python mysql redis mongodb selneium requests二次封装为什么大都是使用类的原因,一点见解
1、python mysql redis mongodb selneium requests举得这5个库里面的主要被用户使用的东西全都是面向对象的,包括requests.get函数是里面每次都是实例化了一个新的Session类实例,只是看起来是调用函数,要想精确控制使用,直接使用requests get函数和post函数是不够用的。所以可以下个结论这5个库都是面向对象的。
2、通常情况下,这些库都是偏底层使用,暴露了很多基础api方法,大部分情况下会被用户进行二次封装来适合自己更好用。
在对这5个包进行二次封装的时候,看了几十份网上代码,也几乎是也是面向对象来封装。
3、在去年时候,我只是觉得他们那些封装类的很流弊,自己也一直全纯函数硬怼,看了他们的代码后,也希望是照葫芦画瓢使用类,但是始终不得要义,因为他们写的东西虽然看得很难写,但调用起来却很爽。
4、经厉过一段时间的纯函数编程。也就是不管什么项目,不管实现任何功能,代码里面始终只有0个类。
有的东西是教程文档上必须要求你继承一个类或者必须写个鸭子类,这种肯定不算自己的类了,因为这只是按照教程照葫芦画瓢,教程说要那么写就那么写,这种类就肯定不算自己的了,比如unittest要用它就必须写个类继承TestCase类,网上所有unittest测试都是教我们这么写的,那么代码里面这种类肯定必须排除在外。除开这些文档上规定死了的,代码里面就是只有0个类了。
5、以这五个库为例,为什么包括二次封装时候还要用类呢,经过长期的oop和面向过程编程的经验总结一下几点原因:
1)、在二次封装这5个包始终有一个客观东西存在,任何封装的方法/函数一定是在围绕这个客观东西在打转,例如在mysql里面是conection、 cursor,selneium里面是driver,requests里面是session,redis里面是redisclient,不管你要封装什么自己的公有操作方法,那一定100%绕不开这个客观的东西,必须使用到它了,当然也可以从一个函数里面返回connection 、driver,然后把这个东西传给每一个函数,这样就造成每个函数的第一个参数永远是这个东西,看起来很垃圾,在pycharm自动补全上也没有任何优势,用模块来充当命名空间进行补全比用类型来充当命名空间进行函数或方法补全,体验上差了一些。使用纯函数封装得到的是一只残狗,这狗不能跑,没有嘴巴,想跑必须把它传给一个跑的函数,跑(狗,‘北京’),让狗跑到北京;吃(狗,‘骨头’)让狗吃骨头,狗有多少种技能,就要把这个残狗传多少次给函数,始终要传递它,构建一个真正的狗,他会有嘴巴,他自己就能跑,不需要把这只狗在各个方法传来传去的。使用类的第一个原因是代码补全厉害,补全命名空间更细,第二个原因是代码简洁,不用重复传参,第三个原因是类在自身实力维护状态数值和属性,不需要在代码块外面保存这些东西。
2)、如果不从一个函数返回driver conn这种东西,然后再把这个东西重复传给所有函数,那可以把它写成全局变量就不需要传递那么多次给其他函数了,那这样就造成还没开始使用就弹出浏览器,还没开始使用就连接数据库,并且写成全局变量,一定是写死了,那怎么给他设置不同的ip和密码?只能去修改全局变量了,但作为被调用的模块,还要去修改自身的东西,肯定不合理了,要同时操作两个数据库怎么办,肯定不能写死。所以使用类的第四个原因是为了方便初始化不同的配置,第五个原因是类可以多重实例,同时操作两个数据库,同时requests操作两个账号cookie,用类多重实例更方便,模块是个单例的。
以上是从mysql redis mongodb selneium requests这5个python包为什么老喜欢用类封装,而不喜欢写一堆函数封装,得出的结论。
