
pandas之数据清洗
数据清洗
数据清洗分为三步:
重复值处理——删除(有几个相同就删除还是全部得相同)
缺失值处理——删除,填充(均值,众数,中位数,前后相邻值),插值(拉格朗日插值,牛顿插值)
异常值处理——describe进行描述性分析+散点图+箱型图定位异常值,处理方法:删除,视为缺失值
导入数据
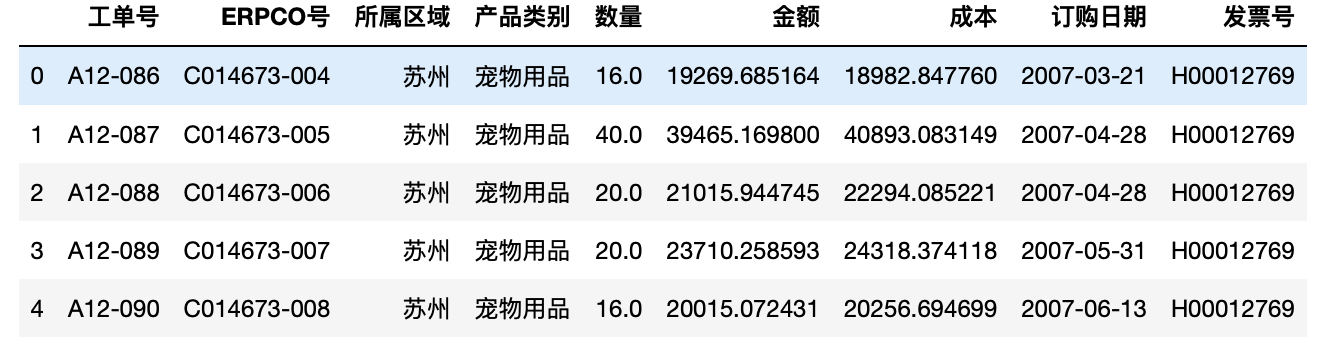
1 import pandas as pd 2 import numpy as np 3 from pandas import Series,DataFrame 4 test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t") 5 test.head(5)#显示前五行
•重复值处理
先查看表中重复值的数量
1 print(test.duplicated().value_counts())
False 189 True 16 dtype: int64
再用drop_duplicates(subset,keep,inplace)方法对某几列下面的重复行删除
subset:以哪几列作为基准列,判断是否重复,如果不写则默认所有列都要重复才算
keep: 保留哪一个,fist-保留首次出现的,last-保留最后出现的,False-重复的一个都不保留,默认为first
inplace: 是否进行替换,最好选择False,保留原始数据,默认也是False
1 test.drop_duplicates(subset=["工单号","ERPCO号"],keep="first",inplace=True) 2 print(test.duplicated().value_counts())#再次查看重复值
False 189 dtype: int64
•缺失值处理
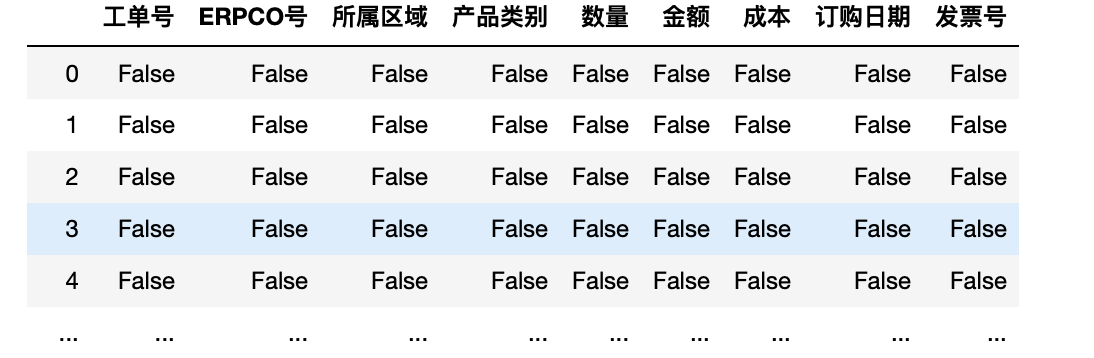
isnull用于检测缺失值,返回bool值
1 test.isnull()
~删除缺失值
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis: 删除行还是列,行是0或index,列是1或column,默认是行
subst: 删除某几列的缺失值,可选,默认为所有列
how: any or all,any表明只要出现1个就删除,all表示所有列均为na才删
thresh: 缺失值的数量标准,达到这个阈值才会删除
inplace: 是否替换
1 test_d=test.dropna(axis=0,how="any",inplace=False)#,inplace=False原数据保留 2 print(test.isnull().any())
工单号 False ERPCO号 False 所属区域 False 产品类别 False 数量 False 金额 False 成本 False 订购日期 False 发票号 False dtype: bool
~填充缺失值
fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None,**kwargs,
#method : {'backfill', 'bfill', 'pad', 'ffill', None}
