爬虫:将数据存储到文件及数据库(某乎及某吧)
注:本文代码中的cookie都需要替换为读者自己的cookie
1. 将数据导出到文本文档
1.1 测试代码
import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException import time headers = { 'cookie': '', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } # 替换为自己的cookie def get_page(url): try: html = requests.get(url, headers=headers, timeout=5) if html.status_code == 200: print('请求成功') return html.text else: # 这个else语句不是必须的 return None except RequestException: print('请求失败') def parse_page(html): html = BeautifulSoup(html, "html.parser") titles = html.find_all("h2", {'class': 'HotItem-title'})[:10] links = html.find_all('div', {"class": "HotItem-content"})[:10] hot_values = html.find_all('div',{"class": "HotItem-content"})[:10] texts = html.find_all('div', {"class": "HotItem-content"})[:10] return titles, links, hot_values, texts # , title_links def store_data(titles, links, hot_values, texts): with open('热榜测试.txt', 'a') as f: f.write('+'*80 + '\n') f.write(time.asctime().center(80) + '\n') f.write('+'*80 + '\n'*2) index = 1 for title, link, hot_value, text in zip(titles, links, hot_values, texts): print(title.get_text(), '\n', link.a.attrs['href'], '\n', hot_value.div.get_text().replace('\u200b', '')) f.write(str(index) + ': ' + title.get_text() + '\n') f.write(' ' + link.a.attrs['href'] + '\n') f.write(' ' + hot_value.div.get_text().replace('\u200b', ' ') + '\n') # '\u200b'不可见字符 if text.p is None: f.write(' ' + 'None:网页没有显示文章内容' + '\n') else: f.write(' ' + text.p.get_text() + '\n') f.write('\n') index += 1 if __name__ == '__main__': input_url = 'https://www.zhihu.com/hot' a, b, c, d, = parse_page(get_page(input_url)) store_data(a, b, c, d)
1.2 结果截图
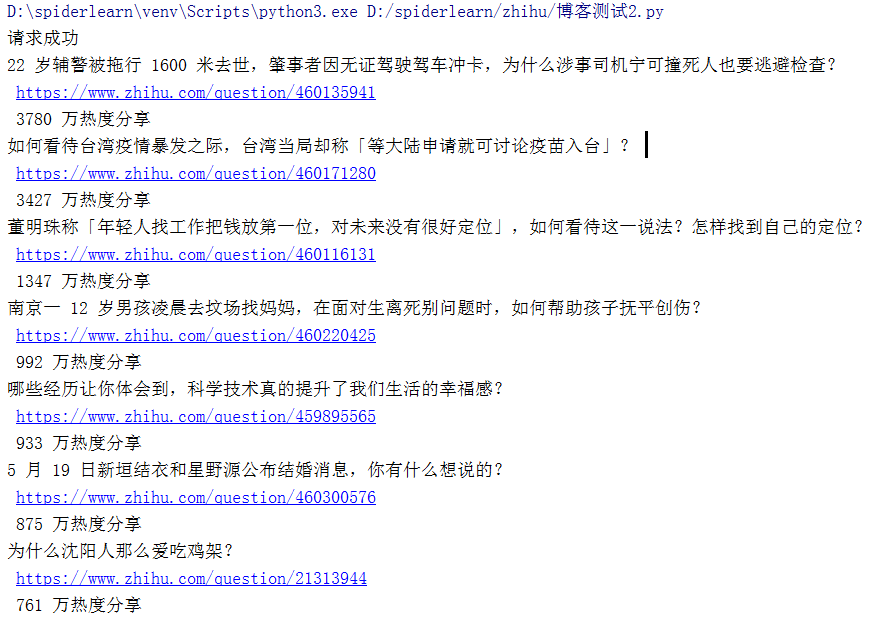
2. 将数据导出到Excel
2.1 测试代码示例
# coding='utf-8' import requests from bs4 import BeautifulSoup import openpyxl from requests.exceptions import RequestException import re import datetime def get_page(url): try: html = requests.get(url) if html.status_code == 200: # print(html.text) return html.text else: return None except RequestException: print('请求失败') def parse_page(html): html = BeautifulSoup(html, 'html.parser') topic_items = html.find_all('div', {"class": "topic-name"}) topic_values = html.find_all('span', {"class": "topic-num"}) topic_statements = html.find_all('div', {"class": "topic-info"}) topic_imgs = html.find_all('li', {"class": "topic-top-item"}) return topic_items, topic_values, topic_statements, topic_imgs def store_data(topic_items, topic_values, topic_statements, topic_imgs): regex = re.compile(r'\d+(\.