长链剖分 学习笔记
1. Idea
树链剖分的一种。
设 \(dep_i\) 为节点 \(i\) 与以自身为根的子树内叶子节点距离的最大值。将节点 \(i\) 儿子中 \(dep\) 最大的那个设为节点 \(i\) 的重(长)儿子,其余儿子为轻儿子。如:
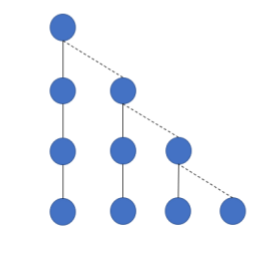
而这样将树剖开,会得到一些性质:
- 所有长链的长度之和为 \(n\)。
由于每个节点属于且仅属于一条长链,证明显然。
- 任何一个节点的 \(k\) 级祖先所在的长链长度一定大于等于 \(k\)。
证明: 设当前节点为 \(u\), \(k\) 级祖先为 \(v\)。若 \(u\) 与 \(v\) 在一条长链上,则显然 \(v\) 所在长链的长度一定大于等于 \(k\);若 \(u\) 和 \(v\) 不在一条长链上,则肯定是因为中间至少有一条轻边而断掉,而之所以断边的父亲不连短边的儿子,肯定是因为另一个儿子更长,故此时 \(v\) 所在长链的长度仍然大于等于 \(k\)。
- 从根到叶子节点所要经过的轻边最多为 \(O(\sqrt{n})\)。
可构造的使 \(\sqrt{n}\) 卡满的树如上图。
在这个方面长链剖分略逊于重链剖分。
2. Example
长链剖分主要用于解决两种问题:
2.1 求树上 \(k\) 级祖先
倍增怎么求 \(\text{k-father}\) 的?先 \(O(n\text{ log }n)\) 预处理出每一个节点的所有二次幂父亲,每次询问时从大到小依次跳即可。
有什么缺点?每次询问需要 \(O(\text{log }n)\) 的时间才能查到答案,虽然很优秀,但在询问次数极多的情况下,还是太慢了!
怎么优化到 \(O(1)\) 呢?我们可以使用长链剖分优化倍增!
预处理方面倍增的复杂度并不劣,依然考虑先预处理一遍每个节点的所有二次幂父亲。那么首先对于二次幂的父亲的询问,我们此时显然是可以 \(O(1)\) 求的 (废话)。
但如果不是二次幂呢?那就先跳到 \(k\) 步以内的最远的二次幂祖先呗,这总是 \(O(1)\) 的吧!
剩下的步数怎么跳?长链剖分正式出马!观察到长链剖分的性质 \(2\):
任何一个节点的 \(k\) 级祖先所在的长链长度一定大于等于 \(k\)。
设我们最远能跳的二次幂步数为 \(h_k\),则显然有 \(k-h_k<h_k\),设 \(h_k\) 级祖先所在长链的长度为 \(r\),则有 \(r\ge h_k>k-h_k\)。
考虑预处理出每条长链最上方节点的前 \(r\) 级父亲和前 \(r\) 级重儿子,根据性质 \(1\):
所有长链的长度之和为 \(n\)。
由于每条长链上的 \(r\) 个点只会在顶点上处理 \(2r\) 次,所以这一部分预处理是 \(O(n)\) 的。
那么这个问题其实就结束了(,由于 \(h_k\) 级祖先距离 \(h_k\) 级祖先所在长链的顶点的长度小于 \(r\),且跳到 \(h_k\) 级祖先后剩余步数 \(k-h_k\) 也小于 \(r\),所以其实剩余的 \(k-h_k\) 步已经跳不出所在长链顶点预处理的范围,被其顶点预处理出的东西涵盖了!
跳 \(h_k\) 步的时间是 \(O(1)\) 的,找到 \(h_k\) 级祖先所在长链的顶点是 \(O(1)\) 的,跳剩余 \(k-h_k\) 步的复杂度更是 \(O(1)\) 的!\(O(1)\) 查询,get!
