python打造线程池
# coding=utf-8 import threading import Queue import time import traceback class ThreadPoolExecutor(object): def __init__(self, max_works): self._q = Queue.Queue() self.max_works=max_works self.started=0 def worker(self): while True: (fn, args) = self._q.get() try: fn(*args) except Exception, e: print '线程池执行错误,item是:',item, '错误原因是:',e,traceback.format_exc() finally: pass self._q.task_done() def submit(self, fn, *args): item = (fn,args) self._q.put(item) self.start_work() def start_work(self): if self.started==0: for i in range(self.max_works): t=threading.Thread(target=self.worker) t.setDaemon(True) ###利用daemon的特性:父线程退出时子线程就自动退出。 t.start() self.started=1 def wait_all_finish(self): self._q.join()
测试
#coding=utf8 import threading from xccfb import ThreadPoolExecutor import time if __name__=="__main__": tlock=threading.Lock() def fun(strx): with tlock: print time.strftime('%H:%M:%S'),strx time.sleep(2) threadPoolExecutor=ThreadPoolExecutor(3) for i in range(10): threadPoolExecutor.submit(fun, 'hello') threadPoolExecutor.submit(fun, 'hi') threadPoolExecutor.wait_all_finish() ###注释掉就可以先print over print time.strftime('%H:%M:%S'), 'over'
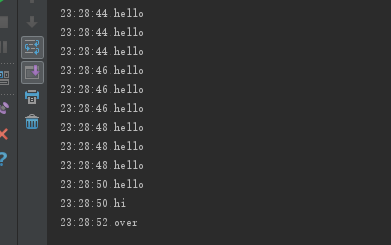
使用wait_all_finish()的queue.join()方法阻塞主线程,当队列中有任务还要执行时候不往下执行。不想阻塞就不要写这句。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号