python安装及简单爬虫(爬取导师信息)
1.下载:
解释器(我下的是3.8.2版本):https://www.python.org/downloads/
pycharm(我下的是2019.3.3版本):https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows
注意:python安装时要勾选
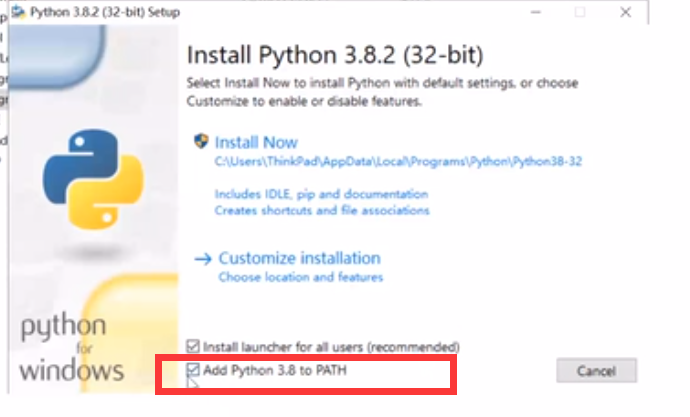
检查python是否安装好可以在cmd命令中输入python,出现下图即可

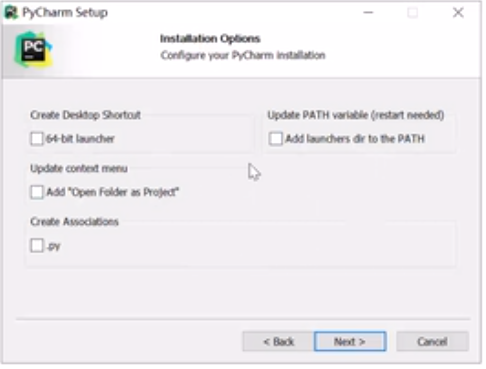
pycharm安装时这四个全选上(只有30天试用期)
JB全家桶永久激活:https://www.exception.site/essay/how-to-free-use-intellij-idea-2019-3
2.爬取网页信息(以浙工大为例)http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id=35


# -*- codeing = utf-8 -*- #@Time : 2022/2/20 16:44 #@Auther : 叶丹薇 #@File : spider.py #@Software: PyCharm from bs4 import BeautifulSoup #网页解析 import re #正则 import urllib.request,urllib.error #制定url 获取网页数据 import sqlite3 #数据库 import xlwt #excel def main(): baseurl="http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id=" #1.爬取网页 datalist=getData(baseurl) savepath="导师.xls" #3保存 saveData(datalist,savepath) findname=re.compile(r'<li><a.*?>(.*?)</a><br/>')#<a href= finddire=re.compile(r'研究方向:(.*?)</a>')#<a href="#">空间信息计算研究所</a> findcoll=re.compile(r'<li><a href="#">(.*?)</a>') #1.爬取网页 def getData(baseurl): datalist=[] for j in range(35,50): url=baseurl+str(j) html=askURL(url) if(html==''):continue #2.逐一解析数据 soup=BeautifulSoup(html,"html.parser") item0=soup.find_all('div',id="boxtitle3") item0=str(item0) colle = re.findall(findcoll,item0)[1] for item in soup.find_all('div',style="width:100%; float:left"):#查找符合要求的字符串 item=str(item) teacher=re.findall(findname,item) director = re.findall(finddire, item) for i in range(len(teacher)): data = [] data.append(teacher[i]) data.append(colle) data.append(director[i]) datalist.append(data) # print(data) # print(datalist) return datalist #得到指定URL的网页内容 def askURL(url): #模拟浏览器头部,进行伪装 head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"} request=urllib.request.Request(url,headers=head)#请求 html="" try: response=urllib.request.urlopen(request)#响应 html=response.read().decode("utf-8") # print(html) except urllib.error.URLError as e: #print("这页没有内容") html='' return html #保存数据 def saveData(datalist,savepath): book=xlwt.Workbook(encoding="utf-8")#创建word对象 sheet=book.add_sheet('老师',cell_overwrite_ok=True)#创建sheet表 col=("姓名","研究所","研究方向") for i in range(0,3): sheet.write(0,i,col[i]) for i in range(0,len(datalist)): #print("第%d条"%(i+1)) data=datalist[i] for j in range(0,3): sheet.write(i+1,j,data[j]) book.save(savepath) if __name__=="__main__": main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号