pandas之数据重塑与透视
数据重塑与透视
•数据重塑
数据重塑表示转换一个表格或者向量的结构,使其适合于进一步的分析。
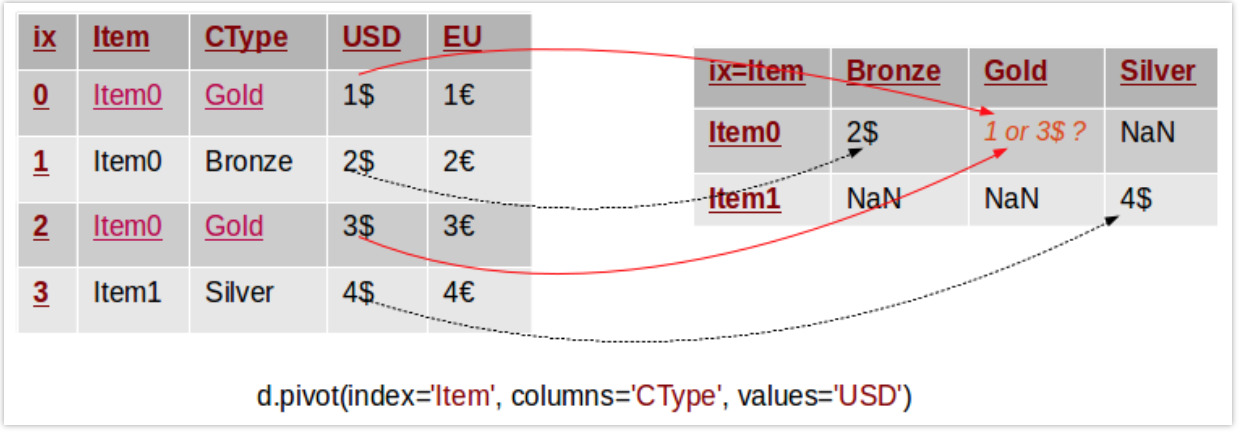
1、pivot:将长格式旋转为宽格式,多用于时间序列。
data.pivot(index=None, columns=None, values=None)
下面举个例子就一目了然了:
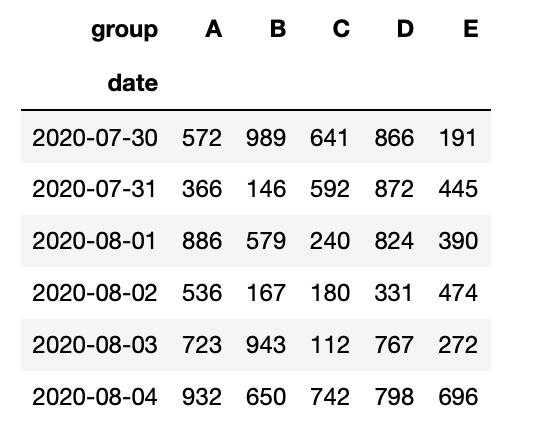
now=datetime.now().date() date=[now-timedelta(days=i) for i in range(6)]*5#列表生成器生成今天到过去五天 group=["A"]*6+["B"]*6+["C"]*6+["D"]*6+["E"]*6 sells=np.random.randint(100,1000,size=(30))#生成100-1000之间的30个随机数 data=pd.DataFrame({"date":date,"group":group,"sells":sells}) data.sort_values(["group","date"])
