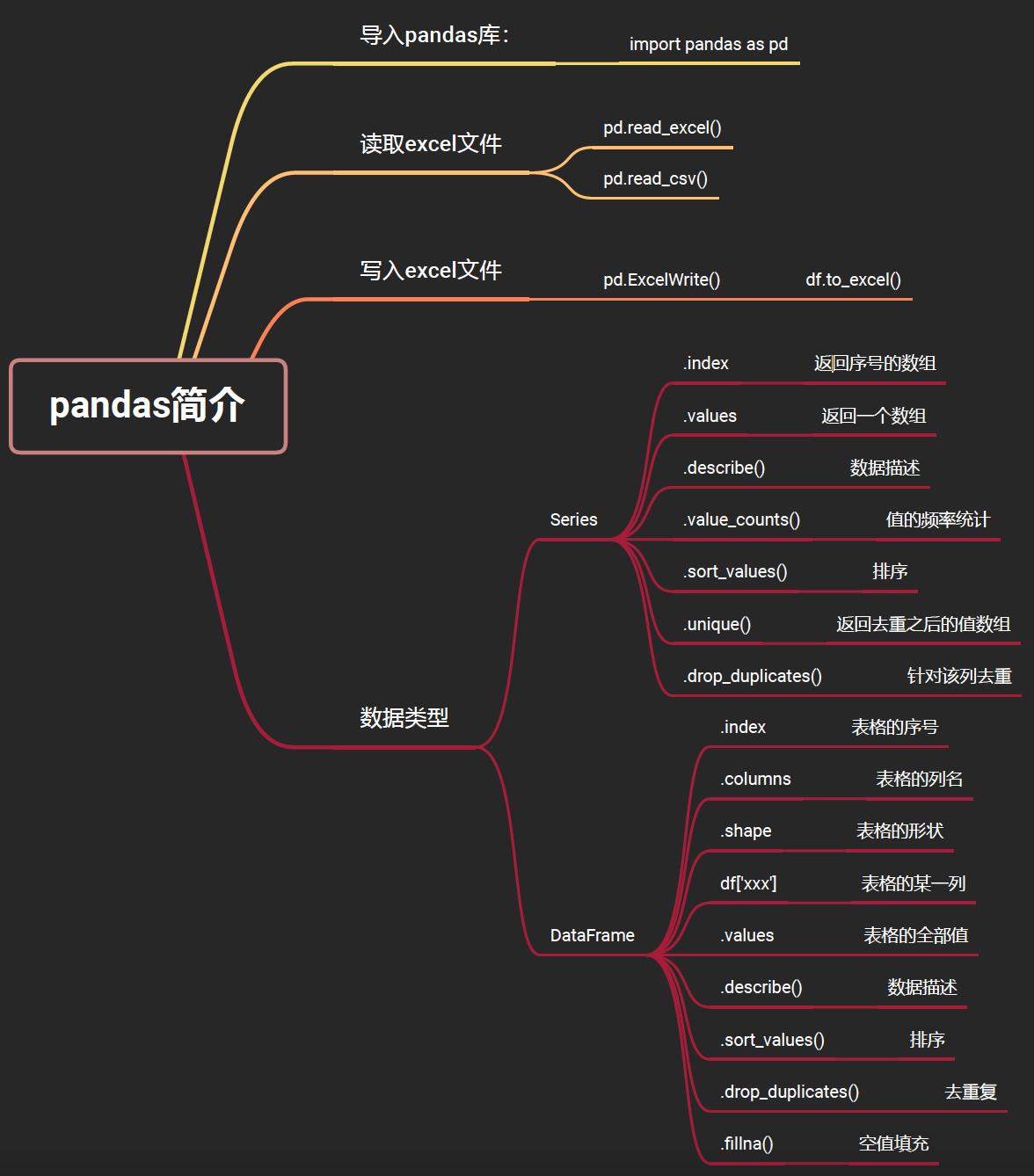
panel data analysis(多维数据分析)
pandas 中具有两种基本的数据存储结构,存储一维 values 的 Series 和存储二维 values 的 DataFrame;
Series:
Series 一般由四个部分组成,分别是序列的值 data 、索引 index 、存储类型 dtype 、序列的名字 name 。其中,索引也可以指定它的名字,默认为空
dtype = 'object’类型,代表了一种混合类型
DataFrame :
在 Series 的基础上增加了列索引,一个数据框可以由二维的 data 与行列索引来构造:值 data由一维变成了二维,加了一个参数columns,给出了列名
2.读取Excel
import pandas as pd
df = pd.read_excel('demo.xlsx')
# 前20行
df.head(10)
# 后20行
df.tail(10)
3.写入Excel
df = pd.DataFrame({
'A':range(10,20),
'B':range(20,30),
'C':range(30,40),
})
with pd.ExcelWriter('./数据表/output.xlsx') as f:
df.to_excel(f, index= False)
withopen('./数据表/output.csv', 'w', newline = '') as f:
df.to_csv(f, index= False)
4.数据类型:Series
import pandas as pd
df = pd.read_excel('./数据表/demo.xlsx')
df.columns
type(df['区县'])
df['区县']
df.区县
# 查看序号
df['区县'].index
# 获取值
df['基站IP'].values
# 修改index
df['区县'].index = range(100,151)
df['区县'].index
# 去重
df['区县'].unique()
# 去重
df['区县'].drop_duplicates()
# 查看数据描述
df['区县'].describe()
# 统计数量
df['区县'].value_counts()
# 排序
df['区县'].sort_values()
5.数据类型:DataFrame
# 表格的形状
df.shape
# 表格的列
df.columns
# 表格的行号
df.index
# 获取某一列的值
df['对应中文名称']
# 查看表格全部数据
df.values
# 注意数据是一列一列显示的
df.describe()
df.drop_duplicates(['厂家'], keep= 'first')
df.备注
df.fillna(0, inplace = True)
df.备注
# 选择行
df[5:10]
# 选择列
df[['区县', '基站名', '对应中文名称']]
# 选择指定行或者列(按列名)
df.loc[10:20,['基站名', '对应中文名称']]
# 选择指定行或者列(按列名)
df.loc[10:20,'区县':'对应中文名称']
# 选择指定行或者列(按序号)
df.iloc[10:20,0:3]
# 跨行选择
df.iloc[[1,3,5,7],[1,3]]
iloc[行索引,列索引](不接受列字段名称作为参数,只支持列字段的位置索引作为参数)
loc[行索引,列名/column](接受具体名称)
6.常用操作
# 拆分表格
df_entry = pd.read_excel('./数据表/报名表.xlsx')
df_entry.columns
# 按所属单位拆分表格
for city in df_entry['所属单位(必填)只到州市'].unique():
df_tmp = df_entry[df_entry['所属单位(必填)只到州市']==city]
with pd.ExcelWriter('./数据表/州市/' + city + '.xlsx') as f:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