
Java单列集合Set:HashSet与LinkedHashSet详解,为什么它比List接口更严格?
上篇我们介绍了单列集合中常用的list接口,本篇我们来聊聊单列集合中的另外一个重要接口Set集合。
1、Set 介绍
java.util.Set接口和java.util.List接口一样,同样实现了Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。
与List接口不同的是,Set接口中元素无序,并且都会以某种规则保证存入的元素不出现重复,这里的某种规则,我们在后面中给大家揭秘,大家不要着急。
- 无序
- 不可重复
它没有索引,所以不能使用普通for 循环进行遍历。
Set 集合 遍历元素的方式 迭代器,增强for
来,我们通过案例练习来看看
//创建集合对象
HashSet<String> hs = new HashSet<String>();
//使用Collection的方法添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
//无法添加,在执行这行代码时,会报错误
hs.add("world");
//遍历
for(String s : hs) {
System.out.println(s);
}
- Set接口类型,定义变量,Collection的常用方法 add()没有报错,说明Set 完全实现了Collection中的方法;
- 在添加代码 hs.add("world");无法加入,验证了 Set的不可重复;
- 多次运行遍历发现,输入的顺序是改变的,说明Set是无序的。
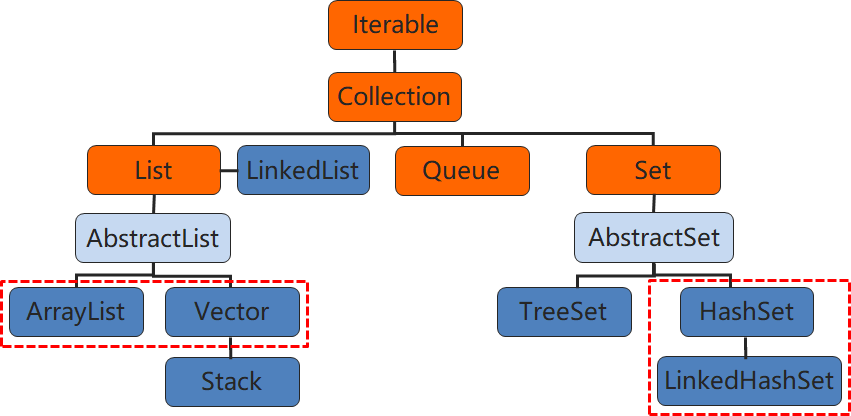
Set集合有多个实现子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet这两个集合。
2、HashSet 集合介绍
通过java文档,我们知道java.util.HashSet是Set接口的一个实现类
-
它所存储的元素是不可重复的
-
元素都是无序的(即存取顺序不一致)
-
没有索引,没有带索引的方法,也不能使用普通for循环遍历
java.util.HashSet 是由哈希表(实际上是一个 HashMap 实例)支持,换句话说它的底层的实现数据结构是 哈希表结构,而哈希表结构的特点是查询速度非常快。
我们先来使用一下HashSet集合,体验一下,在进行讲解:
public class Demo1Set {
public static void main(String[] args) {
//创建集合对象
HashSet<String> hs = new HashSet<String>();
//添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
hs.add("world");
//使用增强for遍历
for(String s : hs) {
System.out.println(s);
}
}
}
输出结果如下
world
java
hello
***发现world 单词只存储了一个,集合中没有重复元素***
3、HashSet集合存储数据的结构
3.1 哈希表数据结构
我们在前面的文章中,已经介绍过基本的数据结构,大家可以回顾一下。
哈希表是什么呢?简单的理解,在Java中,哈希表有两个版本,在jdk1.8 之前,哈希表 = 数组+链表 ,而在 jdk1.8 之后,哈希表 = 数组+链表+红黑树(一种特殊的二叉树) 我们在这里对哈希表的讲述,为了便于我们学习,只需要记住它在计算机中的结构图即可。
你还在苦恼找不到真正免费的编程学习平台吗?可以试试云端源想!课程视频、在线书籍、在线编程、实验场景模拟、一对一咨询…无论你是初学者还是有经验的开发者,这里都有你需要的一切。最重要的是,所有资源完全免费!点这里,立即开始你的学习之旅!
