《Java架构师的第一性原理》41存储之MySQL第8篇索引
1 索引的数据结构B+树
《Java架构师的第一性原理》54算法之数据库索引数据结构B+树的前世今生
2 MyISAM与InnoDB的索引差异
2.1 MyISAM的索引
MyISAM的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index)。
其主键索引与普通索引没有本质差异:
-
有连续聚集的区域单独存储行记录
-
主键索引的叶子节点,存储主键,与对应行记录的指针
-
普通索引的叶子结点,存储索引列,与对应行记录的指针
画外音:MyISAM的表可以没有主键。
主键索引与普通索引是两棵独立的索引B+树,通过索引列查找时,先定位到B+树的叶子节点,再通过指针定位到行记录。
举个例子,MyISAM:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
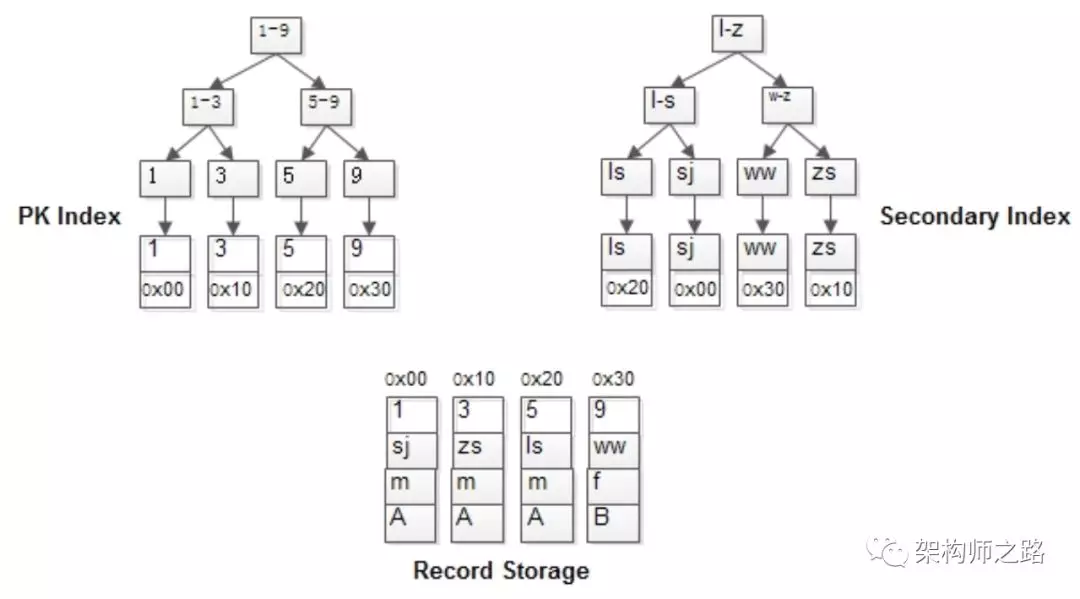
其B+树索引构造如上图:
-
行记录单独存储
-
id为PK,有一棵id的索引树,叶子指向行记录
-
name为KEY,有一棵name的索引树,叶子也指向行记录
2.2 InnoDB的索引
InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):
-
没有单独区域存储行记录
-
主键索引的叶子节点,存储主键,与对应行记录(而不是指针)
画外音:因此,InnoDB的PK查询是非常快的。
因为这个特性,InnoDB的表必须要有聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个非空unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
聚集索引,也只能够有一个,因为数据行在物理磁盘上只能有一份聚集存储。
InnoDB的普通索引可以有多个,它与聚集索引是不同的:
-
普通索引的叶子节点,存储主键(也不是指针)
对于InnoDB表,这里的启示是:
(1)不建议使用较长的列做主键,例如char(64),因为所有的普通索引都会存储主键,会导致普通索引过于庞大;
(2)建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动;
仍是上面的例子,只是存储引擎换成InnoDB:
t(id PK, name KEY, sex, flag);
表中还是四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B

其B+树索引构造如上图:
-
id为PK,行记录和id索引树存储在一起
-
name为KEY,有一棵name的索引树,叶子存储id
当:
select * from t where name=‘lisi’;

会先通过name辅助索引定位到B+树的叶子节点得到id=5,再通过聚集索引定位到行记录。
画外音:所以,其实扫了2遍索引树。
2.3 总结
MyISAM和InnoDB都使用B+树来实现索引:
-
MyISAM的索引与数据分开存储
-
MyISAM的索引叶子存储指针,主键索引与普通索引无太大区别
-
InnoDB的聚集索引和数据行统一存储
-
InnoDB的聚集索引存储数据行本身,普通索引存储主键
-
InnoDB一定有且只有一个聚集索引
-
InnoDB建议使用趋势递增整数作为PK,而不宜使用较长的列作为PK
3 InnoDB B+树索引
- InnoDB逻辑存储结构
- B+树索引结构
- 为什么用B+树?
- 聚集索引与非聚集索引
- 什么是Cardinality?
- 索引的使用
3.1 InnoDB逻辑存储结构
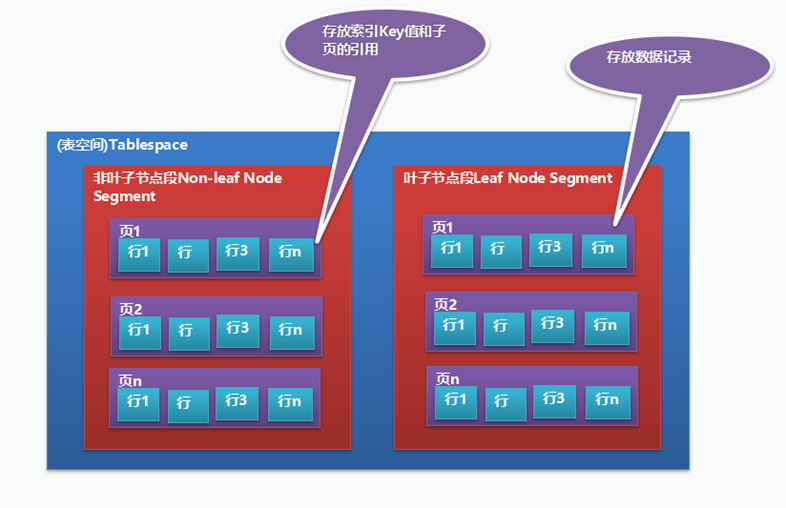
从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑得存放在一个空间中,称为表空间(Tablespace)。
表空间又由段(Segment),区(Extent),页(Page)组成。



