log 另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现刷屏的情况。 mysqldumpslow -s r -t 20 /mysqldata/mysql/mysql06-slow.log | more
6 show profile查看执行时间
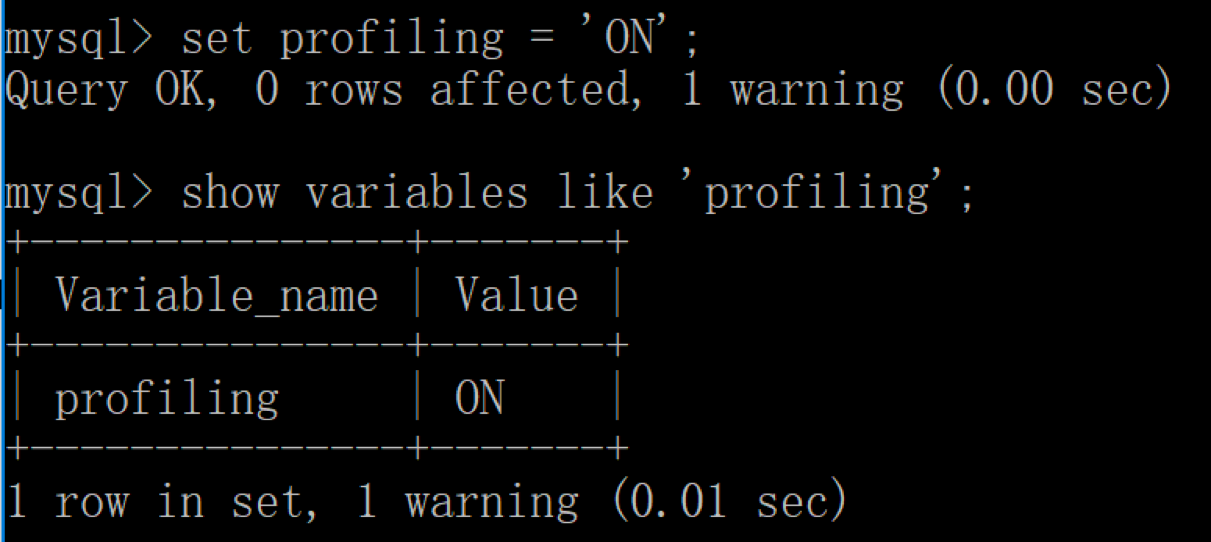
SHOW PROFILE 相比 EXPLAIN 能看到更进一步的执行解析,包括 SQL 都做了什么、所花费的时间等。默认情况下,profiling 是关闭的,我们可以在会话级别开启这个功能。
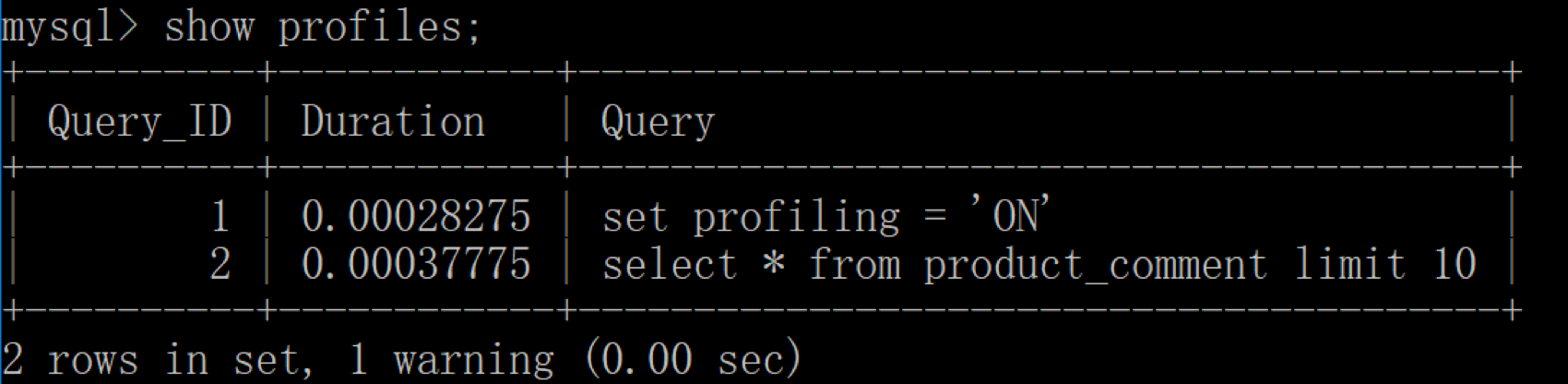
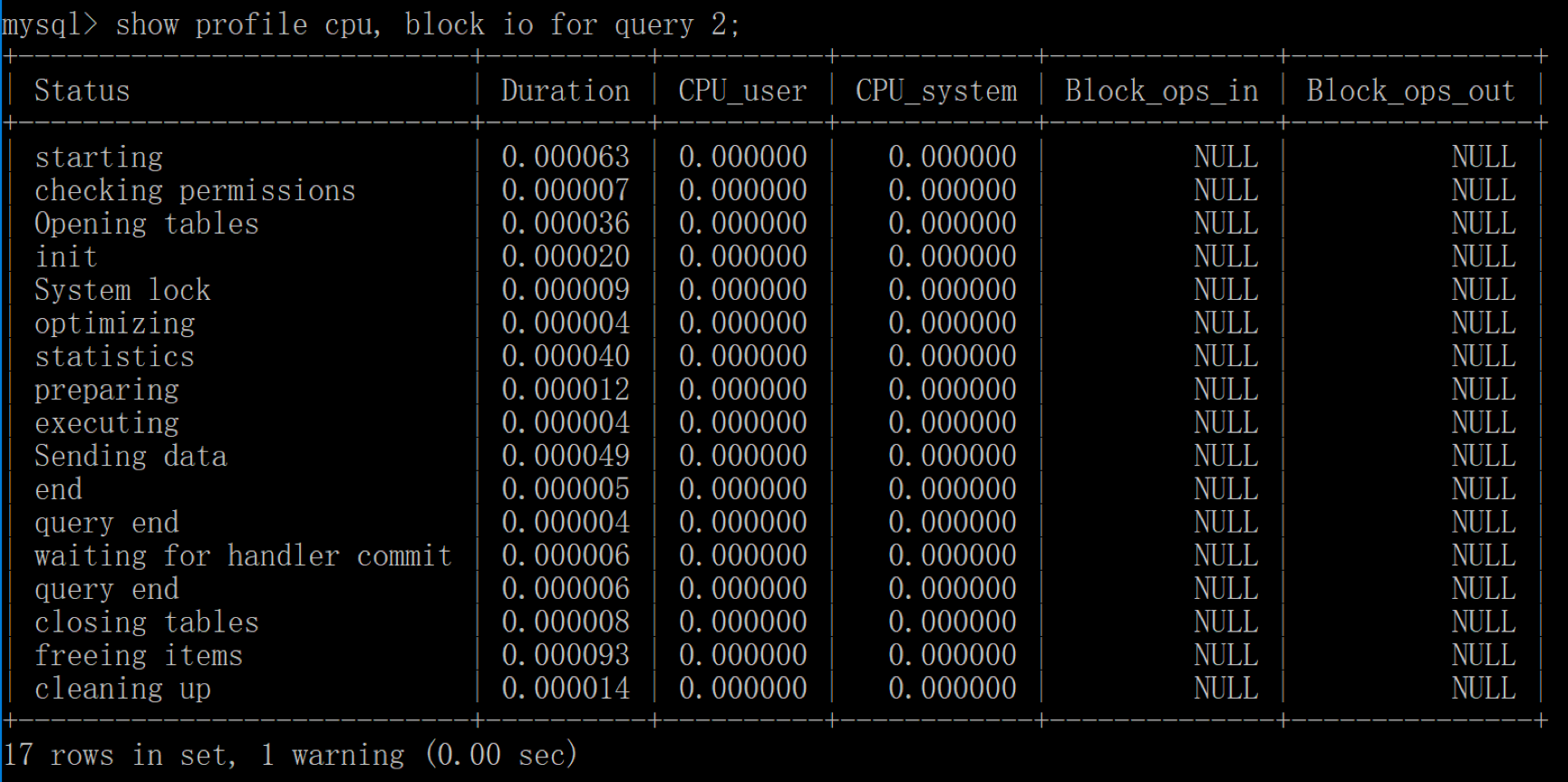
-- 使用 SHOW PROFILE 查看 SQL 的具体执行成本 -- 查看 profiling 功能是否开启 show variables like 'profiling'; -- 通过设置 profiling='ON’来开启 show profile set profiling = 'ON'; -- 查看当前会话都有哪些 profiles show profiles; -- 查看上一个查询的开销 show PROFILE; -- 查看指定的 Query ID 的开销,比如 show profile for query 2 查询结果是一样的 show profile cpu, block io for query 2


不过 SHOW PROFILE 命令将被弃用,我们可以从 information_schema 中的 profiling 数据表进行查看。
99 直接读这些牛人的原文
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号