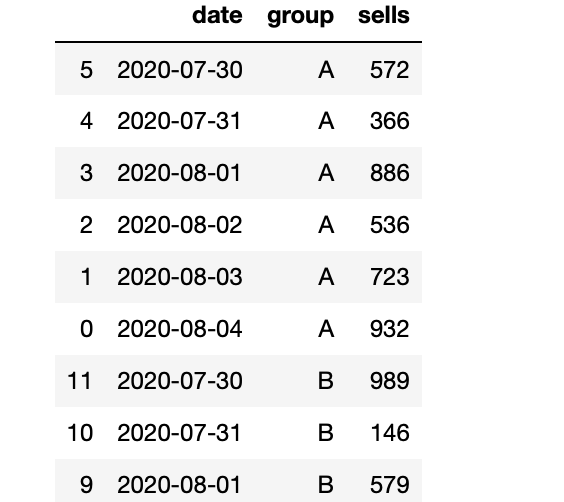
1 dp=data.pivot(index="date",columns="group",values="sells")
2 dp
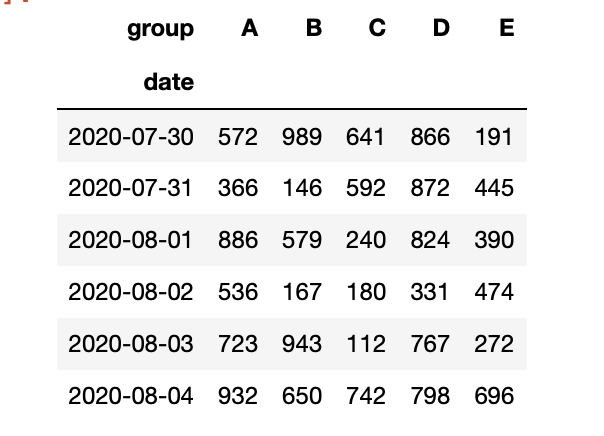
注意:使用pivot时不能有index和cloumns同时相等的
•Stack/Unstack
Stack/Unstack与pivot相比是需要在层次索引上操作,即stack将列变为索引(数据变长了),unstack将索引变为列(数据变宽了)。
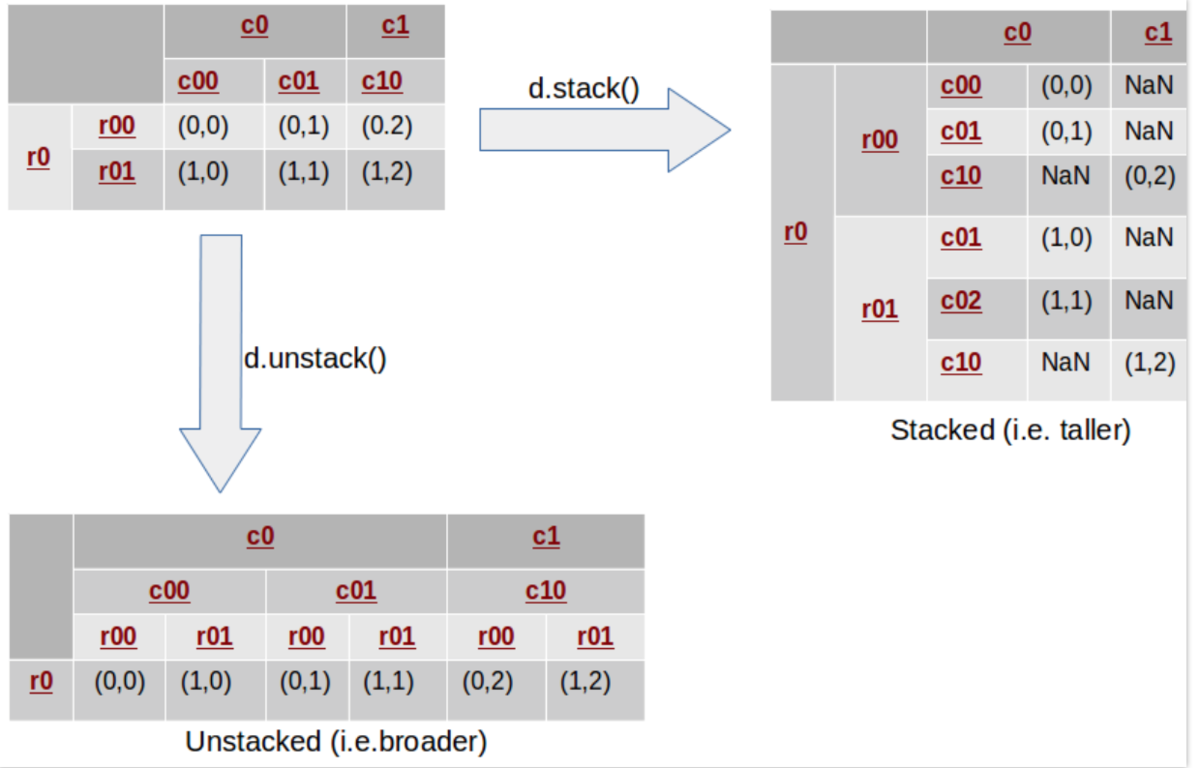
1 ds=dp.stack() 2 ds
date group
2020-07-30 A 572
B 989
C 641
D 866
E 191
2020-07-31 A 366
B 146
C 592
D 872
E 445
2020-08-01 A 886
B 579
.......
