《Java架构师的第一性原理》41存储之MySQL第6篇锁
1 锁机制
1.1 并发控制
为啥要进行并发控制?
并发的任务对同一个临界资源进行操作,如果不采取措施,可能导致不一致,故必须进行并发控制(Concurrency Control)。
技术上,通常如何进行并发控制?
通过并发控制保证数据一致性的常见手段有:
-
锁(Locking)
-
数据多版本(Multi Versioning)
事务之间的隔离,是通过锁机制实现的。当一个事务需要对数据库中的某行数据进行修改时,需要先给数据加锁;加了锁的数据,其它事务是不运行操作的,只能等待当前事务提交或回滚将锁释放。锁机制并不是一个陌生的概念,在许多场景中都会利用到不同实现的锁对数据进行保护和同步。而在MySQL中,根据不同的划分标准,还可将锁分为不同的种类。
- 按照粒度划分:行锁、表锁、页锁
- 按照使用方式划分:共享锁、排它锁
- 按照程序员角度划分:悲观锁、乐观锁
- 按照事务隔离划分:记录锁、间隙锁、临键锁
InnoDB内核的第一种锁:自增锁(Auto-inc Locks)
InnoDB内核的三种锁:共享/排他锁(Shared and Exclusive Locks)、意向锁(Intention Locks)、插入意向锁(Insert Intention Locks)
InnoDB三种细粒度行锁:记录锁(Record Locks)、间隙锁(Gap Locks)、临键锁(Next-Key Locks)
1.2 按照粒度划分(行锁、表锁、页锁)
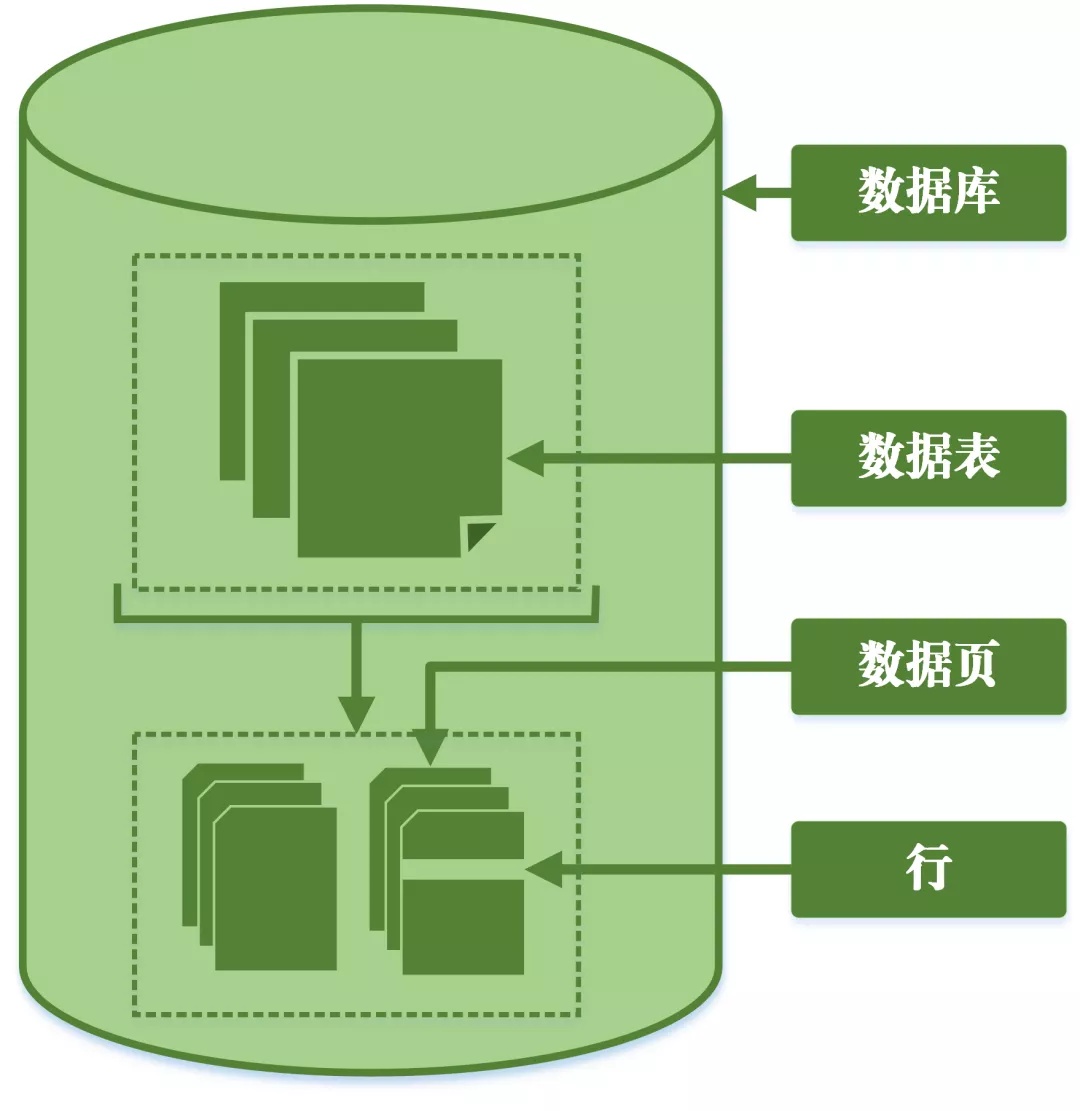
粒度:指数据仓库的数据单位中保存数据的细化或综合程度的级别。细化程度越高,粒度级就越小;相反,细化程度越低,粒度级就越大。