二次封装这5个官方包肯定不会使用继承的,一定是使用组合,具体模式是代理模式。我没看见有几个代码去继承官方webdriver类、继承pymysql的conection类,几乎没网友会这么做,包括写得好的包里面:requests里面肯定是没有继承urllib,torndb肯定没有继承MySQLdb。
虽然二次封装这5个包看不到继承的优势,但在其他场景下类比纯函数相比,确实有个杀手锏就是继承。
不光是基础公用模块使用类来实现有强大的优势,包括业务流程类的代码使用类都有强大的优势。
具体就是最近重构了一个功能,然来功能平台分国内国外,完全是两个独立模块文件,写完一个复制另一个,但因为有些不同,在另一个文件里面硬是扣字母来处理不同点修改得来的,这样就要维护两份文件,重构原因是很难看懂里面的变量,尤其是巨大的json解析这块,从一个json解析一个键后,这个建的值可能得到的是整形 字符串列表 字典,然来的命名乱七八糟,然后还对json的内容了一些计算,没有类型注释和起一堆乱七八糟的名字真的是很难记住,所以很不好修改。在修改国外时候明明按照国内的修改,但仍然出错,只能逐行比较,最好还是放弃了,因为我也是靠猜测来修改国内的可能是瞎猫碰死老鼠,实在是看不懂,最后只能重构了。重构前然来国内是281行,国外是312行,然后redis广播监听处理文件大概是150行,然来实现这个平台用了700行,但用了继承后,国内国外总共加起来只有216行,因为所有平台本身就有一个基类,再加上国外还能继承国内重写一些属性和方法就可以了。所以216行比最少的那个281行还少了70行,在加上广播处理也是使用了继承,只用了13行代替了然来150行。这样算起来,oop重构后比完全纯函数写法少了70%的行的代码。所以说写类很繁琐,写函数简单粗暴,这种说法不攻自破。
例如,redis广播监听处理,重构后,任何平台不管国内外只需要13行代码,重构前每次一个新平台都要复制之前的150行,然后在里面扣字眼修改大概几十处字母,包括根据不同平台和国内外区分打印不同的日志字眼和调用不同的函数一共十几处。
重构后因为复用了以前的基类,所以只写了13行就可以代替150行,而且基本不会出现复制粘贴后扣字修改遗漏导致出错。
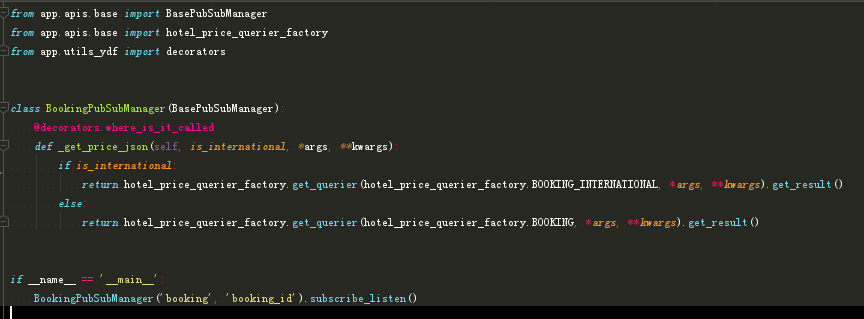
6、如果对oop嗨非常反对,那可以思考下这5个包的二次封装为什么大都是类,不能看网上别人用类你就照葫芦画瓢用类(因为其实用函数也可以实现二次封装的),自己构思想下如果纯函数封装会有哪些缺点和优点?
任何都是先问是不是,再问为什么?关于是不是oop比纯函数在二次封装这5个包时候比例更高,这一点可以多找找网上的公开代码和pypi官网中随便找几十个数据库二次封装的包来证实。
不管写得好坏,使用百度搜索,贴出一些使用python来二次封装操作mysql selnium的文章地址
Python一个简单的数据库类封装
LightMysql:为方便操作MySQL而封装的Python类
python mysql 封装
python连接mysql数据库封装
Python封装的访问MySQL数据库的类及DEMO
selenium基础框架的封装(Python版)
Python_selenium二次封装selenium的几个方法
史上最强大的python selenium webdriver的包装
selenium + python自动化测试unittest框架学习(五)webdriver的二次封装 (唯一一个使用函数)
Day17-selenium的二次封装
webdriver+expected_conditions二次封装
贴出的11个有10个使用了类,有一个使用函数,所以可以看到,二次封装这些东西时候90%的人也会使用类。这个使用函数封装的人正是中了我说的不写类的原因里面的第二个原因的圈套,既减少重复传参,该文章由于既不愿意把driver写成全局变量,也不愿意使用类,所以把driver变量作为了几十个函数的第一个参数,如果再增加几十个函数,会反复传参几百次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号