1 ds.index#可知把列变为索引了
MultiIndex([(2020-07-30, 'A'),
(2020-07-30, 'B'),
(2020-07-30, 'C'),
(2020-07-30, 'D'),
(2020-07-30, 'E'),
(2020-07-31, 'A'),
(2020-07-31, 'B'),
(2020-07-31, 'C'),
(2020-07-31, 'D'),
..........
unstack将数据变宽
1 ds.unstack(1)#默认把最内层索引变为列
•melt
d1.melt(id_vars=None,value_vars=None,var_name=None,value_name='value', col_level=None,)
id_vars [元组,列表或ndarray,可选]:用作标识符变量的列。
value_vars [元组,列表或ndarray,可选]:要取消透视的列。如果未指定,则使用未设置为id_vars的所有列。
var_name [标量]:用于“变量”列的名称。如果为None,则使用frame.columns.name或“ variable”。
value_name [标量,默认为“值”]:用于“值”列的名称。
col_level [int或字符串,可选]:如果列是MultiIndex,则使用此级别进行融合。
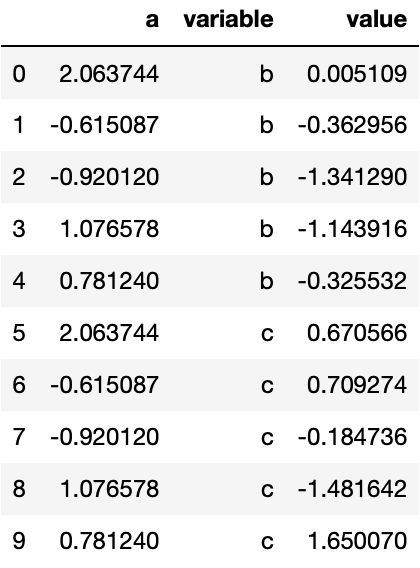
melt()函数很有用,可以将DataFrame压缩为一种格式,其中一列或多列是标识符变量,而所有其他列(被视为测量变量)都不会旋转到行轴,仅留下两个非标识符列,变量和值。简而言之将宽表压缩为长表,可以看成pivot的逆运算。
1 d1=pd.DataFrame(np.random.randn(5,3),index=range(2,7),columns=["a","b","c"]) 2 d1

