python 函数结果缓存一段时间的装饰器
把函数结果缓存一段时间,比如读取一个mongodb,mongodb中的内容又在发生变化,如果从部署后,自始至终只去读一次那就感触不到变化了,如果每次调用一个函数就去读取那太频繁了耽误响应时间也加大了cpu负担,也不行。那就把结果缓存一段时间。
来一个缓存一段时间的装饰器。
class FunctionResultCacher: logger = LogManager('FunctionResultChche').get_logger_and_add_handlers() func_result_dict = {} """ { (f1,(1,2,3,4)):(10,1532066199.739), (f2,(5,6,7,8)):(26,1532066211.645), } """ @classmethod def cached_function_result_for_a_time(cls, cache_time): """ 函数的结果缓存一段时间装饰器 :param cache_time 缓存的时间 :type cache_time : float """ def _cached_function_result_for_a_time(fun): @wraps(fun) def __cached_function_result_for_a_time(*args, **kwargs): if len(cls.func_result_dict) > 1024: cls.func_result_dict.clear() key = cls._make_arguments_to_key(args, kwargs) if (fun, key) in cls.func_result_dict and time.time() - cls.func_result_dict[(fun, key)][1] < cache_time: return cls.func_result_dict[(fun, key)][0] else: result = fun(*args, **kwargs) cls.func_result_dict[(fun, key)] = (result, time.time()) cls.logger.debug('函数 [{}] 此次不使用缓存'.format(fun.__name__)) return result return __cached_function_result_for_a_time return _cached_function_result_for_a_time @staticmethod def _make_arguments_to_key(args, kwds): key = args if kwds: sorted_items = sorted(kwds.items()) for item in sorted_items: key += item return key
测试下:
@FunctionResultCacher.cached_function_result_for_a_time(3)
def f10(a, b, c=3, d=4):
print('计算中。。。')
return a + b + c + d
print(f10(1, 2, 3, 4))
print(f10(1, 2, 3, 4))
time.sleep(4)
print(f10(1, 2, 3, 4))
运行结果是这样
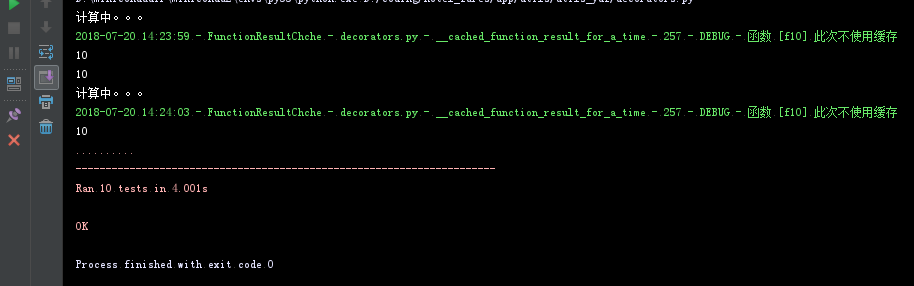
可以发现只计算了两次,第一次是开始时候没有缓存所以要计算,第二次有缓存了就不计算,第三次因为超过了3秒就不使用缓存了,所以要计算。
需要注意一点的是用字典做的缓存,如果函数的结果非常大,部署后一直运行,一段时间后会占一大块内存,所以设置了1024个缓存结果,否则就清除字典。如果函数没有入参或者入参都是一样的那就没事,如果入参不一样且函数返回结果超长是一个几百万长度的字符串,那就用此装饰器时候要小心点。
把if len(cls.func_result_dict) > 1024: 改为if sys.getsizeof(cls.func_result_dict) > 100 * 1000 * 1000,则是直接判断内存。
此装饰器可以装饰在函数上,当然也可以装饰在方法上了。因为 *args **kwargs代表了所有参数,self只是其中的一个特殊参数而已,所以可以装饰在方法上。
functools模块有个lru_cache装饰器,是缓存指定次数的装饰器,这个是缓存指定时间的。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号