MySQL按照锁的粒度划分可以分为行锁、表锁和页锁。
- 行锁:粒度最小的锁,表示只针对当前操作的行进行加锁;
- 表锁:粒度最大的锁,表示当前的操作对整张表加锁;
- 页锁:粒度介于行级锁和表级锁中间的一种锁,表示对页进行加锁。
数据库的粒度划分
这三种锁是在不同层次上对数据进行锁定,由于粒度的不同,其带来的好处和劣势也不一而同。
表锁在操作数据时会锁定整张表,因而并发性能较差;行锁则只锁定需要操作的数据,并发性能好。但是由于加锁本身需要消耗资源(获得锁、检查锁、释放锁等都需要消耗资源),因此在锁定数据较多情况下使用表锁可以节省大量资源。
MySQL中不同的存储引擎能够支持的锁也是不一样的。MyIsam只支持表锁,而InnoDB同时支持表锁和行锁,且出于性能考虑,绝大多数情况下使用的都是行锁。
1.3 按照使用方式划分(共享锁、排他锁)
如何使用普通锁保证一致性?
普通锁,被使用最多:
- 操作数据前,锁住,实施互斥,不允许其他的并发任务操作;
- 操作完成后,释放锁,让其他任务执行;
如此这般,来保证一致性。
普通锁存在什么问题?
简单的锁住太过粗暴,连“读任务”也无法并行,任务执行过程本质上是串行的。
于是出现了共享锁与排他锁:
-
共享锁(Share Locks,记为S锁),读取数据时加S锁
-
排他锁(eXclusive Locks,记为X锁),修改数据时加X锁
共享锁与排他锁的玩法是:
-
共享锁之间不互斥,简记为:读读可以并行
-
排他锁与任何锁互斥,简记为:写读,写写不可以并行
可以看到,一旦写数据的任务没有完成,数据是不能被其他任务读取的,这对并发度有较大的影响。
画外音:对应到数据库,可以理解为,写事务没有提交,读相关数据的select也会被阻塞。
有没有可能,进一步提高并发呢?
