《Java架构师的第一性原理》63系统架构之高并发
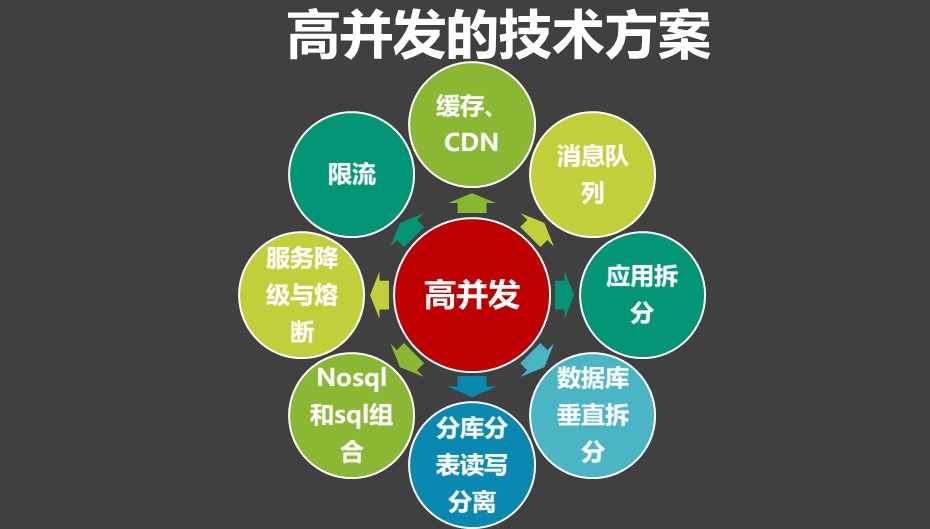
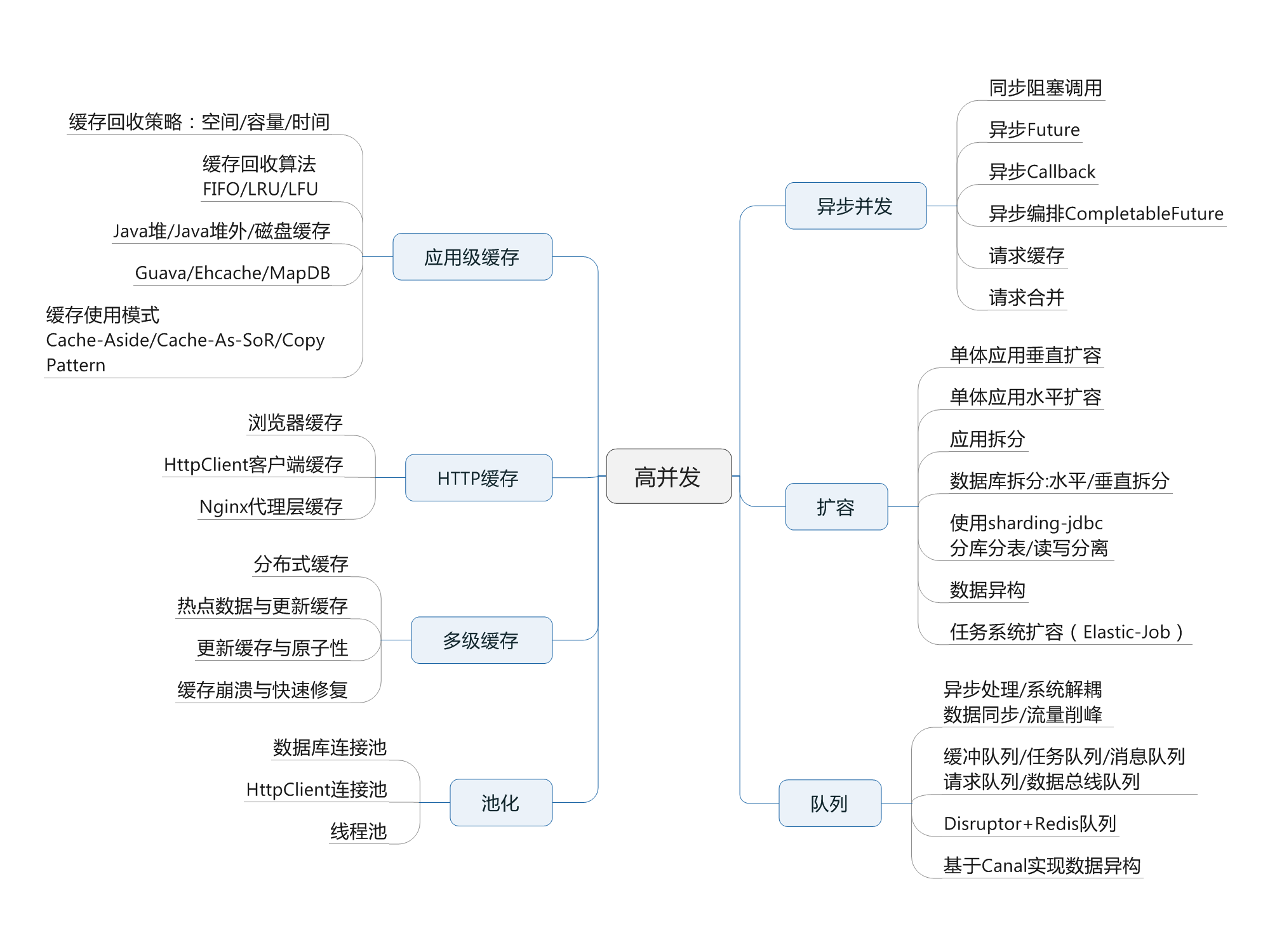
1 什么是高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
2 如何提升系统的并发能力
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:提升单机处理能力。垂直扩展的方式又有两种:
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
3 常见的互联网分层架构
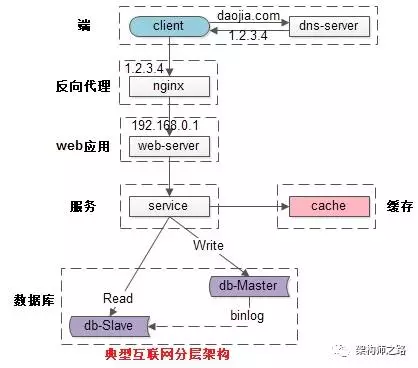
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统各层次的水平扩展,又分别是如何实施的呢?
4 分层水平扩展架构实践
4.1 反向代理层的水平扩展
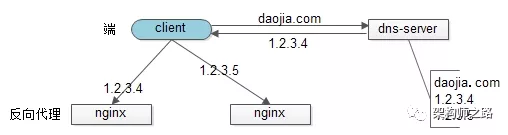
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
4.2 站点层的水平扩展
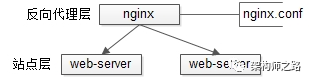
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
4.3 服务层的水平扩展
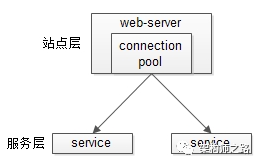
服务层的水平扩展,是通过“服务连接池”实现的。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
4.4 数据层的水平扩展
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
互联网数据层常见的水平拆分方式有这么几种,以数据库为例:
按照范围水平拆分
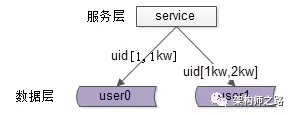
每一个数据服务,存储一定范围的数据,上图为例:
user0库,存储uid范围1-1kw
user1库,存储uid范围1kw-2kw
这个方案的好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(2)数据均衡性较好;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
不足是:
(1) 请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
按照哈希水平拆分