1)表空间(Tablespace)
定存放表相关的所有数据,如数据,索引,Bitmap页,回滚信息,插入缓冲索引页,系统事务信息,二次写缓冲等。
2)段(Segment)
即表空间中各个组成部分,常见的有数据段,索引段,回滚段。
3)区(Extent)
区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB。InnoDB存储引擎通常一次申请4~5个区,以此来保证数据的顺序性能。
4) 页(Page)
区的组成部分。每个页默认为16KB,大小可以设置,但设置完成后不能再更改。
常见的页类型有:
- 数据页(B-tree Node)
- Undo页(Undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(Compressed BLOB Page)
数据页内的结构是怎样的
页(Page)如果按类型划分的话,常见的有数据页(保存 B+ 树节点)、系统页、Undo 页和事务数据页等。数据页是我们最常使用的页。
表页的大小限定了表行的最大长度,不同 DBMS 的表页大小不同。比如在 MySQL 的 InnoDB 存储引擎中,默认页的大小是 16KB,我们可以通过下面的命令来进行查看:
show variables like '%innodb_page_size%';
在 SQL Server 的页大小为 8KB,而在 Oracle 中我们用术语“块”(Block)来代表“页”,Oralce 支持的块大小为 2KB,4KB,8KB,16KB,32KB 和 64KB。
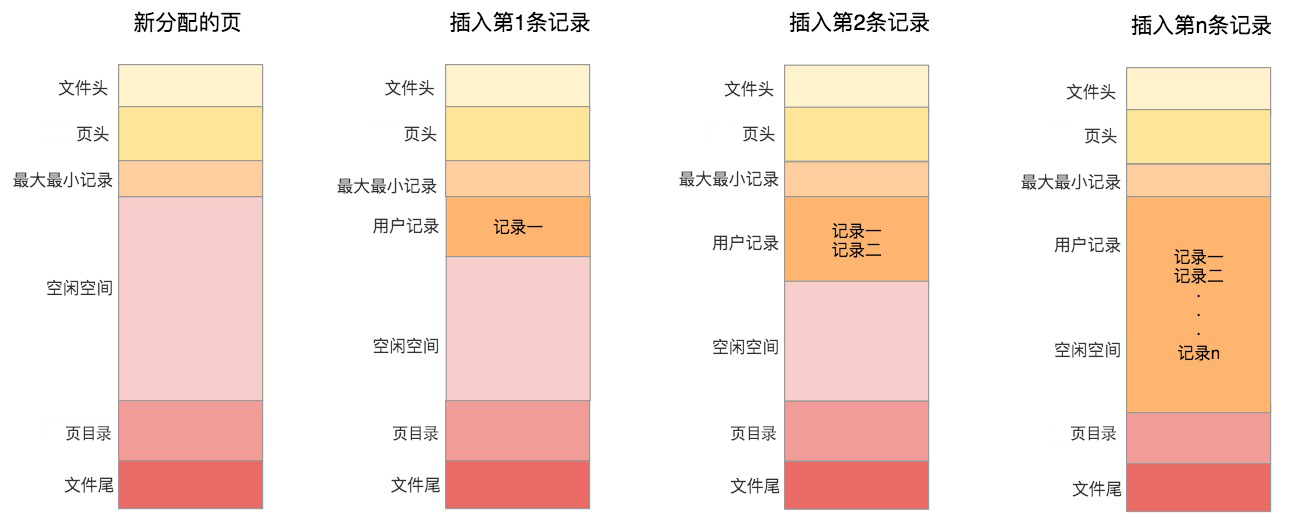
数据库 I/O 操作的最小单位是页,与数据库相关的内容都会存储在页结构里。数据页包括七个部分,分别是文件头(File Header)、页头(Page Header)、最大最小记录(Infimum+supremum)、用户记录(User Records)、空闲空间(Free Space)、页目录(Page Directory)和文件尾(File Tailer)。
页结构的示意图如下所示:
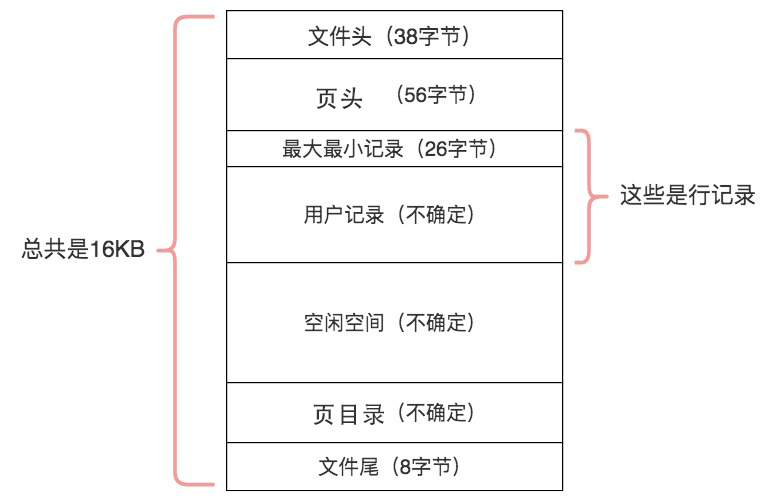
这 7 个部分到底有什么作用呢?我简单梳理下:
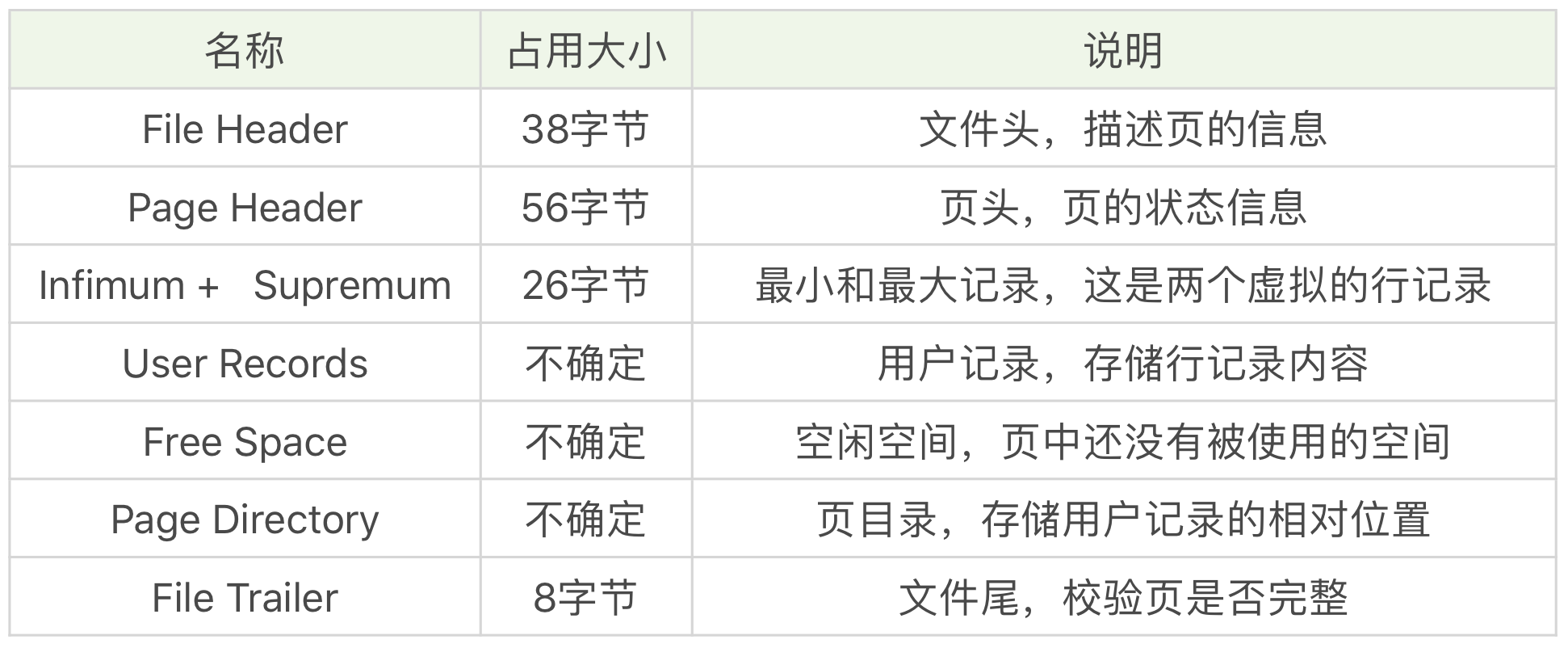
实际上,我们可以把这 7 个数据页分成 3 个部分。
首先是文件通用部分,也就是文件头和文件尾。它们类似集装箱,将页的内容进行封装,通过文件头和文件尾校验的方式来确保页的传输是完整的。
在文件头中有两个字段,分别是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT,它们的作用相当于指针,分别指向上一个数据页和下一个数据页。连接起来的页相当于一个双向的链表,如下图所示:
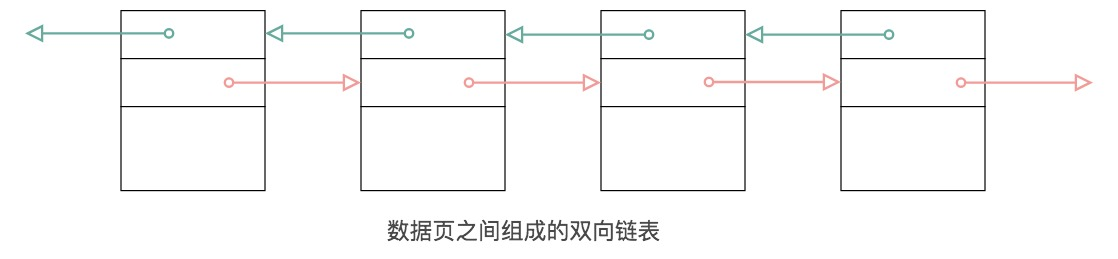
需要说明的是采用链表的结构让数据页之间不需要是物理上的连续,而是逻辑上的连续。
我们之前讲到过 Hash 算法,这里文件尾的校验方式就是采用 Hash 算法进行校验。举个例子,当我们进行页传输的时候,如果突然断电了,造成了该页传输的不完整,这时通过文件尾的校验和(checksum 值)与文件头的校验和做比对,如果两个值不相等则证明页的传输有问题,需要重新进行传输,否则认为页的传输已经完成。
第二个部分是记录部分,页的主要作用是存储记录,所以“最小和最大记录”和“用户记录”部分占了页结构的主要空间。另外空闲空间是个灵活的部分,当有新的记录插入时,会从空闲空间中进行分配用于存储新记录,如下图所示:
第三部分是索引部分,这部分重点指的是页目录,它起到了记录的索引作用,因为在页中,记录是以单向链表的形式进行存储的。单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索,因此在页目录中提供了二分查找的方式,用来提高记录的检索效率。这个过程就好比是给记录创建了一个目录:
- 将所有的记录分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录。
- 第 1 组,也就是最小记录所在的分组只有 1 个记录;最后一组,就是最大记录所在的分组,会有 1-8 条记录;其余的组记录数量在 4-8 条之间。这样做的好处是,除了第 1 组(最小记录所在组)以外,其余组的记录数会尽量平分。
- 在每个组中最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段。
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。如下图所示:
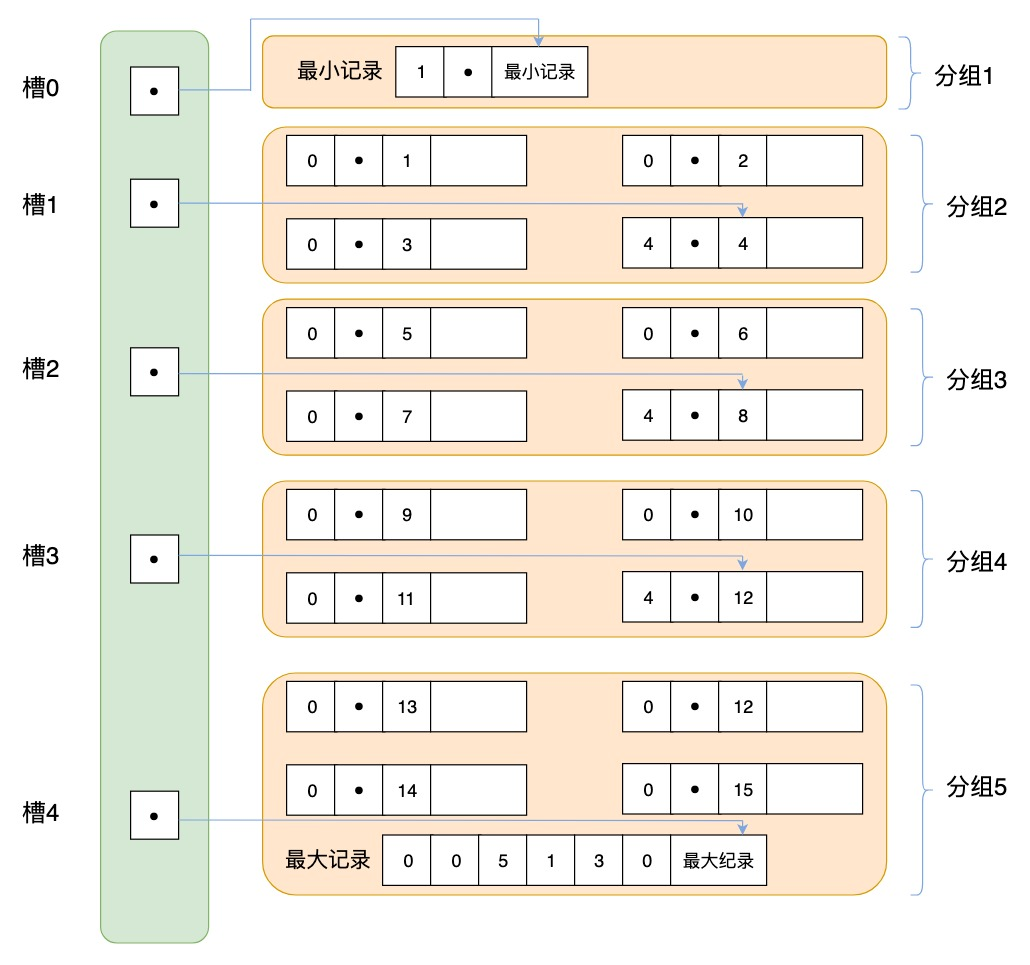
页目录存储的是槽,槽相当于分组记录的索引。我们通过槽查找记录,实际上就是在做二分查找。这里我以上面的图示进行举例,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 9 的用户记录,我们初始化查找的槽的下限编号,设置为 low=0,然后设置查找的槽的上限编号 high=4,然后采用二分查找法进行查找。
首先找到槽的中间位置 p=(low+high)/2=(0+4)/2=2,这时我们取编号为 2 的槽对应的分组记录中最大的记录,取出关键字为 8。因为 9 大于 8,所以应该会在槽编号为 (p,high] 的范围进行查找
接着重新计算中间位置 p’=(p+high)/2=(2+4)/2=3,我们查找编号为 3 的槽对应的分组记录中最大的记录,取出关键字为 12。因为 9 小于 12,所以应该在槽 3 中进行查找。
