《Java架构师的第一性原理》41存储之MySQL第9篇MySQL主从复制
1 主从复制介绍
主从复制的概念很简单,就是从原来的数据库复制一个完全一样的数据库,原来的数据库称作主数据库,复制的数据库称为从数据库。从数据库会与主数据库进行数据同步,保持二者的数据一致性。
主从复制的原理实际上就是通过bin log日志实现的。bin log日志中保存了数据库中所有SQL语句,通过对bin log日志中SQL的复制,然后再进行语句的执行即可实现从数据库与主数据库的同步。
主从复制的过程可见下图。主从复制的过程主要是靠三个线程进行的,一个运行在主服务器中的发送线程,用于发送binlog日志到从服务器。两外两个运行在从服务器上的I/O线程和SQL线程。I/O线程用于读取主服务器发送过来的binlog日志内容,并拷贝到本地的中继日志中。SQL线程用于读取中继日志中关于数据更新的SQL语句并执行,从而实现主从库的数据一致。
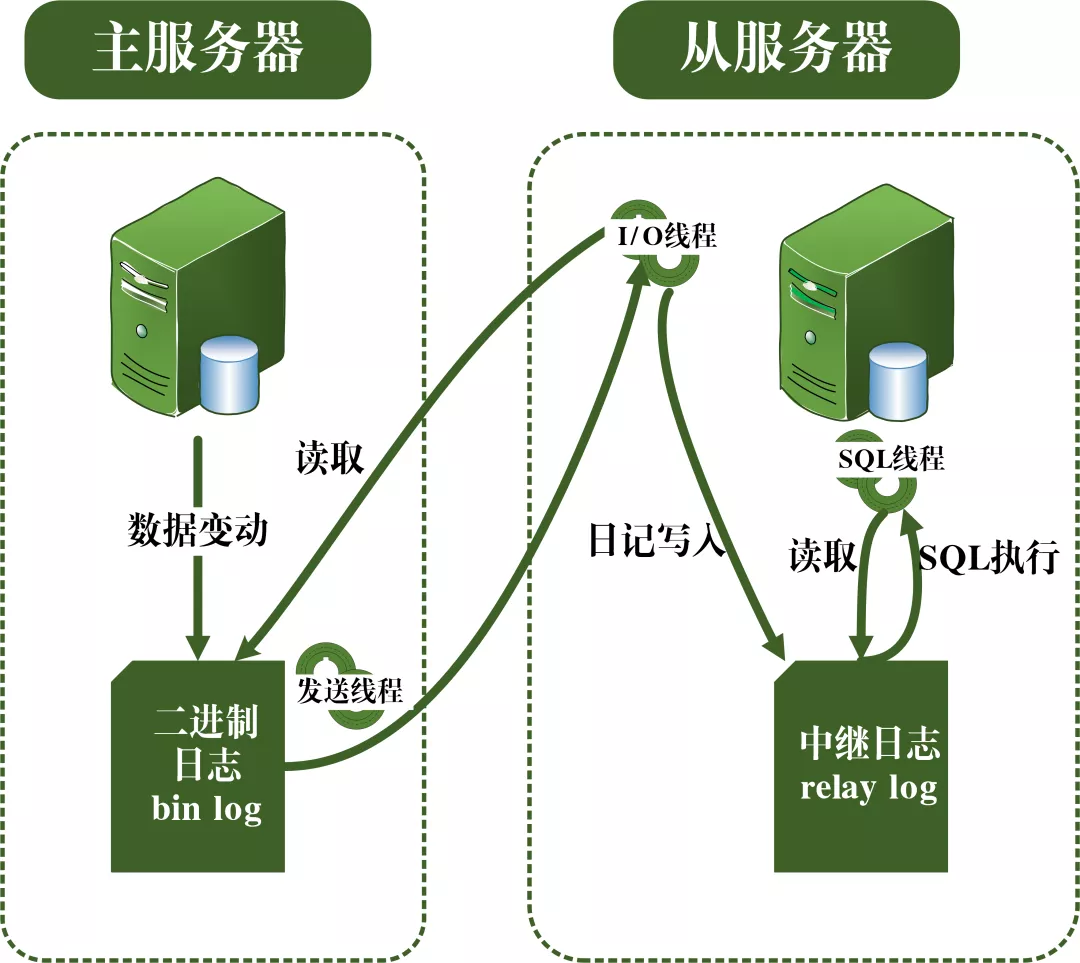
主从复制原理
之所以需要实现主从复制,实际上是由实际应用场景所决定的。主从复制能够带来的好处有:
- 1. 通过复制实现数据的异地备份,当主数据库故障时,可切换从数据库,避免数据丢失。
- 2. 可实现架构的扩展,当业务量越来越大,I/O访问频率过高时,采用多库的存储,可以降低磁盘I/O访问的频率,提高单个机器的I/O性能。
- 3. 可实现读写分离,使数据库能支持更大的并发。
- 4. 实现服务器的负载均衡,通过在主服务器和从服务器之间切分处理客户查询的负荷。
2 主从复制实现原理
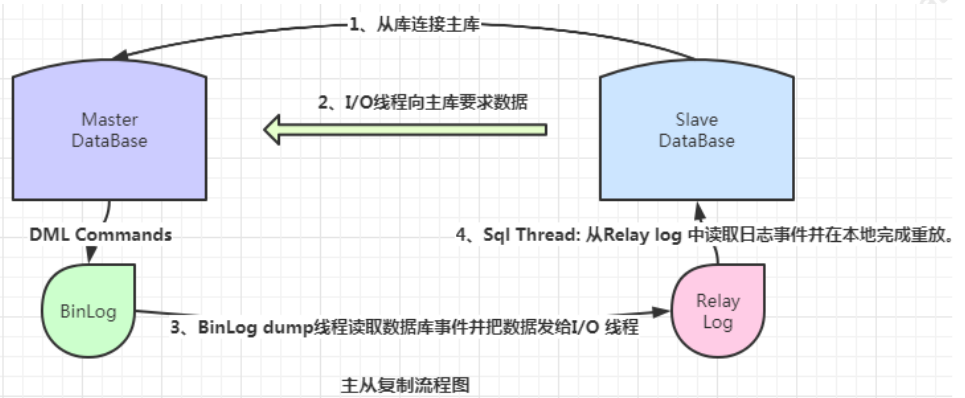
主从同步流程:
1、主节点必须启用二进制日志,记录任何修改了数据库数据的事件。
2、从节点开启一个线程(I/O Thread)把自己扮演成 mysql 的客户端,通过 mysql 协议,请求主节点的二进制日志文件中的事件 。