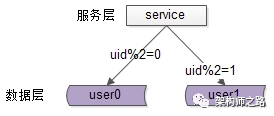
每一个数据库,存储某个key值hash后的部分数据,上图为例:
user0库,存储偶数uid数据
user1库,存储奇数uid数据
这个方案的好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(2)数据均衡性较好;
(3)请求均匀性较好;
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
这里需要注意的是,通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能的方式有本质的不同。
通过水平拆分扩展数据库性能:
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
通过主从同步读写分离扩展数据库性能:
(1)每个服务器上存储的数据量是和总量相同;
(2)n个服务器上的数据都一样,都是全集;
(3)理论上读性能扩充了n倍,写仍然是单点,写性能不变;
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
5 总结
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
6 保护系统:缓存、降级和限流
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。
- 缓存:缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪。使用缓存不单单能够提升系统访问速度、提高并发访问量,也是保护数据库、保护系统的有效方式。大型网站一般主要是“读”,缓存的使用很容易被想到。在大型“写”系统中,缓存也常常扮演者非常重要的角色。比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及HBase写数据的机制等等也都是通过缓存提升系统的吞吐量或者实现系统的保护措施。甚至消息中间件,你也可以认为是一种分布式的数据缓存。
- 降级:服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
- 限流:限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
99 直接读这些牛人的原文
万级TPS亿级流水-中台账户系统架构设计 思维方式:解决机构账户单行热点问题,单行变多行+余额中间表
【修正版】QPS、TPS、RT、并发数、吞吐量理解和性能优化深入思考
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号