时间复杂度 \(O(n\text{ log }n)-O(q)\),空间复杂度 \(O(n\text{ log }n)\)。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
#define N 500005
int n,q,s,head[N],tot,gen[N],gtot,dep[N],dis[N],fa[N][22],cson[N],low[N],len[N],la,bl[N];
bool d[N];
ll ans;
vector<int> up[N],down[N];
struct node{
int to,next;
node (int to=0,int next=0)
:to(to),next(next){}
}e[N];
int read(){
int w=0,fh=1;
char c=getchar();
while (c>'9'||c<'0'){
if (c=='-') fh=-1;
c=getchar();
}
while (c>='0'&&c<='9'){
w=(w<<3)+(w<<1)+(c^48);
c=getchar();
}
return w*fh;
}
void adde(int u,int v){
e[++tot]=node(v,head[u]);
head[u]=tot;
}
void dfs(int u){
for (int i=head[u];i;i=e[i].next){
int v=e[i].to;
fa[v][0]=u;
dis[v]=dis[u]+1;
for (int i=1;(1<<i)<dis[v];i++) fa[v][i]=fa[fa[v][i-1]][i-1];
dfs(v);
if (dep[v]>dep[cson[u]]) cson[u]=v;
}
dep[u]=dep[cson[u]]+1;
}
void init(){
for (int i=2;i<=n;i++)
low[i]=low[i>>1]+1;
for (int i=1;i<=n;i++){
if (!d[i]) continue;
for (int now=i,j=1;j<=len[i]&&now;now=fa[now][0],j++){
up[i].push_back(now);
}
for (int now=i,j=1;j<=len[i]&&now;now=cson[now],j++){
down[i].push_back(now);
}
}
}
int dfs2(int u,bool flag,int tp){
d[u]=flag,bl[u]=tp;
if (cson[u]) len[u]=dfs2(cson[u],0,tp);
for (int i=head[u];i;i=e[i].next){
int v=e[i].to;
if (v!=cson[u]){
dfs2(v,1,v);
}
}
return len[u]+1;
}
unsigned int get(unsigned int x) {
x^=x<<13;
x^=x>>17;
x^=x<<5;
return s=x;
}
int query(int u,int k){
if (!k) return u;
u=fa[u][low[k]];
k-=1<<low[k];
int p=bl[u];
// printf("ask:%d %d %d\n",p,u,low[k]);
if (dis[u]-dis[p]>=k){
// printf("query:%d %d %d\n",k,down[p][dis[u]-dis[p]-k],dis[u]-dis[p]-k);
return down[p][dis[u]-dis[p]-k];
}else{
// printf("query:%d %d %d\n",k,up[p].size(),k-dis[u]+dis[p]);
return up[p][k-dis[u]+dis[p]];
}
}
int main(){
n=read(),q=read(),s=read();
for (int i=1;i<=n;i++){
int x=read();
if (x) adde(x,i);
else gen[++gtot]=i;
}
for (int i=1;i<=gtot;i++) dis[gen[i]]=1,dfs(gen[i]);
for (int i=1;i<=gtot;i++) dfs2(gen[i],1,gen[i]);
init();
for (int i=1;i<=q;i++){
int x=(get(s)^la)%n+1,k=(get(s)^la)%dis[x],now=query(x,k);
// printf("%d %d %d\n",x,k,now);
la=now,ans^=(ll)i*now;
}
printf("%lld\n",ans);
return 0;
}
2.2 长链倍增优化处理子树有关深度信息的 dp
这一部分水就比较深了,,拿具体的题为例子吧。
2.2.1 CF1009F Dominant Indices
给定一棵有根树,设 \(d(u,x)\) 为 \(u\) 子树中到 \(u\) 距离为 \(x\) 的节点数。对于每个点,求一个最小的 \(k\),使得 \(d(u,k)\) 最大。
这道题有很多解法,比如 dsu on tree 或者线段树合并等等,这里考虑长链剖分优化 \(dp\)。
先想想普通 \(dp\) 怎么写,很简单,设 \(dp_{i,j}\) 表示节点 \(i\) 子树内距离 \(i\) 深度为 \(j\) 的节点个数,则:
转移的时候顺带处理最优解即可。
但是这种方法显然是非常低效的,时空复杂度均为 \(O(n^2)\)。
可这种方法为什么会这么逊,状态不能再怎么优化了啊?