遍历槽 3 中的所有记录,找到关键字为 9 的记录,取出该条记录的信息即为我们想要查找的内容。
从数据页的角度看 B+ 树是如何进行查询的
MySQL 的 InnoDB 存储引擎采用 B+ 树作为索引,而索引又可以分成聚集索引和非聚集索引(二级索引),这些索引都相当于一棵 B+ 树,如图所示。一棵 B+ 树按照节点类型可以分成两部分:
- 叶子节点,B+ 树最底层的节点,节点的高度为 0,存储行记录。
- 非叶子节点,节点的高度大于 0,存储索引键和页面指针,并不存储行记录本身。
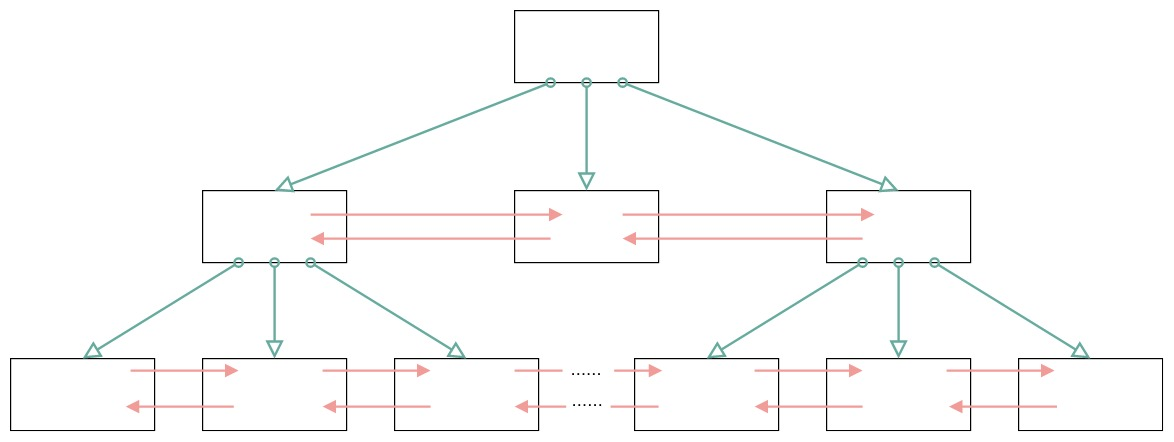
我们刚才学习了页结构的内容,你可以用页结构对比,看下 B+ 树的结构。
在一棵 B+ 树中,每个节点都是一个页,每次新建节点的时候,就会申请一个页空间。同一层上的节点之间,通过页的结构构成一个双向的链表(页文件头中的两个指针字段)。非叶子节点,包括了多个索引行,每个索引行里存储索引键和指向下一层页面的页面指针。最后是叶子节点,它存储了关键字和行记录,在节点内部(也就是页结构的内部)记录之间是一个单向的链表,但是对记录进行查找,则可以通过页目录采用二分查找的方式来进行。
当我们从页结构来理解 B+ 树的结构的时候,可以帮我们理解一些通过索引进行检索的原理:
- B+ 树是如何进行记录检索的?
如果通过 B+ 树的索引查询行记录,首先是从 B+ 树的根开始,逐层检索,直到找到叶子节点,也就是找到对应的数据页为止,将数据页加载到内存中,页目录中的槽(slot)采用二分查找的方式先找到一个粗略的记录分组,然后再在分组中通过链表遍历的方式查找记录。
- 普通索引和唯一索引在查询效率上有什么不同?
我们创建索引的时候可以是普通索引,也可以是唯一索引,那么这两个索引在查询效率上有什么不同呢?
唯一索引就是在普通索引上增加了约束性,也就是关键字唯一,找到了关键字就停止检索。而普通索引,可能会存在用户记录中的关键字相同的情况,根据页结构的原理,当我们读取一条记录的时候,不是单独将这条记录从磁盘中读出去,而是将这个记录所在的页加载到内存中进行读取。InnoDB 存储引擎的页大小为 16KB,在一个页中可能存储着上千个记录,因此在普通索引的字段上进行查找也就是在内存中多几次“判断下一条记录”的操作,对于 CPU 来说,这些操作所消耗的时间是可以忽略不计的。所以对一个索引字段进行检索,采用普通索引还是唯一索引在检索效率上基本上没有差别。
5)行(Row)
页的组成部分,最终存储数据的地方。如果页是16KB,那一个页最多存放 16*1024/2 -200 行的记录,即7992行记录。
3.2 B+树索引结构
所有记录都在叶子节点中顺序排列,页之间有指针互相连接,首页和尾页也是互相连接。
1)B树


