《Java架构师的第一性原理》21Java基础之集合容器
1 集合框架总览


- 整个集合框架分为两个门派(类型):Collection和Map,前者是一个容器,存储一系列对象;后者是键值对<key, value>,存储一系列键值对。
- 在集合框架体系下,衍生出四种具体的集合类型:Map、Set、List、Queue。
2 Map集合体系详解
Map的设计理念:定位元素的时间复杂度到O(1)
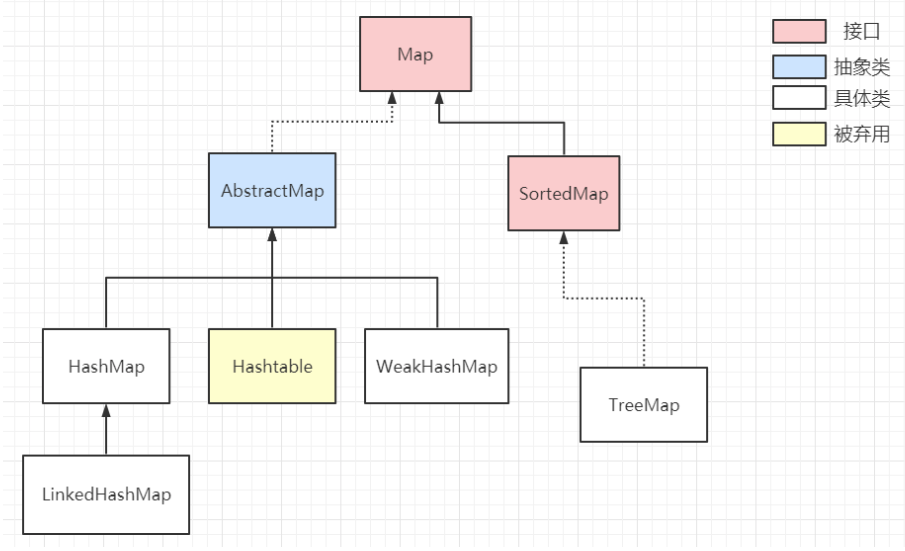
2.1 HashMap
HashMap底层是数据 + 链表 + 红黑树这三种数据结构实现,它是非线程安全的集合。
关于HashMap的简要总结:
- 集合中最常用的Map集合类型,底层由数组 + 链表 + 红黑树组成;
- HashMap不是现成安全的
- 插入元素时,通过计算元素的哈希值,通过哈希映射函数转换为数组下标;查找元素时,同样通过哈希函数得到数组下标定位元素的位置;
2.2 LinkedHashMap
LinkedHashMap可以看作是HashMap和LinkedList的结合:它在HashMap的基础上添加了一条双向链表。
关于LinkedHashMap的简要总结:
- 它底层维护了一条双向链表,因为继承了HashMap,所以它也不是线程安全的;
- LinkedHashMap可实现LRU缓存淘汰策略,其原理是通过设置accessOrder = true,并重写removeEldestEntry方法定义淘汰元素时需满足的条件;
2.3 WeakHashMap
WeakHashMap底层是数据+链表,没有红黑树。
2.4 HashTable
HashTable底层是数组+链表存键值对,是一个线程安全的Map,它所有的方法都被加上了synchronized关键字。
2.5 TreeMap
3 Collection集合体系详解
9 常用面试题
java的集合框架有哪几种:
两种:collection和map,其中collection分为set和List。
List你使用过哪些
ArrayList和linkedList使用的最多,也最具代表性。
你知道vector和ArrayList和linkedList的区别嘛
ArrayList实现是一个数组,可变数组,默认初始化长度为10,也可以我们设置容量,但是没有设置的时候是默认的空数组,只有在第一步add的时候会进行扩容至10(重新创建了数组),后续扩容按照3/2的大小进行扩容,是线程不安全的,适用多读取,少插入的情况
linkedList是基于双向链表的实现,使用了尾插法的方式,内部维护了链表的长度,以及头节点和尾节点,所以获取长度不需要遍历。适合一些插入/删除频繁的情况。
Vector是线程安全的,实现方式和ArrayList相似,也是基于数组,但是方法上面都有synchronized关键词修饰。其扩容方式是原来的两倍。
hashMap和hashTable和ConcurrentHashMap的区别
hashMap是map类型的一种最常用的数据结构,其底部实现是数组+链表(在1.8版本后变为了数组+链表/红黑树的方式),其key是可以为null的,默认hash值为0。扩容以2的幂等次(为什么。。。因为只有是2的幂等次的时候(n-1)&x==x%n,当然不一定只有一个原因)。是线程不安全的
hashTable的实现形式和hashMap差不多,它是线程安全的,是继承了Dictionary,也是key-value的模式,但是其key不能为null。
ConcurrentHashMap是JUC并发包的一种,在hashMap的基础上做了修改,因为hashmap其实是线程不安全的,那在并发情况下使用hashTable嘛,但是hashTable是全程加锁的,性能不好,所以采用分段的思想,把原本的一个数组分成默认16段,就可以最多容纳16个线程并发操作,16个段叫做Segment,是基于ReetrantLock来实现的
说说你了解的hashmap吧
hashMap是Map的结构,内部用了数组+链表的方式,在1.8后,当链表长度达到8的时候,会变成红黑树,这样子就可以把查询的复杂度变成O(nlogn)了,默认负载因子是0.75,为什么是0.75呢?