转移太慢了!如果我们根节点可以直接 \(O(1)\) 继承一个儿子的答案,是不是可以快一点?好像是的哎!
考虑对于每个节点,继承其长链剖分后重儿子的答案,将当前节点的贡献加入和,再将轻儿子的答案暴力合并进来,合并时顺带处理当前节点的答案。由于每个长链的非顶点的答案都会被其父亲继承,复杂度为 \(O(1)\) 级别,而长链顶端的答案会被其父亲暴力合并,设当前长链的长度为 \(r\),则长链顶端一共只有 \(r\) 个深度、也就是 \(r\) 项有答案,合并的时候复杂度为 \(O(r)\),即处理 \(r\) 个节点的时间复杂度为 \(O(r)\),故总时间复杂度为 \(O(n)\)。
那么问题来了,这算法全程和长链剖分有什么关系吗?我重链剖分不也可以?答案当然是有的。因为你要考虑一个很重要的问题:空间。
继承重儿子答案的思路固然不错,但是并不算很好实现。重儿子使用 vector,父亲直接用重儿子的 vector?那父亲本身的贡献难不成加到 vector 的前面?暴力继承?那复杂度岂不是又退化了?
故考虑使用动态内存,对于一条长链的顶点 \(i\),我们申请 \(dep_i\) 的内存给它(\(dep_i\) 的定义如文章前面所示),对于 \(i\) 的重儿子,直接让它的答案放在节点 \(i\) 内存的第 \(2\) 项到第 \(dep_i\) 项;对于轻儿子,则再给轻儿子申请其 \(dep\) 大小的内存即可。由于每条长链只会使用该链长度大小的内存,所以空间复杂度为 \(O(n)\)。至于怎么申请动态内存?建立一个足够大的内存池以及一个记录当前内存申请到哪里了的指向即可!
那么问题又回来了,其它剖分方式为什么不行?很简单,因为申请的内存大小是和节点 \(dep\) 有关的啊!预处理出节点的 \(dep\),才能得到需要空间的大小并进行转移与合并。
由此我们可以进一步看出,长链剖分是用来处理子树内有关深度信息的。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
#define N 1000005
int n,head[N],tot,dep[N],cson[N],fa[N],now,f[N],dp[N],ans[N];
struct node{
int to,next;
node (int to=0,int next=0)
:to(to),next(next){}
}e[N<<1];
int read(){
int w=0,fh=1;
char c=getchar();
while (c>'9'||c<'0'){
if (c=='-') fh=-1;
c=getchar();
}
while (c>='0'&&c<='9'){
w=(w<<3)+(w<<1)+(c^48);
c=getchar();
}
return w*fh;
}
void adde(int u,int v){
e[++tot]=node(v,head[u]);
head[u]=tot;
}
void dfs1(int u){
for (int i=head[u];i;i=e[i].next){
int v=e[i].to;
if (fa[u]!=v){
fa[v]=u;
dfs1(v);
if (dep[v]>dep[cson[u]]) cson[u]=v;
}
}
dep[u]=dep[cson[u]]+1;
}
void dfs2(int u){
if (cson[u]){
f[cson[u]]=f[u]+1;
dfs2(cson[u]);
ans[u]=ans[cson[u]]+1;
}
dp[f[u]]=1;
for (int i=head[u];i;i=e[i].next){
int v=e[i].to;
if (v!=fa[u]&&v!=cson[u]){
f[v]=now,now+=dep[v];
dfs2(v);
for (int i=1;i<=dep[v];i++){
dp[f[u]+i]+=dp[f[v]+i-1];
if (dp[f[u]+i]>dp[f[u]+ans[u]]||dp[f[u]+i]==dp[f[u]+ans[u]]&&i<ans[u])
ans[u]=i;
}
}
}
if (dp[f[u]+ans[u]]==1) ans[u]=0;
}
int main(){
n=read();
for (int i=1;i<n;i++){
int x=read(),y=read();
adde(x,y),adde(y,x);
}
dfs1(1);
f[1]=now,now+=dep[1];
dfs2(1);
for (int i=1;i<=n;i++) printf("%d\n",ans[i]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号