即使写任务没有完成,其他读任务也可能并发,这就引出了数据多版本。
-- 表上共享锁 LOCK TABLE product_comment READ; UPDATE product_comment SET product_id = 10002 WHERE user_id = 912178; -- ERROR 1099 (HY000): Table 'product_comment' was locked with a READ lock and can't be updated UNLOCK TABLE; -- 行上共享锁 SELECT comment_id, product_id, comment_text, user_id FROM product_comment WHERE user_id = 912178 LOCK IN SHARE MODE; -- 表上排他锁 LOCK TABLE product_comment WRITE; UNLOCK TABLE; -- 行上排他锁 SELECT comment_id, product_id, comment_text, user_id FROM product_comment WHERE user_id = 912178 FOR UPDATE;
1.4 按照事务隔离划分(记录锁、间隙锁、临建锁)
1)记录锁(Record Locks)
记录锁,它封锁索引记录,例如:
select * from t where id=1 for update;
2)间隙锁(Gap Locks)
间隙锁,它封锁索引记录中的间隔,或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。
间隙锁的主要目的,就是为了防止其他事务在间隔中插入数据,以导致“不可重复读”。
如果把事务的隔离级别降级为读提交(Read Committed, RC),间隙锁则会自动失效。
3)临键锁(Next-Key Locks)
临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。
更具体的,临键锁会封锁索引记录本身,以及索引记录之前的区间。
如果一个会话占有了索引记录R的共享/排他锁,其他会话不能立刻在R之前的区间插入新的索引记录。
If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
临键锁的主要目的,也是为了避免幻读(Phantom Read)。如果把事务的隔离级别降级为RC,临键锁则也会失效。
1.5 按照程序员的角度来进行划分(乐观锁、悲观锁)
如果从程序员的视角来看锁的话,可以将锁分成乐观锁和悲观锁,从名字中也可以看出这两种锁是两种看待数据并发的思维方式。
乐观锁(Optimistic Locking)认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,也就是不采用数据库自身的锁机制,而是通过程序来实现。在程序上,我们可以采用版本号机制或者时间戳机制实现。
乐观锁的版本号机制
在表中设计一个版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行UPDATE ... SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。
这种方式类似我们熟悉的 SVN、CVS 版本管理系统,当我们修改了代码进行提交时,首先会检查当前版本号与服务器上的版本号是否一致,如果一致就可以直接提交,如果不一致就需要更新服务器上的最新代码,然后再进行提交。
乐观锁的时间戳机制
时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。
你能看到乐观锁就是程序员自己控制数据并发操作的权限,基本是通过给数据行增加一个戳(版本号或者时间戳),从而证明当前拿到的数据是否最新。
悲观锁(Pessimistic Locking)也是一种思想,对数据被其他事务的修改持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。
我们都不希望出现死锁的情况,可以采取一些方法避免死锁的发生:
- 如果事务涉及多个表,操作比较复杂,那么可以尽量一次锁定所有的资源,而不是逐步来获取,这样可以减少死锁发生的概率;
- 如果事务需要更新数据表中的大部分数据,数据表又比较大,这时可以采用锁升级的方式,比如将行级锁升级为表级锁,从而减少死锁产生的概率;
- 不同事务并发读写多张数据表,可以约定访问表的顺序,采用相同的顺序降低死锁发生的概率。
2 事务的隔离级别存在的问题
我们知道事务有 4 个隔离级别,以及可能存在的三种异常问题,如下图所示:

