pandas之分组计算groupby
导语:
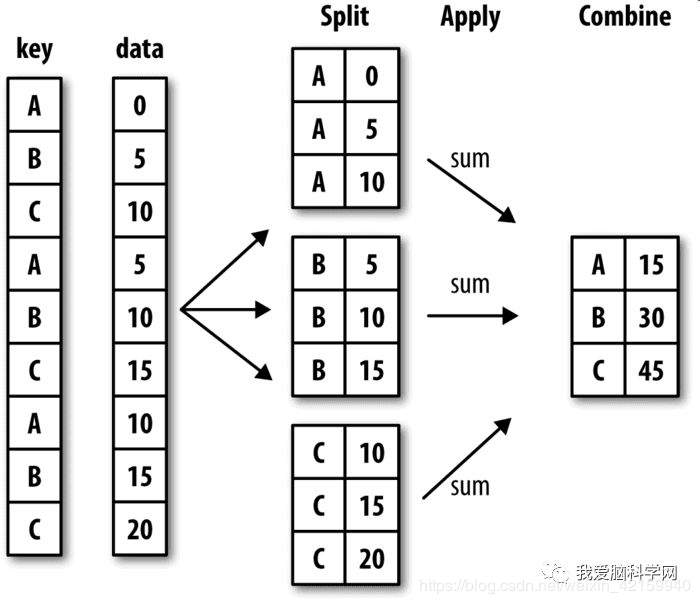
在数据分析中我们经常要拆分列和合并列即拆分-应用-合并,下面放一张经典图
导入数据
1 #导入pandas和numpy库 2 import pandas as pd 3 import numpy as np 4 from pandas import Series,DataFrame 5 test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t") 6 test.head(5)#显示前五行
•groupby
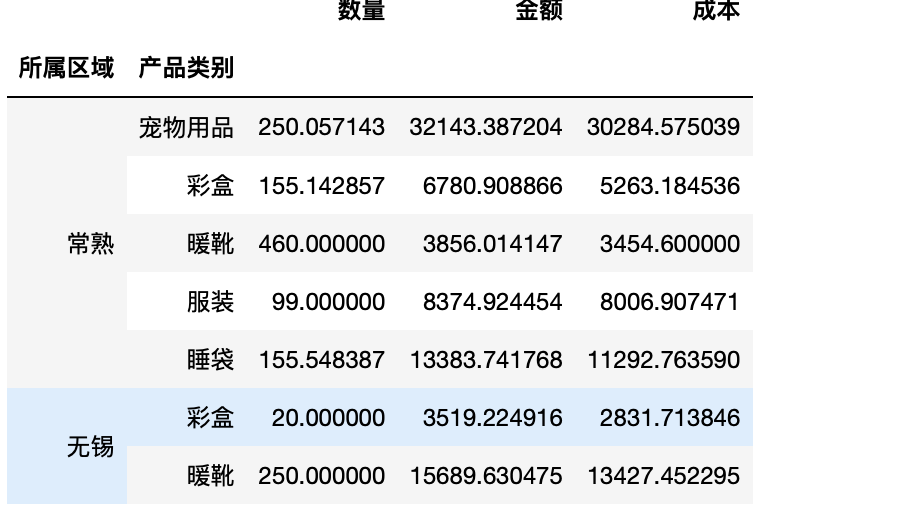
由上图可知我们第一步就是要对数据进行拆分
tg=test.groupby(["所属区域","产品类别"])#分组
1 tg.mean#聚合