\d+)?') wb = openpyxl.load_workbook('贴吧热榜Excel.xlsx') sheet = wb['Sheet1'] sheet.freeze_panes = 'A2' for item, value, statement, img in zip(topic_items, topic_values, topic_statements, topic_imgs): print(item.a.get_text(), '\n', item.a['href'], '\n', float(regex.search(value.get_text()).group()), '万') sheet.append([item.a.get_text(), item.a['href'], float(regex.search(value.get_text()).group()), statement.p.get_text(), img.img['src'], datetime.datetime.now()]) wb.save('贴吧热榜Excel.xlsx') def main(url): html = get_page(url) topic_items, topic_values, topic_statements, topic_imgs = parse_page(html) store_data(topic_items, topic_values, topic_statements, topic_imgs) if __name__ == '__main__': input_url = 'http://tieba.baidu.com/hottopic/browse/topicList?res_type=1&red_tag=i0626384809' main(input_url)
2.2 结果截图

3. 将数据写入mysql
3.1 创建数据库
import pymysql db = pymysql.connect(host='localhost', user='root', password='', port=3306) # 替换为自己的密码 cursor = db.cursor() sql = "CREATE DATABASE IF NOT EXISTS test_db" cursor.execute(sql) db.close()
3.1.1 结果截图
打开Navicat便可看到刚刚创建的数据库
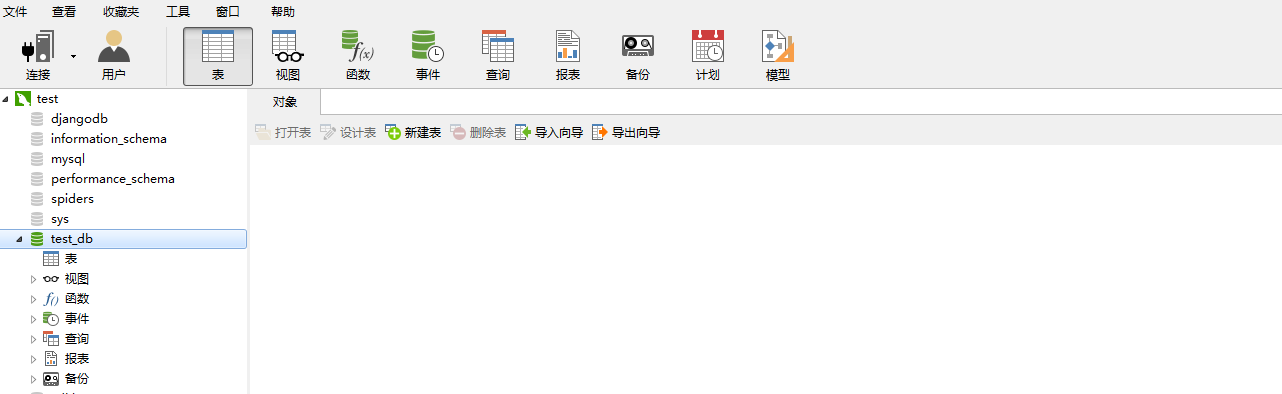
3.2 创建表
下面这个mysql语句将会在以后添加记录的同时自动填充记录的创建时间和更新时间,一般以id为主键,但笔者在这里尝试以title为主键
import pymysql
db = pymysql.connect(host='localhost', user='root', password='', port=3306, db='test_db') # 替换为自己的密码 cursor = db.cursor() sql = """ CREATE TABLE IF NOT EXISTS hot_lists (title VARCHAR(255) NOT NULL, link VARCHAR(255) NOT NULL, value_thousand float(6,1) NOT NULL, content VARCHAR(10000) NOT NULL, create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (title)) """ cursor.execute(sql) db.close()
3.2.2 结果截图
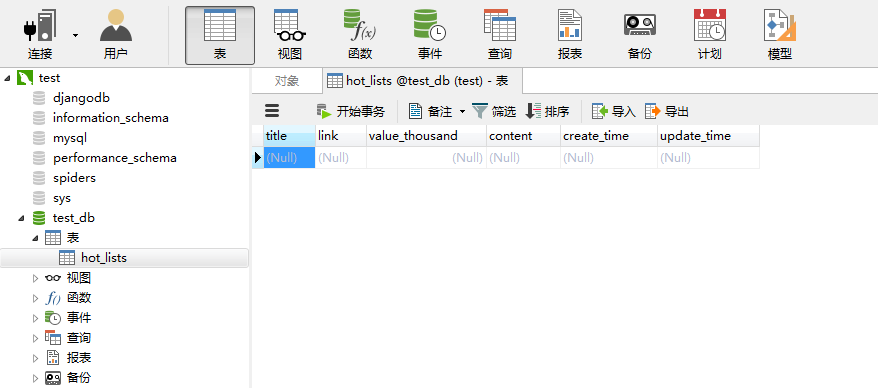
3.3 实践代码测试
import requests from bs4 import BeautifulSoup import pymysql from requests.exceptions import RequestException import random import datetime def get_page(url): headers = { 'cookie': '', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } # 替换为自己的cookie try: html = requests.get(url, headers=headers, timeout=5) # print(html.text) # print(BeautifulSoup(html.text, "html.parser")) return html.text except RequestException: print('请求失败') def parse_page(html): html = BeautifulSoup(html, "html.parser") titles = html.find_all("h2", {'class': 'HotItem-title'})[:10] links = html.find_all('div', {"class": "HotItem-content"})[:10] hot_values = html.find_all('div', {"class": "HotItem-content"})[:10] texts = html.find_all('div', {"class": "HotItem-content"})[:10] return titles, links, hot_values, texts # , title_links def store_data(titles, links, hot_values, texts): con = pymysql.connect(host='localhost', user='root', password='120888', port=3306, db='test_db') cur = con.cursor() sql = 'INSERT INTO hot_lists (title, link, value_thousand, content) VALUES (%s, %s, %s, %s)' for title, link, hot_value, text in zip(titles, links, hot_values, texts): try: if text.p is None: cur.execute(sql, (title.get_text(), link.a.attrs['href'], float(hot_value.div.get_text().replace('\u200b', ' ').split()[0])*10, 'None')) con.commit() else: cur.execute(sql, (title.get_text(), link.a.attrs['href'], float(hot_value.div.get_text().replace('\u200b', ' ').split()[0])*10, text.p.get_text())) con.commit() except: print('Failed') con.rollback() def main(): url = 'https://www.zhihu.com/hot' html = get_page(url) titles, links, hot_values, texts = parse_page(html) store_data(titles, links, hot_values, texts) if __name__ == '__main__': random.seed(datetime.datetime.now()) main()
3.3.1 结果截图
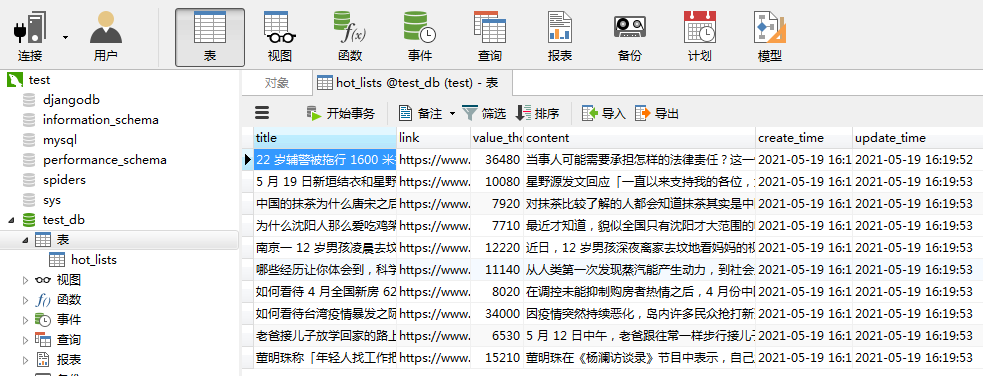
4. 将数据写入mongodb
mongodb操作比mysql简单,不用事先创建数据库和表
4.1 测试代码
import requests from bs4 import BeautifulSoup import pymysql from requests.exceptions import RequestException import random import datetime from pymongo import MongoClient client = MongoClient('localhost') db = client['test_db'] def get_page(url): headers = { "cookie": '', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } # 替换为自己的cookie try: html = requests.get(url, headers=headers, timeout=5) # print(html.text) # print(BeautifulSoup(html.text, "html.parser")) return html.text except RequestException: print('请求失败') def parse_page(html): html = BeautifulSoup(html, "html.parser") titles = html.find_all("h2", {'class': 'HotItem-title'})[:10] links = html.find_all('div', {"class": "HotItem-content"})[:10] hot_values = html.find_all('div', {"class": "HotItem-content"})[:10] texts = html.find_all('div', {"class": "HotItem-content"})[:10] return titles, links, hot_values, texts # , title_links def store_data(titles, links, hot_values, texts): for title, link, hot_value, text in zip(titles, links, hot_values, texts): try: if text.p is None: db['hot_lists'].insert({"title": title.get_text(), "link": link.a.attrs['href'], "value_thousand": float(hot_value.div.get_text().replace('\u200b', ' ').split()[0])*10,"content": 'None'}) else: db['hot_lists'].insert({"title": title.get_text(), "link": link.a.attrs['href'], "value_thousand": float(hot_value.div.get_text().replace('\u200b', ' ').split()[0]) * 10, "content": text.p.get_text()}) except: print('Failed') def main(): url = 'https://www.zhihu.com/hot' html = get_page(url) titles, links, hot_values, texts = parse_page(html) store_data(titles, links, hot_values, texts) if __name__ == '__main__': random.seed(datetime.datetime.now()) main()
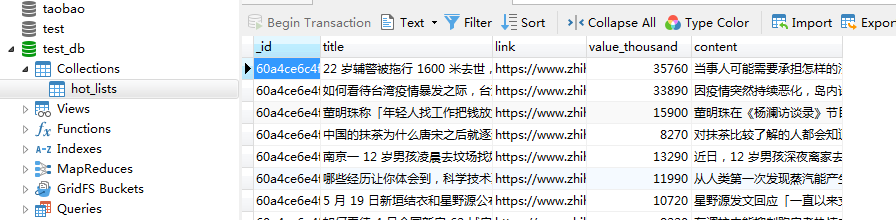
4.2 结果截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号