2)平衡B树
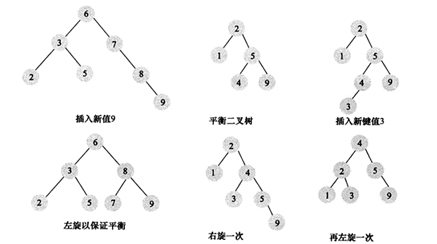
3)B+树

3.3 为什么用B+树
1)树的高度较低,两千万级的表,3次磁盘IO就能定位到数据。
计算:假设数据记录大小为1K,页大小为16K,主键+引用大小为8byte+6byte = 14byte。则叶子节点每个页的记录数为16/1 = 16个。非叶子节点存储的key+指针的数量为16*1024/14 = 1170个。
高度为3的B+树能存储的记录数为:1170*1170*16 = 21902400 条
2)叶子节点存储的数据记录尽量得按顺序存储,范围查询减少了磁盘随机IO。MongoDB的索引采用B树,不适合顺序检索。
3)每次搜索加载一个页的数据,一般下次需要搜索的数据在同一个页中的概率高很多,减少了磁盘IO。
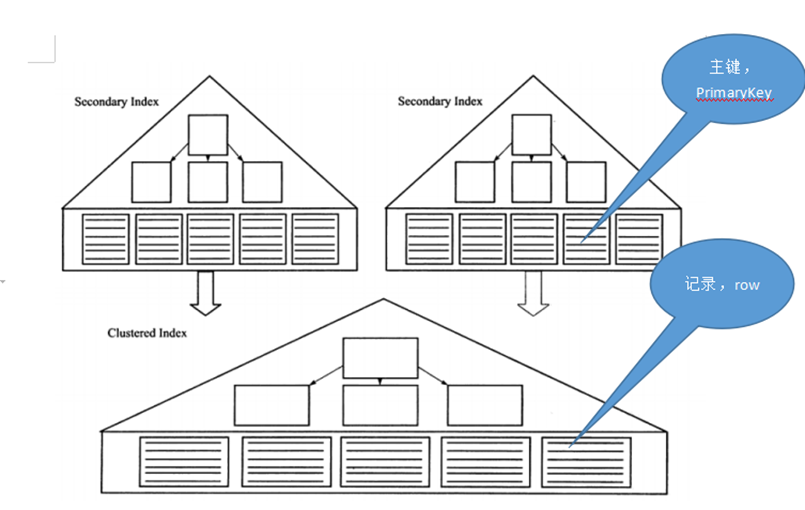
3.4 聚集索引与非聚集索引
按照B+树索引页子节点存放的内容,可以将B+树索引分为聚集索引和非聚集索引。
1)聚集索引
即索引组织表,表记录存放在聚集索引的叶子节点中。因实际的数据页只能按照一颗B+树进行排序,所以一个表只能有一个聚集索引。
问题:聚集索引按照顺序物理得存储数据吗?
问题:表有碎片以后怎么办?
2)非聚集索引
也是B+树,但是叶子节点存储的是聚集索引的键值,也就是主键。通过非聚集索引查询时,先查询出主键,再用主键从聚集索引中查询具体记录。如果聚集索引和非聚集索引的高度都为3,一次查询需要6次磁盘IO。
4 索引漂移:什么是Cardinality
即索引的列中的值有多少种不同的取值, 用来判断索引的可选择性,建立索引是否有必要。MYSQL的执行计划也通过它来判断使用合适的索引。
1)举例
如下表,如果用姓名做索引,Cardinality为4,如果用性别,Cardinality为2
|
ID |
姓名 |
性别 |
|
|
1 |
张三 |
男 |
|
|
2 |
李四 |
男 |
|
|
3 |
王五 |
女 |
|
|
4 |
赵六 |
女 |
2)索引的可选择性
用Cardinality/行数 可以得出索引的选择性。还是以上面的姓名做例子,选择性为4/4 = 1, 性别的选择性为2/4 = 0.5 。1是可选择性的最高值,越接近1,索引的效果越好
3)Cardinality查询
show index from [Table Name]

4)InnoDB何时更新Cardinality?
表中1/16的数据被更改。
Stat_modified_counter 值超过2000000000时。
5)InnoDB如何更新Cardinality?
取得索引B+树中叶子节点的数量,记为A。
随机取得B+树索引中8个叶子节点,统计每个节点的记录数,记为P1,P2,P3...P8
根据采样信息Cardinality = (P1+P2+.....+P8)/8*A
6)Cardinality估算方式可能带来的问题
由于Cardinality是估算的值,所以不一定准确。在超过千万级的大表中,经常可能出现MYSQL用错索引的情况。
5 索引的使用
即索引的列中的值有多少种不同的取值, 用来判断索引的可选择性,建立索引是否有必要。MYSQL的执行计划也通过它来判断使用合适的索引。
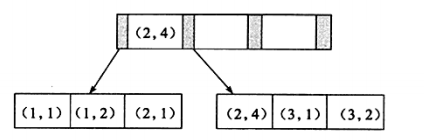
1)联合索引
联合索引:如下图,联合索引(a, b)的情况,是按a排序,a相同的情况下按b排序。所以,查询时只能用a,或(a, b)才会使用到索引。
2)覆盖索引
覆盖索引(covering index):即从非聚集索引中就可以查询到所需要的记录。不需要再查询聚集索引,减少了多次磁盘IO。
比如:cps_ln表有联合索引IDX_CUST_ID(cust_id, business_dt), 主键 id, 以下查询只会走非聚集索引。