3、主节点启动一个线程(dump Thread),检查自己二进制日志中的事件,跟对方请求的位置对比,如果不带请求位置参数,则主节点就会从第一个日志文件中的第一个事件一个一个发送给从节点。
4、从节点接收到主节点发送过来的数据把它放置到中继日志(Relay log)文件中。并记录该次请求到主节点的具体哪一个二进制日志文件内部的哪一个位置(主节点中的二进制文件会有多个)。
5、从节点启动另外一个线程(sql Thread ),把 Relay log 中的事件读取出来,并在本地再执行一次。
mysql默认的复制方式是异步的,并且复制的时候是有并行复制能力的。主库把日志发送给从库后不管了,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
- 全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
- 半同步复制
半同步复制的逻辑是这样,从库写入日志成功后返回
ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
还可以延伸到由于主从配置不一样、主库大事务、从库压力过大、网络震荡等造成主备延迟,如何避免这个问题?主备切换的时候用可靠性优先原则还是可用性优先原则?如何判断主库Crash了?互为主备情况下如何避免主备循环复制?被删库跑路了如何正确恢复?(⊙o⊙)… 感觉越来越扯到DBA的活儿上去了。
3 MySQL主从延时这么长,要怎么优化
MySQL主从复制,读写分离是互联网常见的数据库架构,该架构最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重。
1)为什么主从延时这么大?
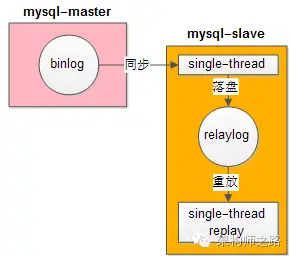
答:MySQL使用单线程重放RelayLog。
2)应该怎么优化,缩短重放时间?