~agg
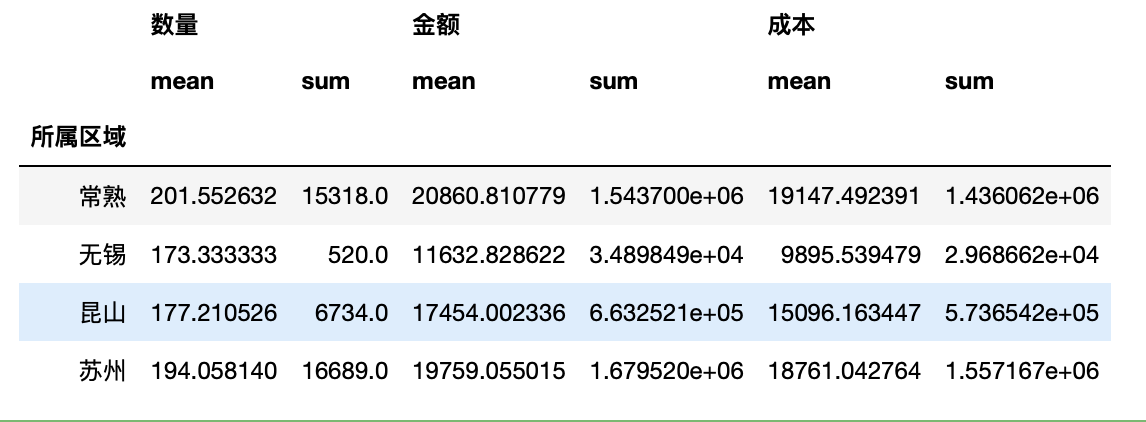
分一组多种聚合方法:.agg([])
1 test.groupby("所属区域").agg([np.mean,np.sum])
多组多种聚合方法
1 test.groupby(["所属区域","产品类别"]).agg([np.mean,np.sum])
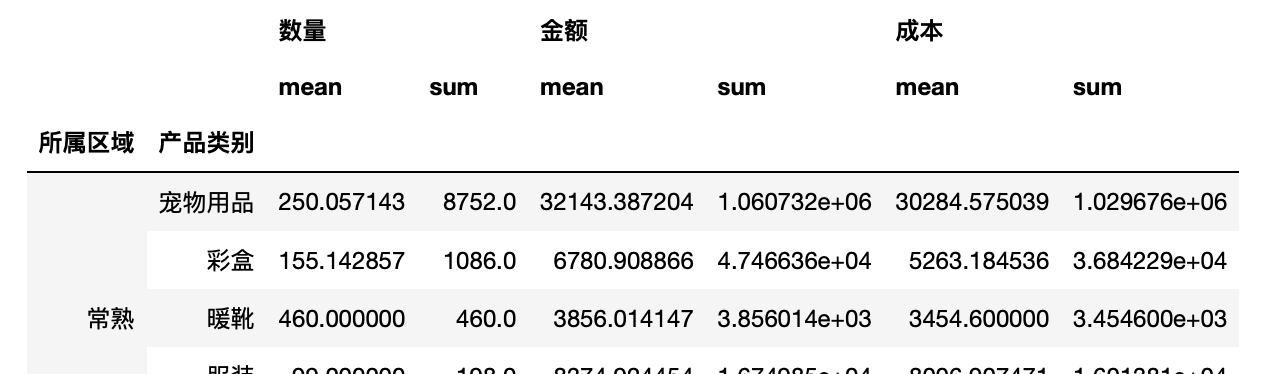
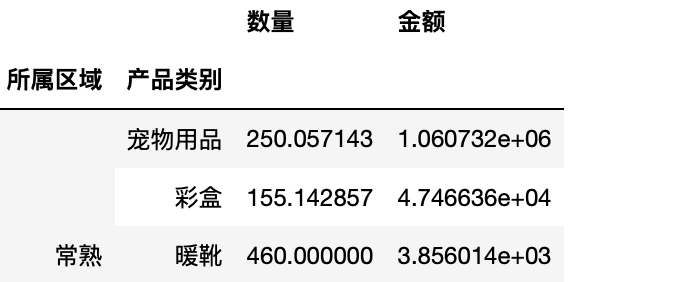
对每列数据进行不同的聚合.agg({})
1 test.groupby(["所属区域","产品类别"]).agg({"数量":np.mean,"金额":np.sum})
~transformation
transform() 里面不能跟自定义的特征交互函数,因为transform是真针对每一元素(即每一列特征操作)进行计算