3)MySQL不使用索引的情况
即索引的列中的值有多少种不同的取值, 用来判断索引的可选择性,建立索引是否有必要。MYSQL的执行计划也通过它来判断使用合适的索引。
使用非聚集索引进行范围查询,会造成较高的随机IO,所以MySQL的策略是用主键进行全表扫描,相对顺序的IO,效率更高。

4)MySQL使用错误索引的情况
MYSQL使用错误索引的情况:千万级以上的大表,索引的可选择性(cardinality/ row count)容易发生错误,这是需要执行Opertimize table优化,或者考虑拆表。临时解决方案是使用索引提示,force index 关键字指定索引。
Force index前:

Force index后:

6 MySQL的执行计划
1、什么是执行计划
执行计划就是sql的执行查询的顺序,以及如何使用索引查询,返回的结果集的行数
2、执行计划的内容
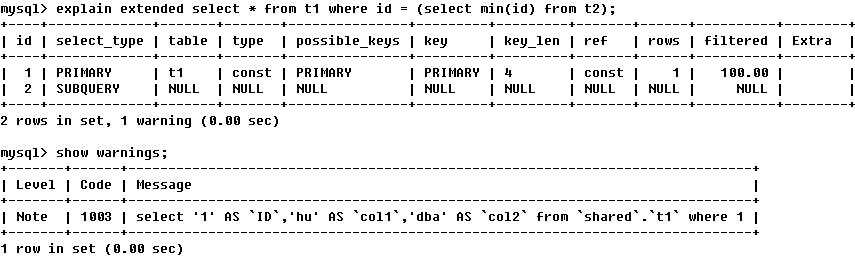
explain的语法
EXPLAIN SELECT …… 变体: 1. EXPLAIN EXTENDED SELECT …… 将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可得到被MySQL优化器优化后的查询语句 2. EXPLAIN PARTITIONS SELECT …… 用于分区表的EXPLAIN
![]()
1)id sql执行计划的顺序或子查询表的执行顺序
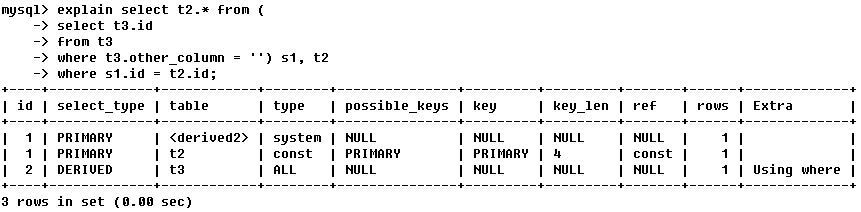
- id一样,按照顺序执行
- id越大,执行的优先级就越高(如子查询)
- id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
2)select_type 表示查询中每个select子句的类型

- SIMPLE:查询中不包含子查询或者UNION
- 查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
- 在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
- 在FROM列表中包含的子查询被标记为:DERIVED(衍生)
- 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在 FROM子句的子查询中,外层SELECT将被标记为:DERIVED
- 从UNION表获取结果的SELECT被标记为:UNION RESULT
3)type MySQL在表中找到所需行的方式,又称“访问类型”,常见类型如下:
![]()
由左至右,由最差到最好。
(1)ALL:全表扫描。Full Table Scan, MySQL将遍历全表以找到匹配的行。

(2)index:index类型只遍历索引树。Full Index Scan,index与ALL区别为index类型只遍历索引树。

索引的存在形式是文件,按存储结构划分):FULLTEXT,HASH,BTREE,RTREE。
对应存储引擎支持如下:

(3)range:索引范围扫描
对索引字段进行范围查询,使用in则是使用rang范围查询; 使用">" ,"<" 或者 "between" 都是可以使用索引的,但是要控制查询的时间范围,一般查询数据不要超过数据总数的 15%
(4)ref:非唯一性索引扫描,返回匹配某个单独值的所有行。常见于使用非唯一索引即唯一索引的非唯一前缀进行的查找。
类似 select count(1) from age = '20';
(5)eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
(6)const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量
(7)NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引
4)possible_keys
5)key 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
TIPS:查询中若使用了覆盖索引,则该索引仅出现在key列表中
覆盖索引:查询数据只需要通过索引就可以查询出,如55万条数据,使用索引,立刻可以查询出 2000条数据,同时Extra字段是Using index 。
6)key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
7)ref 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值