答:多线程并行重放RelayLog可以缩短时间。
3)多线程并行重放RelayLog有什么问题?
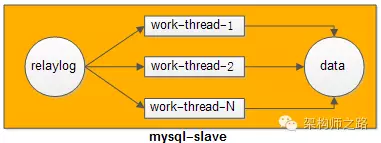
答:需要考虑如何分割RelayLog,才能够让多个数据库实例,多个线程并行重放RelayLog,不会出现不一致。
4)为什么会出现不一致?
答:如果RelayLog随机的分配给不同的重放线程,假设RelayLog中有这样三条串行的修改记录:
update account set money=100 where uid=58; update account set money=150 where uid=58; update account set money=200 where uid=58;
如果单线程串行重放:能保证所有从库与主库的执行序列一致。
画外音:最后money都将为200。
如果多线程随机分配重放:多重放线程并发执行这3个语句,谁最后执行是不确定的,最终从库数据可能与主库不同。
画外音:多个从库可能money为100,150,200不确定。
5)如何分配,多个从库多线程重放,也能得到一致的数据呢?
答:相同库上的写操作,用相同的线程来重放RelayLog;不同库上的写操作,可以并发用多个线程并发来重放RelayLog。
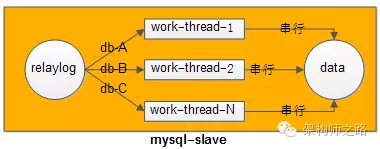
如何做到呢?
答:设计一个哈希算法,hash(db-name) % thread-num,库名hash之后再模上线程数,就能很轻易做到,同一个库上的写操作,被同一个重放线程串行执行。
画外音:不同库上的重放,是并行的,就起到了加速做用。
6)这个方案有什么不足?
答:很多公司对MySQL的使用是“单库多表”,如果是这样的话,仍然只有一个库,还是不能提高RelayLog的重放速度。
启示:将“单库多表”的DB架构模式升级为“多库多表”的DB架构模式。
画外音:数据量大并发量大的互联网业务场景,“多库”模式还具备着其他很多优势,例如:
(1)非常方便的实例扩展:DBA很容易将不同的库扩展到不同的实例上;
(2)按照业务进行库隔离:业务解耦,进行业务隔离,减少耦合与相互影响;
(3)非常方便微服务拆分:每个服务拥有自己的实例就方便了;
7)“单库多表”的场景,多线程并行重放RelayLog还能怎么优化?
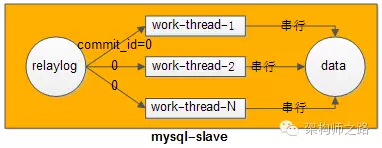
答:即使只有一个库,事务在主库上也是并发执行的,既然在主库上可以并行执行,在从库上也应该能够并行执行呀?
新思路:将主库上同时并行执行的事务,分为一组,编一个号,这些事务在从库上的回放可以并行执行(事务在主库上的执行都进入到prepare阶段,说明事务之间没有冲突,否则就不可能提交),没错,MySQL正是这么做的。
解法:基于GTID的并行复制。
从MySQL5.7开始,将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的信息:
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=1
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=2
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=3
20181014 23:52 server_id 58 XXX GTID last_committed=0 sequence_numer=4
和原来的日志相比,多了last_committed和sequence_number。
什么是last_committed?
答:它是事务提交时,上次事务提交的编号,如果具备相同的last_committed,说明它们在一个组内,可以并发回放执行。
总结
MySQL并行复制,缩短主从同步时延的方法,体现着这样的一些架构思想:
-
多线程是一种常见的缩短执行时间的方法;
画外音:例如,很多crontab可以用多线程,切分数据,并行执行。
-
多线程并发分派任务时,必须保证幂等性:MySQL提供了“按照库幂等”,“按照commit_id幂等”两种方式,很值得借鉴;
画外音:例如,群消息,可以按照group_id幂等;用户消息,可以按照user_id幂等。
具体到MySQL主从同步延时:
-
mysql5.5:不支持并行复制,大伙快升级MySQL版本;
-
mysql5.6:按照库并行复制,建议使用“多库”架构;
-
mysql5.7:按照GTID并行复制;
思路比结论重要,希望大家有收获。
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号