value: 可以传入一个字符串或数字替代Na,值可以是指定的或者平均值,众数或中位数等
method: 有ffill(用前一个填充)和bfill(用后一个填充)两种
limit: 限定填充的数量
inplace: 是否直接在原文件修改
axis: 填充的方向,默认是0,按行填充
1 test.fillna(method="ffill",inplace=False).isnull().any()
工单号 False ERPCO号 False 所属区域 False 产品类别 False 数量 False 金额 False 成本 False 订购日期 False 发票号 False dtype: bool
对不同列用不同值填充
1 ft=test.fillna(value={"数量":test["数量"].mean(),"金额":test["金额"].median(),"成本":test["成本"].mean()},inplace=False) 2 ft.isnull().any()
工单号 False ERPCO号 False 所属区域 False 产品类别 False 数量 False 金额 False 成本 False 订购日期 False 发票号 False dtype: bool
•异常值处理
~异常值查找
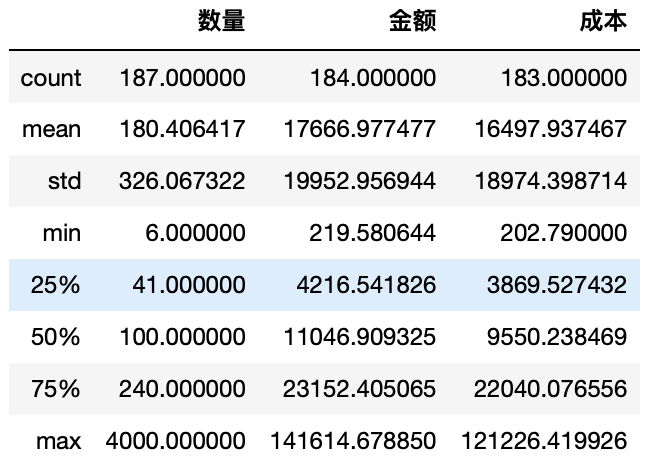
describe()对统计字段进行描述性分析
1 test.describe()
图像观察
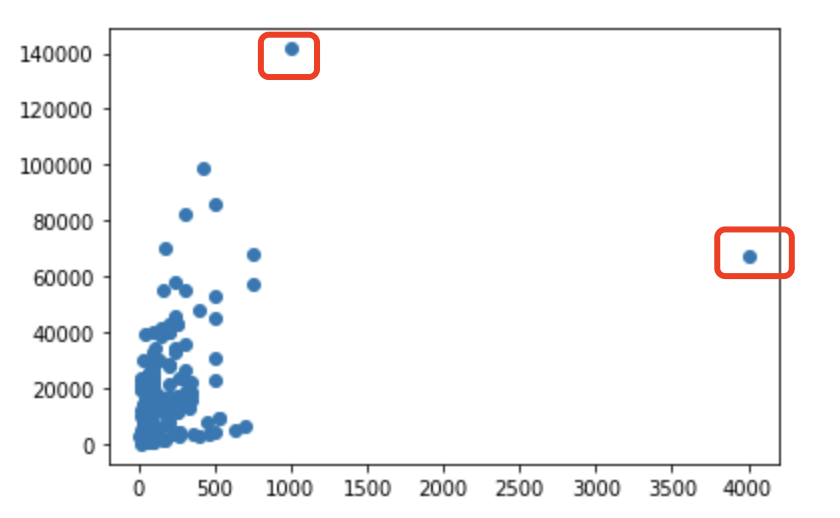
1 from matplotlib import pyplot as plt
1 plt.scatter(test["数量"], test["金额"])
箱型图
1 test.boxplot(column=['数量'])
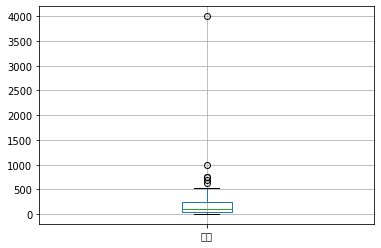
1 test.boxplot(column=['金额'])

1 test.boxplot(column=['成本'])
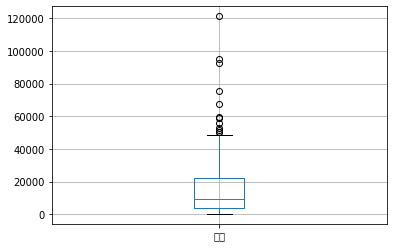
异常值处理:删除或者填充合理的值
通常超过了上四分位1.5倍四分位距或下四分位1.5倍距离都算异常值。
1 a = test["数量"].quantile(0.75) 2 b = test["数量"].quantile(0.25) 3 c = test["数量"] 4 c[(c>=(a-b)*1.5+a)|(c<=b-(a-b)*1.5)]=np.nan 5 c.fillna(c.median(),inplace=True) 6 print(c.describe())
count 189.000000 mean 141.248677 std 129.366651 min 6.000000 25% 42.000000 50% 100.000000 75% 200.000000 max 525.000000 Name: 数量, dtype: float64
1 test.boxplot(column=['数量'])
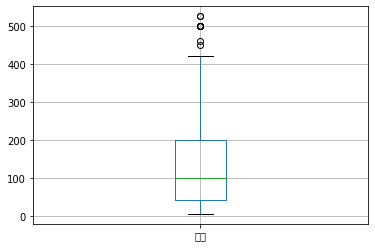
亦或者是直接dropna删除也可