transform它只能对每一列进行计算,所以在groupby()之后,.transform()之前是要指定要操作的列
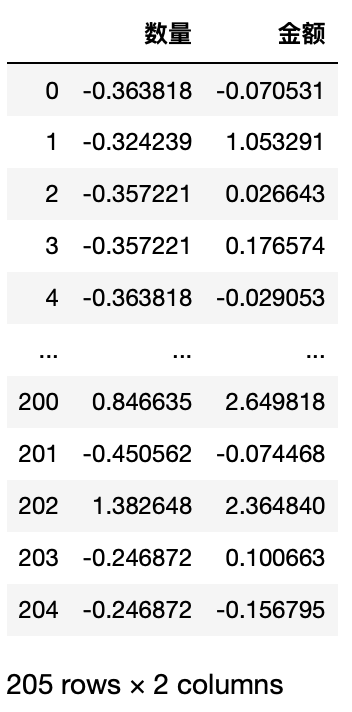
transform是对每个组做运算,再返回所有数据
1 test.groupby(["所属区域","产品类别"])["数量","金额"].transform(lambda x:(x-x.mean())/ x.std())
~filter
filter对分组数据做过滤,相当于sql中是hive
1 tg.filter(lambda x:x["数量"].mean()>=300)
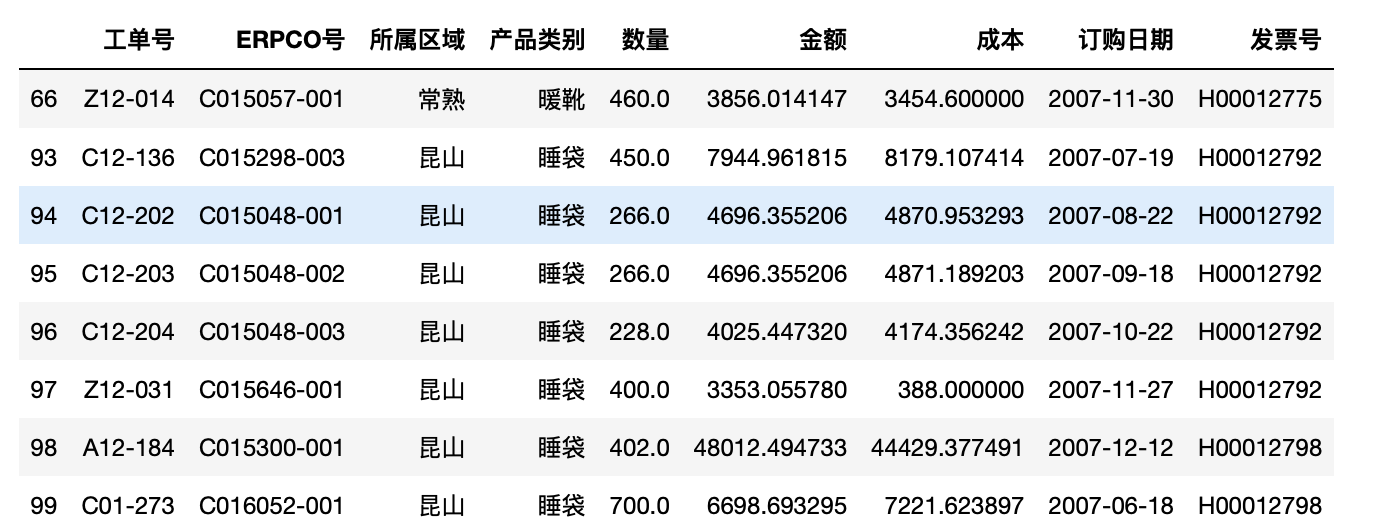
返回每组中平均数>=300的组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号