python模块和类的通用转换规则(2),三步转oo
介绍模块和类怎么互相转换,不谈面向对象的继承 封装 多态等特点。
一个person_module模块,有人的基本属性和功能。
person_module.py如下
# coding=utf8 name = '小明' eye_color = 'blue' age = 10 def get_eye_color(): return name + '的眼睛颜色是: ' + eye_color def show_age(): print name + '的年龄是: ' + str(age) def grow(): print name + ' 增长一岁了' globals()['age'] += 1 ##这里要注意一定要这样写活着声明age是全局的,否则会出错 print globals()['age'] show_age() if __name__ == "__main__": print get_eye_color() show_age() grow()
现在假如这个模块是别人写的,我们拿来用,现在我们要把名字换成小红,眼睛颜色换成黑色,年龄换成15岁,成长函数,一次增加两岁
那我们就需要修改别人的源码文件了,可能改着改着改错了,不知道怎么复原了。
那就import这个模块吧。
xiaohong.py
# coding=utf8 import person_module as p from person_module import * p.name = '小红' p.age = 14 p.eye_color = 'black' def grow(): print p.name + ' 增长一岁了' p.age += 2 print p.age show_age() p.grow = grow print p.get_eye_color() show_age() p.grow() # 直接grow()也可以

可以看到属性被替换了,连增长函数也被替换了,一次增长两岁。
这就是给模块打猴子补丁了,这样写很别扭的实现了模块继承,类似于类继承。
希望把这个模块转换成类,oop编程。
模块和类的转换规则是:
1、模块级降为类
2、全局变量改成实例属性,全局的不会被改变的变量类似于那种const的,可以写成类属性(减少点内存存储可以)。
3、然后把函数改成方法。方法是类里面的,函数是模块里面的。
看person.py
# coding=utf8 class Person(object): def __init__(self, name, age,eye_color): self.name = name self.eye_color = eye_color self.age = age def get_eye_color(self): return self.name + '的眼睛颜色是: ' + self.eye_color def show_age(self): print self.name + '的年龄是: ' + str(self.age) def grow(self): print self.name + ' 增长一岁了' self.age += 1 self.show_age() if __name__ == "__main__": xiaohong = Person('小红', 14, 'black') print xiaohong.get_eye_color() xiaohong.show_age() xiaohong.grow()
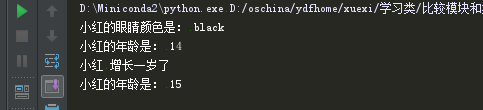
这样做了之后,统一通过self就能访问age name了,改变age也不需要蛋疼的声明一下age是全局的那个了。
就这样三个步骤,就能把面向过程的模块改成面向对象了。