1 d1.melt(id_vars=["a"],value_vars=["b","c"])
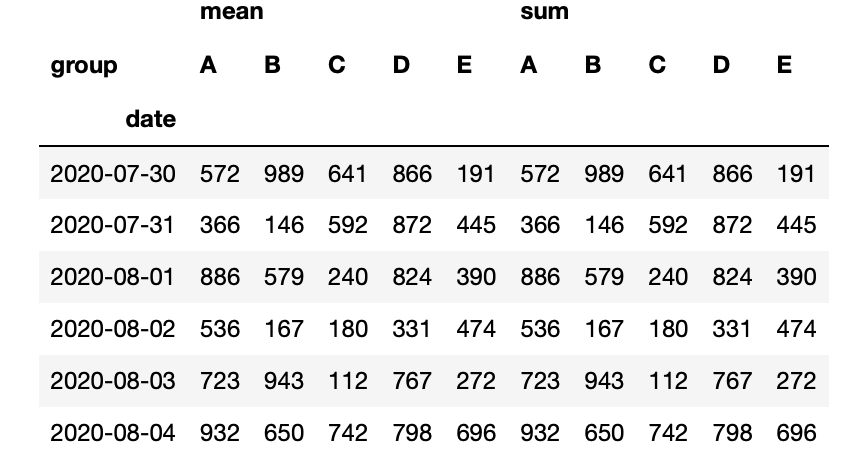
•透视表与交叉表
pivot_table
1 data.pivot_table(index="date",columns="group",values="sells",aggfunc=[np.mean,np.sum])
index也可以为多个
1 导入pandas和numpy库 2 import pandas as pd 3 import numpy as np 4 from pandas import Series,DataFrame 5 test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t") 6 test.head(5)#显示前五行
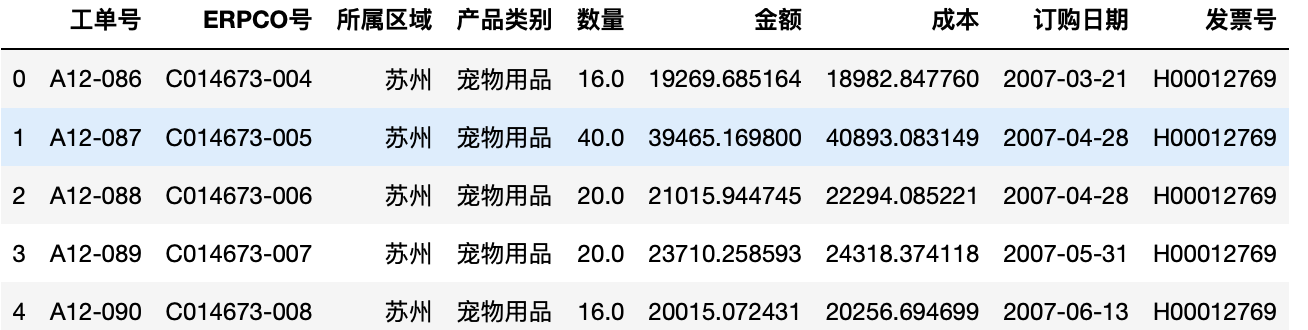
1 pd.pivot_table(test,index=["所属区域","产品类别"],values=["数量","金额"],aggfunc=np.mean)
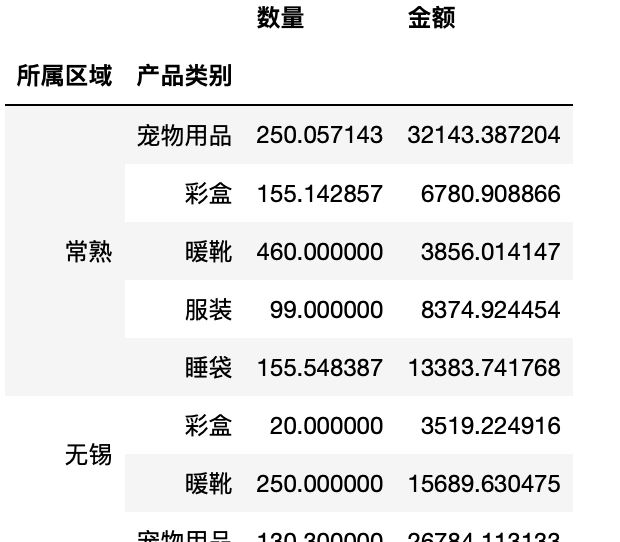
交叉表
cross-tabulation是一种用于计算分组频率的特殊透视表
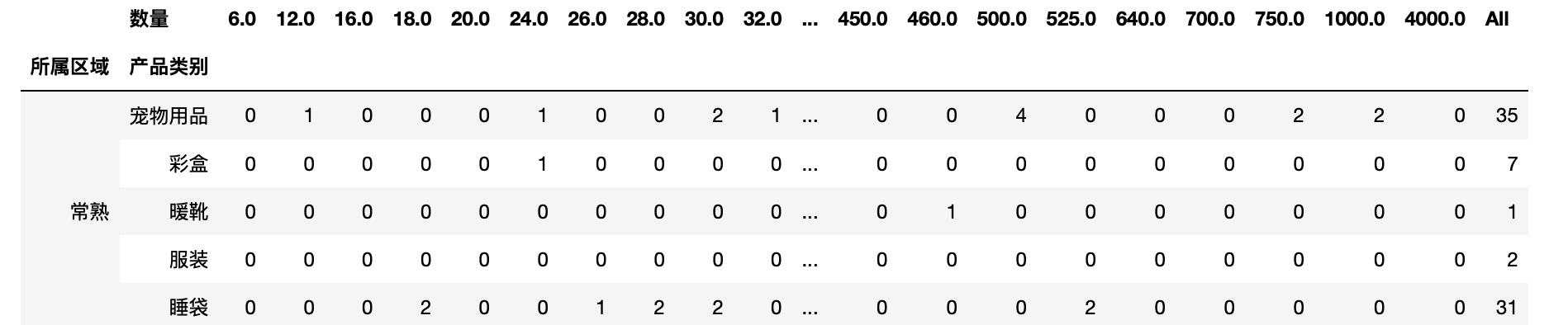
1 pd.crosstab(test["所属区域"],test["产品类别"])
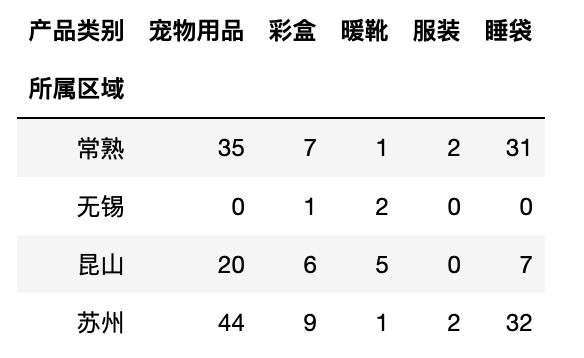
1 pd.crosstab([test["所属区域"],test["产品类别"]],test["数量"],margins=True)