在 MySQL 中,默认的隔离级别是可重复读,可以解决脏读和不可重复读的问题,但不能解决幻读问题。如果我们想要解决幻读问题,就需要采用串行化的方式,也就是将隔离级别提升到最高,但这样一来就会大幅降低数据库的事务并发能力。
有没有一种方式,可以不采用锁机制,而是通过乐观锁的方式来解决不可重复读和幻读问题呢?实际上 MVCC 机制的设计,就是用来解决这个问题的,它可以在大多数情况下替代行级锁,降低系统的开销。

3 MVVC
3.1 数据多版本介绍
MVCC就是用来实现上面的第三个隔离级别,可重复读RR。
MVCC:Multi-Version Concurrency Control,即多版本的并发控制协议。
从名字中也能看出来,MVCC 是通过数据行的多个版本管理来实现数据库的并发控制,简单来说它的思想就是保存数据的历史版本。这样我们就可以通过比较版本号决定数据是否显示出来(具体的
规则后面会介绍到),读取数据的时候不需要加锁也可以保证事务的隔离效果。
通过 MVCC 我们可以解决以下几个问题:
- 读写之间阻塞的问题,通过 MVCC 可以让读写互相不阻塞,即读不阻塞写,写不阻塞读,这样就可以提升事务并发处理能力。
- 降低了死锁的概率。这是因为 MVCC 采用了乐观锁的方式,读取数据时并不需要加锁,对于写操作,也只锁定必要的行。
- 解决一致性读的问题。一致性读也被称为快照读,当我们查询数据库在某个时间点的快照时,只能看到这个时间点之前事务提交更新的结果,而不能看到这个时间点之后事务提交的更新结果。
MVCC的特点就是在同一时刻,不同事务可以读取到不同版本的数据,从而可以解决脏读和不可重复读的问题。
MVCC实际上就是通过数据的隐藏列和回滚日志(undo log),实现多个版本数据的共存。这样的好处是,使用MVCC进行读数据的时候,不用加锁,从而避免了同时读写的冲突。
在实现MVCC时,每一行的数据中会额外保存几个隐藏的列,比如当前行创建时的版本号和删除时间和指向undo log的回滚指针。这里的版本号并不是实际的时间值,而是系统版本号。每开始新的事务,系统版本号都会自动递增。事务开始时的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。每个事务又有自己的版本号,这样事务内执行数据操作时,就通过版本号的比较来达到数据版本控制的目的。
提高并发的演进思路,就在如此:
-
普通锁,本质是串行执行
-
读写锁,可以实现读读并发
-
数据多版本,可以实现读写并发
画外音:这个思路,比整篇文章的其他技术细节更重要,希望大家牢记。
3.2 InnoDB实现MVCC
1)MVCC是怎样实现隔离级别的
MVCC多版本并发控制是MySQL中基于乐观锁理论实现隔离级别的方式,用于读已提交和可重复读取隔离级别的实现。
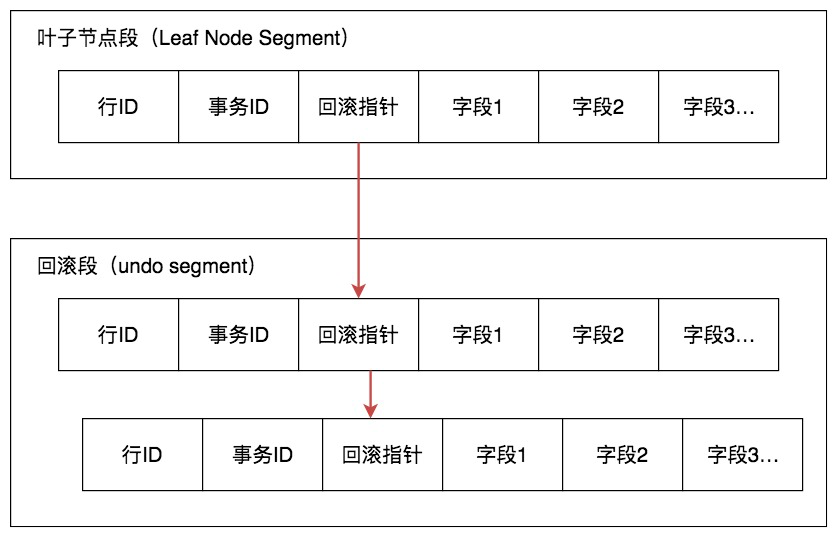
在MySQL中,会在表中每一条数据后面添加两个字段:最近修改该行数据的事务ID,指向该行(undolog表中)回滚段的指针。
Read View判断行的可见性,创建一个新事务时,copy一份当前系统中的活跃事务列表。意思是,当前不应该被本事务看到的其他事务id列表。
已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
2)核心问题
旧版本数据存储在哪里?
旧版本数据存储在回滚段里;
存储旧版本数据,对MySQL和InnoDB原有架构是否有巨大冲击?
对MySQL和InnoDB原有架构体系冲击不大;
3)InnoDB为何能够做到这么高的并发?
回滚段里的数据,其实是历史数据的快照(snapshot),这些数据是不会被修改,select可以肆无忌惮的并发读取他们。
快照读(Snapshot Read),这种一致性不加锁的读(Consistent Nonlocking Read),就是InnoDB并发如此之高的核心原因之一。
这里的一致性是指,事务读取到的数据,要么是事务开始前就已经存在的数据(当然,是其他已提交事务产生的),要么是事务自身插入或者修改的数据。
什么样的select是快照读?
除非显示加锁,普通的select语句都是快照读,例如:
select * from t where id>2;
这里的显示加锁,非快照读(当前读,包括了加锁的读取和 DML 操作)是指:
select * from t where id>2 lock in share mode; select * from t where id>2 for update; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
MVCC 可以解决读写互相阻塞的问题,这样提升了效率,同时因为采用了乐观锁的思想,降低了死锁的概率。
4)数据的隐藏列具体是指什么?