最主要是前面那种导入模块的方法,打补丁很麻烦,那例子还只是实现小红,如果要实现小黄、小花,那就复杂了。如果使用oop,类的多个实例就自然多了,也简单直观。
如果要改变grow方法,继承一下就行了,改成这样
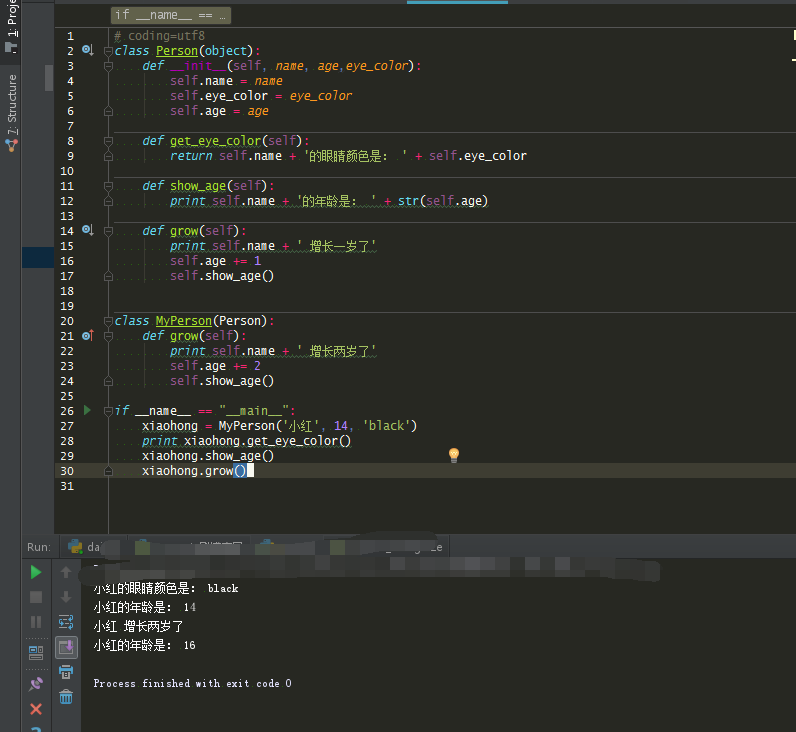
大部分入门都是第一种写法,毕竟py编程太自由了,可以一条条从上往下指令平铺,也可以抽成函数,也可以oop。用py会长期形成了懒惰的写法用前面第一种,但复用性真的比oop差很多,总体看起来也low一些。比如多个过程需要共享中间状态时,单纯的使用函数会写得很糟糕,这时候就应当使用类,否则要么搞全局变量要么频繁的return频繁的传参,为什么反对模块编程,就是因为模块难以初始化赋值,模块的多实例难以搞,类能很好解决。非oop一些设计模式很难用上。也有人坚决说他不需要oop,说不需要那是没认真对比过,或者压根不了解,只是死记硬背类的 继承 封装多态这几个词语,并没有实践对比过。还有的说python里面一切皆是对象,所以他写的就是oop,没错,那样仅限于有int 类 str类 字典类 或者导入了三方库后有了Request类 Response类,selenim的webdriver的Chrome类 Firefox类,仅限于此啊,没有自己的类,python一切皆对象(在py里面随便写个 a = 5,a就可以说是int类的一个实例了,py是面向对象的极致,甚至比java还极致,java里面的int a = 5,a是基本数据类型,要用到一些必要的方法支持还的把a转成Interger类的对象,php里面的字符串操作是由函数完成的,php的小写字符串转大写是 strtoupper("Hello WORLD!"),py的小写转大写是“Hello WORLD!”.uper(),object.func()和func(object)就是op和oo的区别。除了py里面的例如__len__用,len(str1)来获取长度,但这种是通过反射完成,也可以用str.__len__(),len(str)形式上看起来不那么oo。)虽然py一切皆对象,py是最极致的面向对象,但这不代表随便写就是oop编程了。三方库为什么调用的那么爽,那是人家oop了,人家三方库全写函数,调用起来就知道什么叫痛苦了,都不知道应该调用哪些函数来处理那个对象了。这都什么年代了,还对oop持怀疑和反对态度。php py js es6都是在慢慢的后来加入类的概念,难道发明语言的人会比我们差吗。
必须对py的oop非常熟悉,才能开始学习java。不然的是肯定看不懂java。
一个模块内可以多个类,类可以把模块分割裂更小的模块组织单元。oo大量实例化时候需要占用更多的内存,性能是比op差。如果担心oo性能比op差,那一样可以适当地写类里面的静态方法或者类方法,无需实例化,常用的工具方法不要全写成实例方法,干个啥都要实例化,该用静态就要用静态。
这是一些体会,po和oo每次写时候顺便脑补一下,另一种大概是怎么样的。全局变量太多,多个函数操作一个东西,就可以想下oop,oo能消灭全局,平铺式的代码适合简单脚本,或者快速验证和测试或者顶层脚本,但如果是作为被导入模块,再用这种写法,模块里面大量写非final类型的全局变量是很脑残的低级入门写法。模块级的po是拿个源码脚本,到处去修改一些变量的值,例如age name什么的。oo是对数据和方法的封装,op是函数和传参分离在两个地方。
以上为简单例子,oop的进阶是设计模式。
如果不是按照这种写人的方式,全局变量加函数的面向过程写法,而是完全的没有全局变量一步步return和传参的,执行三步走那就是只有class外壳的类,仍然是一个面向过程的类,需要再加一步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号