
Series和DataFrame
•pandas数据结构介绍:
pandas中两大主要的数据结构Series和DataFrame
Series是一种类似一维数组的对象,它由一组数据(numpy数据类型)以及一组与之相关的数据标签(即索引)组成,
DataFrame是一种二维数据结构,是一种表格类型的数据结构(简单的理解像excel),每列可以是不同类型的值。既有行索引也有列索引
•Series
series是能够储存任意形式有标签的一维数组
~用列表创建一个series
1 #列表创建series 2 s1=Series(["I","love","pandas"]) 3 s1
0 I 1 love 2 pandas dtype: objec
1 s1.values#series中的值
array(['I', 'love', 'pandas'], dtype=object)
1 s1.index#series中的索引(没添加自动生成的)
RangeIndex(start=0, stop=3, step=1)
添加标签
1 #自创索引值 2 s2=Series(["I","love","pandas"],index=list("abc")) 3 s2
a I b love c pandas dtype: object
根据标签获取值
1 s2["a":"b"]
a I b love dtype: object
~用字典创建一个series
1 s={"a":2,"b":3,"c":4} 2 s3=Series(s)#k为标签,v为值 3 s3
a 2 b 3 c 4 dtype: int64
可以对索引赋值来修改索引
1 s3.index=list("xyz") 2 s3
x 2 y 3 z 4 dtype: int64
Series运算:会自动对齐不同的索引
1 s4=Series([4,5,6],index=list("axy")) 2 s4
a 4 x 5 y 6 dtype: int64
1 s3*s4
a NaN x 10.0 y 18.0 z NaN dtype: float64
•DataFrame
DataFrame可以被看作Series组成的字典(共用同一索引)
~字典嵌套字典创建
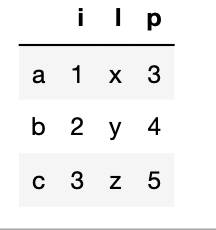
dict1={"i":{"a":1,"b":2,"c":3},"l":{"a":"x","b":"y","c":"z"},"p":{"a":3,"b":4,"c":5}}
df1=pd.DataFrame(dict1)#i、l、p为列名,a、b、c为索引
df1
1 df1["I"]#选取其中一列,看是否为series
a 1 b 2 c 3 Name: i, dtype: int64
1 type(df1["i"])
a 1 b 2 c 3 Name: i, dtype: int64
所以DataFrame的每行每列都是一个Series
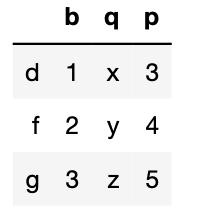
1 df1.columns=list("bqp") 2 df1.index=list("dfg") 3 df1
增加列
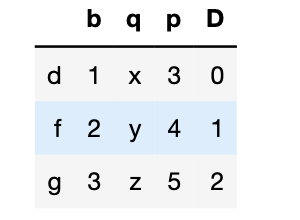
1 df1["D"]=np.arange(3)#直接写出列名赋值即可 2 df1
del 删除列
1 del df1["D"] 2 df1
~列表组成的字典创建(是没有编写索引的)
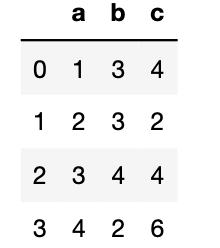
1 dict2={"a":[1,2,3,4],"b":[3,3,4,2],"c":[4,2,4,6]} 2 df2=DataFrame(dict2,index=np.arange(4)) 3 df2
~数组创建
1 array1=[["y","z","l"],["e","j","n"]] 2 dt3=pd.DataFrame(array1,columns=['A',"B","C"],index=['noe','two']) 3 print(dt3)
A B C noe y z l two e j n
#T用于转置 dt3.T