InnoDB的内核,会对所有row数据增加三个内部属性:
- DB_TRX_ID,6字节,记录每一行最近一次修改它的事务ID;
- DB_ROLL_PTR,7字节,记录指向回滚段undo日志的指针;
- DB_ROW_ID,6字节,单调递增的行ID;

5)Read View 是如何工作的
在 MVCC 机制中,多个事务对同一个行记录进行更新会产生多个历史快照,这些历史快照保存在 Undo Log 里。如果一个事务想要查询这个行记录,需要读取哪个版本的行记录呢?这时就需要用到 Read View 了,它帮我们解决了行的可见性问题。Read View 保存了当前事务开启时所有活跃(还没有提交)的事务列表,换个角度你可以理解为 Read View 保存了不应该让这个事务看到的其他的事务 ID 列表。
在 Read VIew 中有几个重要的属性:
- trx_ids,系统当前正在活跃的事务 ID 集合。
- low_limit_id,活跃的事务中最大的事务 ID。
- up_limit_id,活跃的事务中最小的事务 ID。
- creator_trx_id,创建这个 Read View 的事务 ID。
如图所示,trx_ids 为 trx2、trx3、trx5 和 trx8 的集合,活跃的最大事务 ID(low_limit_id)为 trx8,活跃的最小事务 ID(up_limit_id)为 trx2。

假设当前有事务 creator_trx_id 想要读取某个行记录,这个行记录的事务 ID 为 trx_id,那么会出现以下几种情况。
如果 trx_id < 活跃的最小事务 ID(up_limit_id),也就是说这个行记录在这些活跃的事务创建之前就已经提交了,那么这个行记录对该事务是可见的。
如果 trx_id > 活跃的最大事务 ID(low_limit_id),这说明该行记录在这些活跃的事务创建之后才创建,那么这个行记录对当前事务不可见。
如果 up_limit_id < trx_id < low_limit_id,说明该行记录所在的事务 trx_id 在目前 creator_trx_id 这个事务创建的时候,可能还处于活跃的状态,因此我们需要在 trx_ids 集合中进行遍历,如果 trx_id 存在于 trx_ids 集合中,证明这个事务 trx_id 还处于活跃状态,不可见。否则,如果 trx_id 不存在于 trx_ids 集合中,证明事务 trx_id 已经提交了,该行记录可见。
了解了这些概念之后,我们来看下当查询一条记录的时候,系统如何通过多版本并发控制技术找到它:
- 首先获取事务自己的版本号,也就是事务 ID;
- 获取 Read View;
- 查询得到的数据,然后与 Read View 中的事务版本号进行比较;
- 如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照;
- 最后返回符合规则的数据。
你能看到 InnoDB 中,MVCC 是通过 Undo Log + Read View 进行数据读取,Undo Log 保存了历史快照,而 Read View 规则帮我们判断当前版本的数据是否可见。
需要说明的是,在隔离级别为读已提交(Read Commit)时,一个事务中的每一次 SELECT 查询都会获取一次 Read View。如表所示:
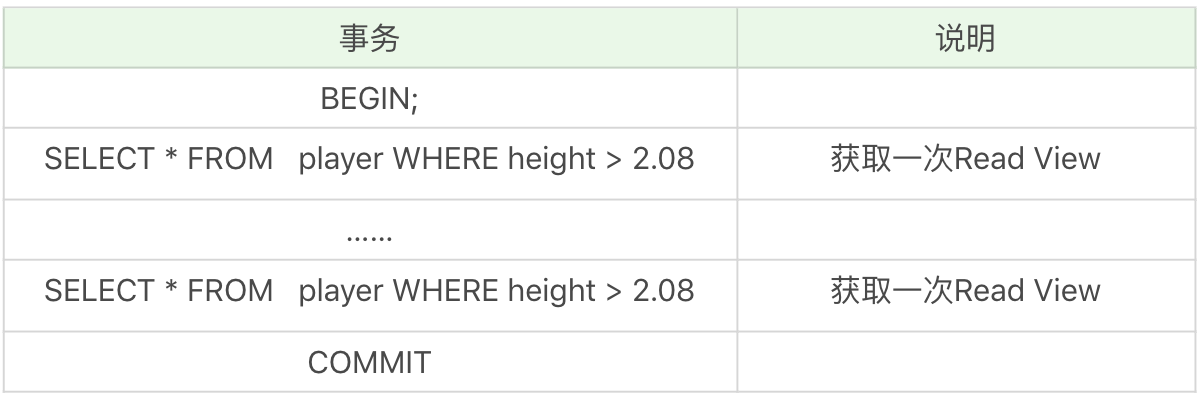
你能看到,在读已提交的隔离级别下,同样的查询语句都会重新获取一次 Read View,这时如果 Read View 不同,就可能产生不可重复读或者幻读的情况。