再一个,现在我们大多使用的jdk版本是1.8之后的,所以我们讲解的哈希表结构是 第二个版本。 废话不多说,来看看图吧:
我们在之前已经介绍过数组和链表的结构图,所以我们在这里就来简单介绍一下红黑树结构。

我们在生活中树的结构,树根-树枝-叶子。计算机世界的树,刚好与我们现实中的树成镜像相反,树根在上,树枝在下。那每个树枝上只有不超过两个叶子的就叫做 二叉树,而红黑树就是我们一颗特殊的二叉树,结构就是这样:

说完红黑二叉树呢,我们来看看我们的哈希表结构图:
-
有数组
-
有链表
-
有红黑树

3.2 哈希值
我们刚刚通过哈希表的介绍,知道 元素在结构中的存放位置,是根据hash值来决定的,而 链表的长度达到某些条件就可能触发把链表演化为一个红黑树结构。那么hash值是什么呢?说白了就是个数字,只不过是通过一定算法计算出来的。
接下来我们介绍一下:
-
哈希值:是JDK 根据对象地址或者字符串或者数字算出来的 int 类型的数值
-
如何获取哈希值?
在java基础中,我们学习过 Object类是所有类的基类,每个类都默认继承Object类。通过API 文档查找,有个方法 public int hashCode():返回对象的哈希码值。
我们看下这个方法的使用:
首先定义一个person类
具有两个属性,设置getset方法,设置构造函数
public class Demo2HashCode {
public static void main(String[] args) {
String str1 = "hello";
String str2 = new String("hello");
System.out.println("str1 hashcode =" + str1.hashCode());
System.out.println("str2 hashcode =" + str2.hashCode());
//通过上下两段代码的对比,我们可以知道 String 类重写了HashCode()方法。
Student student = new Student("玛丽", 20);
Student student2 = new Student("沈腾", 30);
System.out.println("student hashcode =" + student.hashCode());
System.out.println("student2 hashcode =" + student2.hashCode());
}
}
好,我们了解了hash值概念和获取方式,那我们就来看看元素事怎么加入到 hashset中的
3.3 添加元素过程
那么向 HashSet集合中,添加一个元素时,到底执行了哪些流程呢? 首先我们在实例化HashSet 对象,同过api文档,在调用空参构造器后,创建了一个长度为16的数组。 其次在调用add方法之后,它的执行流程如下:
1)根据对象的哈希值计算存储位置
- 如果当前位置没有元素则直接存入
- 如果当前位置有元素存在,则进入第二步
2)当前元素的元素和已经存在的元素比较哈希值如果哈希值不同,则将当前元素进行存储如果哈希值相同,则进入第三步
3)通过equals()方法比较两个元素的内容如果内容不相同,则将当前元素进行存储如果内容相同,则不存储当前元素
用流程图来表示:
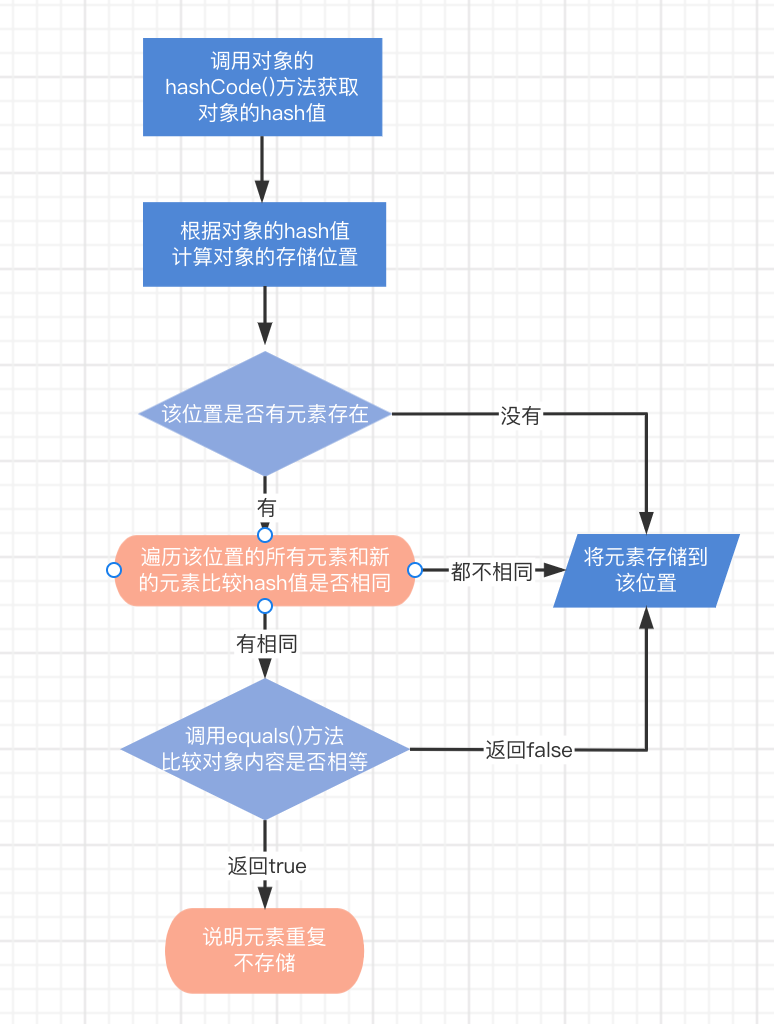
了解了元素添加的原理后,在添加元素的过程中,如果说某一条链表达到一定数量,就会触发条件,去演化为一条红黑树,防止我们学起来太吃力,在这里不做深入探究。 总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
4、HashSet 存储自定义类型元素
//优化后的student
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name.equals(student.name);