我们知道当负载因子太小,就很容易触发扩容,如果负载因子太大就容易出现碰撞。所以这个是空间和时间的一个均衡点,在1.8的hashmap介绍中,就有描述了,貌似是0.75的负载因子中,能让随机hash更加满足0.5的泊松分布。
除此之外,1.7的时候是头插法,1.8后就变成了尾插法,主要是为了解决rehash出现的死循环问题,而且1.7的时候是先扩容后插入,1.8则是先插入后扩容(为什么?正常来说,如果先插入,就有可能节点变为树化,那么是不是多做一次树转化,比1.7要多损耗,个人猜测,因为读写问题,因为hashmap并不是线程安全的,如果说是先扩容,后写入,那么在扩容期间,是访问不到新放入的值的,是不是不太合适,所以会先放入值,这样子在扩容期间,那个值是在的)。
1.7版本的时候用了9次扰动,5次异或,4次位移,减少hash冲突,但是1.8就只用了两次,觉得就足够了一次异或,一次位移。
concurrentHashMap呢
concurrentHashMap是线程安全的map结构,它的核心思想是分段锁。在1.7版本的时候,内部维护了segment数组,默认是16个,segment中有一个table数组(相当于一个segmeng存放着一个hashmap。。。),segment继承了reentrantlock,使用了互斥锁,map的size其实就是segment数组的count和。而在1.8的时候做了一个大改版,废除了segment,采用了cas加synchronize方式来进行分段锁(还有自旋锁的保证),而且节点对象改用了Node不是之前的HashEntity。
Node可以支持链表和红黑树的转化,比如TreeBin就是继承了Node,这样子可以直接用instanceof来区分。1.8的put就很复杂来,会先计算出hash值,然后根据hash值选出Node数组的下标(默认数组是空的,所以一开始put的时候会初始化,指定负载因子是0.75,不可变),判断是否为空,如果为空,则用cas的操作来赋值首节点,如果失败,则因为自旋,会进入非空节点的逻辑,这个时候会用synchronize加锁头节点(保证整条链路锁定)这个时候还会进行二次判断,是否是同一个首节点,在分首节点到底是链表还是树结构,进行遍历判断。
concurrentHashMap的扩容方式
1.7版本的concurrentHashMap是基于了segment的,segment内部维护了HashEntity数组,所以扩容是在这个基础上的,类比hashmap的扩容,
1.8版本的concurrentHashMap扩容方式比较复杂,利用了ForwardingNode,先会根据机器内核数来分配每个线程能分到的busket数,(最小是16),这样子可以做到多线程协助迁移,提升速度。然后根据自己分配的busket数来进行节点转移,如果为空,就放置ForwardingNode,代表已经迁移完成,如果是非空节点(判断是不是ForwardingNode,是就结束了),加锁,链路循环,进行迁移。
hashMap的put方法的过程
判断key是否是null,如果是null对应的hash值就是0,获得hash值过后则进行扰动,(1.7是9次,5次异或,4次位移,1.8是2次),获取到的新hash值找出所在的index,(n-1)&hash,根据下标找到对应的Node/entity,然后遍历链表/红黑树,如果遇到hash值相同且equals相同,则覆盖值,如果不是则新增。如果节点数大于8了,则进行树化(1.8)。完成后,判断当前的长度是否大于阀值,是就扩容(1.7是先扩容在put)。
为什么修改hashcode方法要修改equals
都是map惹的祸,我们知道在map中判断是否是同一个对象的时候,会先判断hash值,在判断equals的,如果我们只是重写了hashcode,没有顺便修改equals,比如Intger,hashcode就是value值,如果我们不改写equals,而是用了Object的equals,那么就是判断两者指针是否一致了,那就会出现valueOf和new出来的对象会对于map而言是两个对象,那就是个问题了
TreeMap了解嘛
TreeMap是Map中的一种很特殊的map,我们知道Map基本是无序的,但是TreeMap是会自动进行排序的,也就是一个有序Map(使用了红黑树来实现),如果设置了Comparator比较器,则会根据比较器来对比两者的大小,如果没有则key需要是Comparable的子类(代码中没有事先check,会直接抛出转化异常,有点坑啊)。
LinkedHashMap了解嘛
LinkedHashMap是HashMap的一种特殊分支,是某种有序的hashMap,和TreeMap是不一样的概念,是用了HashMap+链表的方式来构造的,有两者有序模式:访问有序,插入顺序,插入顺序是一直存在的,因为是调用了hashMap的put方法,并没有重载,但是重载了newNode方法,在这个方法中,会把节点插入链表中,访问有序默认是关闭的,如果打开,则在每次get的时候都会把链表的节点移除掉,放到链表的最后面。这样子就是一个LRU的一种实现方式。
99 直接读这些牛人的原文
面经手册 · 第3篇《HashMap核心知识,扰动函数、负载因子、扩容链表拆分深度学习(+实践验证)》
yes的练级攻略:两个高频设计类面试题:如何设计HashMap和线程池
为什么 ConcurrentHashMap 的读操作不需要加锁?
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号