当隔离级别为可重复读的时候,就避免了不可重复读,这是因为一个事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View,如下表所示:
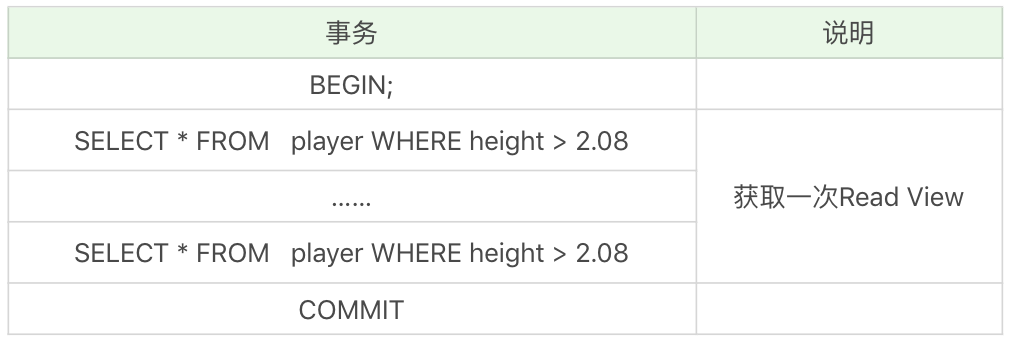
6)InnoDB 是如何解决幻读的
不过这里需要说明的是,在可重复读的情况下,InnoDB 可以通过 Next-Key 锁 +MVCC 来解决幻读问题。
在读已提交的情况下,即使采用了 MVCC 方式也会出现幻读。如果我们同时开启事务 A 和事务 B,先在事务 A 中进行某个条件范围的查询,读取的时候采用排它锁,在事务 B 中增加一条符合该条件范围的数据,并进行提交,然后我们在事务 A 中再次查询该条件范围的数据,就会发现结果集中多出一个符合条件的数据,这样就出现了幻读。

出现幻读的原因是在读已提交的情况下,InnoDB 只采用记录锁(Record Locking)。这里要介绍下 InnoDB 三种行锁的方式:
- 记录锁:针对单个行记录添加锁。
- 间隙锁(Gap Locking):可以帮我们锁住一个范围(索引之间的空隙),但不包括记录本身。采用间隙锁的方式可以防止幻读情况的产生。
- Next-Key 锁:帮我们锁住一个范围,同时锁定记录本身,相当于间隙锁 + 记录锁,可以解决幻读的问题。
在隔离级别为可重复读时,InnoDB 会采用 Next-Key 锁的机制,帮我们解决幻读问题。
还是这个例子,我们能看到当我们想要插入球员艾利克斯·伦(身高 2.16 米)的时候,事务 B 会超时,无法插入该数据。这是因为采用了 Next-Key 锁,会将 height>2.08 的范围都进行锁定,就无法插入符合这个范围的数据了。然后事务 A 重新进行条件范围的查询,就不会出现幻读的情况。

总结
今天关于 MVCC 的内容有些多,通过学习你应该能对采用 MVCC 这种乐观锁的方式来保证事务的隔离效果更有体会。
我们需要记住,MVCC 的核心就是 Undo Log+ Read View,“MV”就是通过 Undo Log 来保存数据的历史版本,实现多版本的管理,“CC”是通过 Read View 来实现管理,通过 Read View 原则来决定数据是否显示。同时针对不同的隔离级别,Read View 的生成策略不同,也就实现了不同的隔离级别。
MVCC 是一种机制,MySQL、Oracle、SQL Server 和 PostgreSQL 的实现方式均有不同,我们在学习的时候,更主要的是要理解 MVCC 的设计思想。
7)临键锁(next-key lock)
InnoDB实现的隔离级别RR时可以避免幻读现象的,这是通过next-key lock机制实现的。
next-key lock实际上就是行锁的一种,只不过它不只是会锁住当前行记录的本身,还会锁定一个范围。比如上面幻读的例子,开始查询0<阅读量<100的文章时,只查到了一个结果。next-key lock会将查询出的这一行进行锁定,同时还会对0<阅读量<100这个范围进行加锁,这实际上是一种间隙锁。间隙锁能够防止其他事务在这个间隙修改或者插入记录。这样一来,就保证了在0<阅读量<100这个间隙中,只存在原来的一行数据,从而避免了幻读。
间隙锁:封锁索引记录中的间隔
虽然InnoDB使用next-key lock能够避免幻读问题,但却并不是真正的可串行化隔离。再来看一个例子吧。

首先提一个问题:
在T6时间,事务A提交事务之后,猜一猜文章A和文章B的阅读量为多少?