}
@Override
public int hashCode() {
int result = name.hashCode();
result = 31 * result + age;
return result;
}
}
public class Demo3HashSet {
public static void main(String[] args) {
HashSet<Student> students = new HashSet<>();
Student student = new Student("玛丽", 20);
Student student2 = new Student("沈腾", 30);
Student student3 = new Student("沈腾", 30);
students.add(student);
students.add(student2);
students.add(student3);
for (Student studentObj : students) {
System.out.println("Hashset 元素=" + studentObj);
}
}
}
执行结果
Hashset 元素=Student{name='玛丽', age=20}
Hashset 元素=Student{name='沈腾', age=30}
5、LinkedHashSet
我们知道HashSet 保证元素的唯一,可以元素存放进去是没有顺序的,那么我们有没有办法保证有序呢? 打开API文档,我们查看 HashSet下面有一个子类 java.util.LinkedHashSet,这个名字听起来和我们之前学过的LinedList 有点像呢。通过文档,LinkedHashSet 具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。 简单的理解为:在进行集合添加元素的同时,不仅经过程序的执行形成一个哈希表结构,还维护了一个记录插入前后顺序的双向链表。 我们通过案例来感受一下:
public class Demo4LinkedHashSet {
public static void main(String[] args) {
// Set<String> demo = new HashSet<>();
Set<String> demo = new LinkedHashSet<>();
demo.add("hello");
demo.add("world");
demo.add("ni");
demo.add("hao");
demo.add("hello");
for (String content : demo) {
System.out.println("---" + content);
}
}
}
执行结果:
第一次:
---world
---hao
---hello
---ni
第二次:
---hello
---world
---ni
---hao
小结
到这里我们已经讲完了单列集合的两种基本接口,分别是List 和 Set,然后通过一些简单的案例,我们也初步了解了它们的使用,其实大家可能还是有些懵逼的;但是在这里,还是要多练习,多看看别人的代码,看看别的优秀的代码,是在怎样的场景下使用的,是怎么互相转换使用的;
希望大家在阅读这个系列文章时,能够受到一点启发,让自己的学习和工作都能更加高效。更重要的是,让大家认识到技术的出现是为了解决问题而创造出来的,它本质上就是为了解决生活中的难题,只不过采用了一些好的、快捷的方式罢了。
可能文章中有些地方讲的不恰当,大家可以私信,探讨探讨,互相提高。本篇就到这里,happy ending!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号