9)Extra 包含不适合在其他列中显示但十分重要的额外信息
- Using index : 使用覆盖索引的时候就会出现
- using index condition:查找使用了索引,但是需要回表查询数据
- Using where :在查找使用索引的情况下,需要回表去查询所需的数据
- using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
- Using temporary:需要使用临时表来存储结果集,常见于排序和分组查询
- Using filesort:无法利用索引完成的排序操作称为“文件排序”;
很多场景都是索引是一个字段,order by 排序的字段与索引字段不一致,导致的Using fileSort;
此时可以给排序字段和where条件字段,添加为组合索引,同时保证索引查询的数据不超过总量的15%,避免fileSort
注:回表的含义是,先根据索引查询数据,然后在根据确定的数据id和查询条件再去查询具体的数据的过程
MySQL执行计划的局限
- EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
- EXPLAIN不考虑各种Cache
- EXPLAIN不能显示MySQL在执行查询时所作的优化工作
- 部分统计信息是估算的,并非精确值
- EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划
7 MySQL索引常问面试题
7.1 索引优化
覆盖索引
指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
查询在什么时候不走(预期中的)索引
- 模糊查询 %like
- 索引列参与计算,使用了函数
- 非最左前缀顺序
- where对null判断
- where不等于
- or操作有至少一个字段没有索引
- 需要回表的查询结果集过大(超过配置的范围)
explain命令概要
- id:select选择标识符
- select_type:表示查询的类型。
- table:输出结果集的表
- partitions:匹配的分区
- type:表示表的连接类型
- possible_keys:表示查询时,可能使用的索引
- key:表示实际使用的索引
- key_len:索引字段的长度
- ref:列与索引的比较
- rows:扫描出的行数(估算的行数)
- filtered:按表条件过滤的行百分比
- Extra:执行情况的描述和说明
explain 中的 select_type(查询的类型)
- SIMPLE(简单SELECT,不使用UNION或子查询等)
- PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
- UNION(UNION中的第二个或后面的SELECT语句)
- DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
- UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
- SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
- DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
- DERIVED(派生表的SELECT, FROM子句的子查询)
- UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
explain 中的 type(表的连接类型)
- system:最快,主键或唯一索引查找常量值,只有一条记录,很少能出现
- const:PK或者unique上的等值查询
- eq_ref:PK或者unique上的join查询,等值匹配,对于前表的每一行(row),后表只有一行命中
- ref:非唯一索引,等值匹配,可能有多行命中
- range:索引上的范围扫描,例如:between/in
- index:索引上的全集扫描,例如:InnoDB的count
- ALL:最慢,全表扫描(full table scan)
explain 中的 Extra(执行情况的描述和说明)
- Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
- Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
- Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
- Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
- Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
- Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
- No tables used:Query语句中使用from dual 或不含任何from子句
数据库优化指南
- 创建并使用正确的索引
- 只返回需要的字段
- 减少交互次数(批量提交)
- 设置合理的Fetch Size(数据每次返回给客户端的条数)
7.2 mysql联合索引详解
上一篇文章:mysql数据库索引优化
比较简单的是单列索引(b+tree)。遇到多条件查询时,不可避免会使用到多列索引。联合索引又叫复合索引。
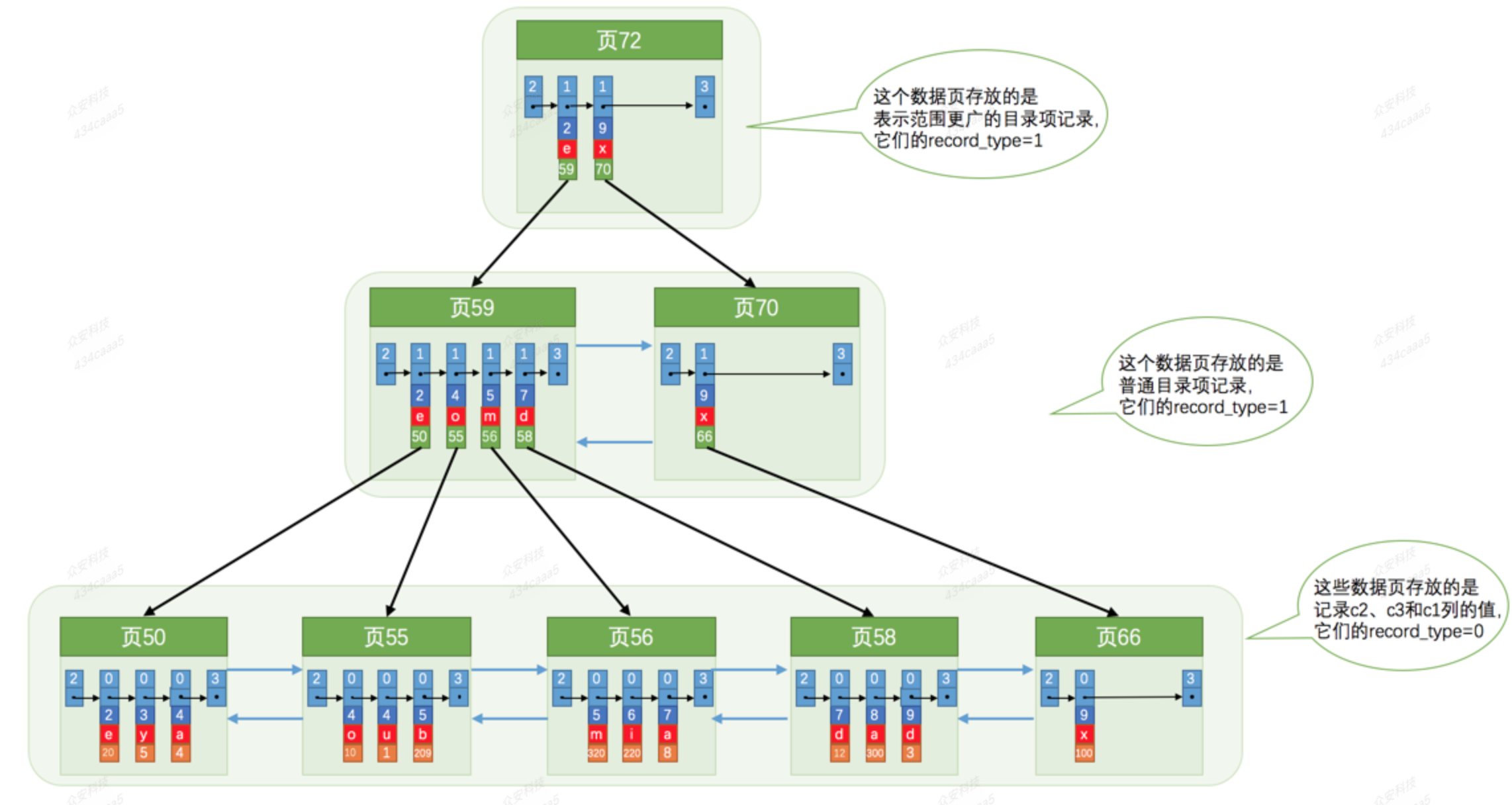
每条目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录的c2列相同,则按照c3列的值进行排序。B+树叶子节点处的用户记录由c2、c3和主键c1列组成。
联合索引只会建立一棵B+树。
b+tree结构如下:
每一个磁盘块在mysql中是一个页,页大小是固定的,mysql innodb的默认的页大小是16k,每个索引会分配在页上的数量是由字段的大小决定。当字段值的长度越长,每一页上的数量就会越少,因此在一定数据量的情况下,索引的深度会越深,影响索引的查找效率。
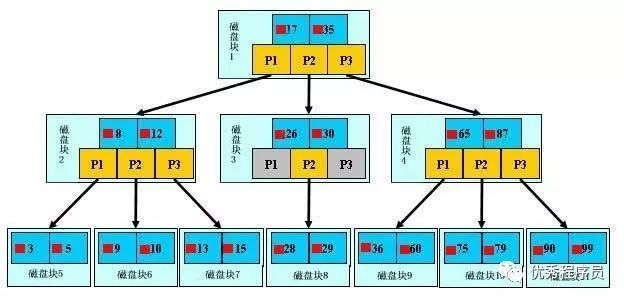
对于复合索引(多列b+tree,使用多列值组合而成的b+tree索引)。遵循最左侧原则,从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a a,b a,b,c 3种组合进行查找,但不支持 b,c进行查找。当使用最左侧字段时,索引就十分有效。
创建表test如下:
create table test( a int, b int, c int, KEY a(a,b,c) );
比如(a,b,c)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(a=? and b=? and c=?)这样的数据来检索的时候,b+树会优先比较a列来确定下一步的所搜方向,如果a列相同再依次比较b列和c列,最后得到检索的数据;但当(b=? and c=?)这样的没有a列的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候a列就是第一个比较因子,必须要先根据a列来搜索才能知道下一步去哪里查询。比如当(a=? and c=?)这样的数据来检索时,b+树可以用a列来指定搜索方向,但下一个字段b列的缺失,所以只能把a列的数据找到,然后再匹配c列的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
以下通过例子分析索引的使用情况,以便于更好的理解联合索引的查询方式和使用范围。
1)多列索引在and查询中应用
select * from test where a=? and b=? and c=?;查询效率最高,索引全覆盖。
select * from test where a=? and b=?;索引覆盖a和b。
select * from test where b=? and a=?;经过mysql的查询分析器的优化,索引覆盖a和b。
select * from test where a=?;索引覆盖a。
select * from test where b=? and c=?;没有a列,不走索引,索引失效。
select * from test where c=?;没有a列,不走索引,索引失效。
2)多列索引在范围查询中应用
select * from test where a=? and b between ? and ? and c=?;索引覆盖a和b,因b列是范围查询,因此c列不能走索引。
select * from test where a between ? and ? and b=?;a列走索引,因a列是范围查询,因此b列是无法使用索引。
select * from test where a between ? and ? and b between ? and ? and c=?;a列走索引,因a列是范围查询,b列是范围查询也不能使用索引。
3)多列索引在排序中应用
select * from test where a=? and b=? order by c;a、b、c三列全覆盖索引,查询效率最高。
select * from test where a=? and b between ? and ? order by c;a、b列使用索引查找,因b列是范围查询,因此c列不能使用索引,会出现file sort。
4)总结
联合索引的使用在写where条件的顺序无关,mysql查询分析会进行优化而使用索引。但是减轻查询分析器的压力,最好和索引的从左到右的顺序一致。
使用等值查询,多列同时查询,索引会一直传递并生效。因此等值查询效率最好。
索引查找遵循最左侧原则。但是遇到范围查询列之后的列索引失效。
排序也能使用索引,合理使用索引排序,避免出现file sort。
7.3 求求你别再用offset和limit分页了
今天我们将探讨已经被广泛使用的分页方式存在的问题,以及如何实现高性能分页。
1,OFFSET 和 LIMIT 有什么问题?
正如前面段落所说的那样,OFFSET 和 LIMIT 对于数据量少的项目来说是没有问题的。
但是,当数据库里的数据量超过服务器内存能够存储的能力,并且需要对所有数据进行分页,问题就会出现。
为了实现分页,每次收到分页请求时,数据库都需要进行低效的全表扫描。
什么是全表扫描?全表扫描 (又称顺序扫描) 就是在数据库中进行逐行扫描,顺序读取表中的每一行记录,然后检查各个列是否符合查询条件。这种扫描是已知最慢的,因为需要进行大量的磁盘 I/O,而且从磁盘到内存的传输开销也很大。
这意味着,如果你有 1 亿个用户,OFFSET 是 5 千万,那么它需要获取所有这些记录 (包括那么多根本不需要的数据),将它们放入内存,然后获取 LIMIT 指定的 20 条结果。
也就是说,为了获取一页的数据:
10万行中的第5万行到第5万零20行
需要先获取 5 万行。这么做是多么低效?
如果你不相信,可以看看这个例子:
https://www.db-fiddle.com/f/3JSpBxVgcqL3W2AzfRNCyq/1?ref=hackernoon.com
左边的 Schema SQL 将插入 10 万行数据,右边有一个性能很差的查询和一个较好的解决方案。只需单击顶部的 Run,就可以比较它们的执行时间。第一个查询的运行时间至少是第二个查询的 30 倍。
数据越多,情况就越糟。看看我对 10 万行数据进行的 PoC。
https://github.com/IvoPereira/Efficient-Pagination-SQL-PoC?ref=hackernoon.com
现在你应该知道这背后都发生了什么:OFFSET 越高,查询时间就越长。
2,替代方案
你应该这样做:

这是一种基于指针的分页。
你要在本地保存上一次接收到的主键 (通常是一个 ID) 和 LIMIT,而不是 OFFSET 和 LIMIT,那么每一次的查询可能都与此类似。
为什么?因为通过显式告知数据库最新行,数据库就确切地知道从哪里开始搜索(基于有效的索引),而不需要考虑目标范围之外的记录。
比较这个查询:
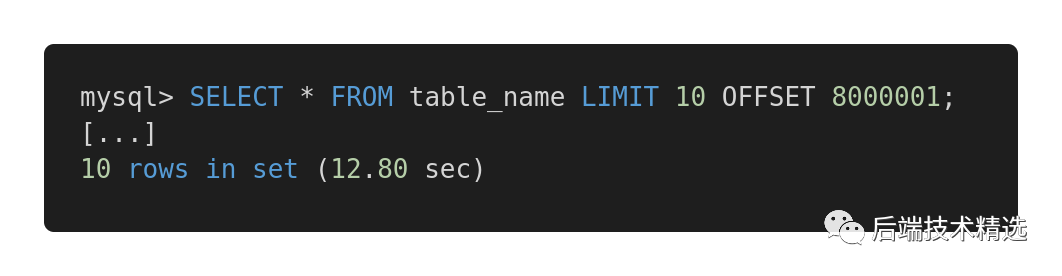
和优化的版本:

返回同样的结果,第一个查询使用了 12.80 秒,而第二个仅用了 0.01 秒。
要使用这种基于游标的分页,需要有一个惟一的序列字段 (或多个),比如惟一的整数 ID 或时间戳,但在某些特定情况下可能无法满足这个条件。
我的建议是,不管怎样都要考虑每种解决方案的优缺点,以及需要执行哪种查询。
如果需要基于大量数据做查询操作,Rick James 的文章提供了更深入的指导。
http://mysql.rjweb.org/doc.php/lists
如果我们的表没有主键,比如是具有多对多关系的表,那么就使用传统的 OFFSET/LIMIT 方式,只是这样做存在潜在的慢查询问题。我建议在需要分页的表中使用自动递增的主键,即使只是为了分页。
英语原文:
https://hackernoon.com/please-dont-use-offset-and-limit-for-your-pagination-8ux3u4y
99 直接读这些牛人的原文
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号