答案是,文章AB的阅读量都被修改成了10000。这代表着事务B的提交实际上对事务A的执行产生了影响,表明两个事务之间并不是完全隔离的。虽然能够避免幻读现象,但是却没有达到可串行化的级别。这还说明,避免脏读、不可重复读和幻读,是达到可串行化的隔离级别的必要不充分条件。可串行化是都能够避免脏读、不可重复读和幻读,但是避免脏读、不可重复读和幻读却不一定达到了可串行化。
3 别废话,各种SQL到底加了什么锁?
这个月花了一些功夫写InnoDB:并发控制,MVCC,索引,锁...
有朋友留言:你TM讲了这么多,锁分了这么多类型,又和事务隔离级别相关,又和索引相关,究竟能不能直接告诉我,一个SQL到底加了什么锁!?
我竟无言以对。
好吧,做过简单梳理之后,今天尝试着直接回答,尽量做到不重不漏,各种SQL语句究竟加了什么锁。
一、普通select
(1)在读未提交(Read Uncommitted),读提交(Read Committed, RC),可重复读(Repeated Read, RR)这三种事务隔离级别下,普通select使用快照读(snpashot read),不加锁,并发非常高;
(2)在串行化(Serializable)这种事务的隔离级别下,普通select会升级为select ... in share mode;
【快照读】辅助阅读:
【事务隔离级别】辅助阅读:
二、加锁select
加锁select主要是指:
-
select ... for update
-
select ... in share mode
(1)如果,在唯一索引(unique index)上使用唯一的查询条件(unique search condition),会使用记录锁(record lock),而不会封锁记录之间的间隔,即不会使用间隙锁(gap lock)与临键锁(next-key lock);
【记录锁,间隙锁,临键锁】辅助阅读:
举个栗子,假设有InnoDB表:
t(id PK, name);
表中有三条记录:
1, shenjian
2, zhangsan
3, lisi
SQL语句:
select * from t where id=1 for update;
只会封锁记录,而不会封锁区间。
(2)其他的查询条件和索引条件,InnoDB会封锁被扫描的索引范围,并使用间隙锁与临键锁,避免索引范围区间插入记录;
三、update与delete
(1)和加锁select类似,如果在唯一索引上使用唯一的查询条件来update/delete,例如:
update t set name=xxx where id=1;
也只加记录锁;
(2)否则,符合查询条件的索引记录之前,都会加排他临键锁(exclusive next-key lock),来封锁索引记录与之前的区间;
(3)尤其需要特殊说明的是,如果update的是聚集索引(clustered index)记录,则对应的普通索引(secondary index)记录也会被隐式加锁,这是由InnoDB索引的实现机制决定的:普通索引存储PK的值,检索普通索引本质上要二次扫描聚集索引。
【索引底层实现】辅助阅读:
【聚集索引与普通索引的实现差异】辅助阅读:
四、insert
同样是写操作,insert和update与delete不同,它会用排它锁封锁被插入的索引记录,而不会封锁记录之前的范围。
同时,会在插入区间加插入意向锁(insert intention lock),但这个并不会真正封锁区间,也不会阻止相同区间的不同KEY插入。
【插入意向锁】辅助阅读:
了解不同SQL语句的加锁,对于分析多个事务之间的并发与互斥,以及事务死锁,非常有帮助。
99 直接读这些牛人的原文
MySQL事务,MVCC,undo log,redo log——最全总结!
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号