linux环境下pytesseract的安装和央行征信中心的登录验证码识别
首先是安装,我参考的是这个 http://blog.csdn.net/xinghun_4/article/details/47860645
我是centos,使用yum
yum install python-devel libjpeg libjpeg-devel freetype freetype-devel zlib zlib-devel littlecms littlecms-devel libwebp libwebp-devel libfreetype libfreetype-devel giflib-devel automake libtool
tesseract安装包我下载的是3.0.4,安装的时候提示搭配的leptonica的版本必须是1.7.2以上,所以不能使用1.6.9的leptonica,这点要注意。
上一些央行征信征信的验证码例子,这是截图

可以看到,字迹是相当的工整,但是直接使用image_to_string这个方法几乎是不可能是别的,只有少数图片可以转换输出文字。
需要做点处理,找规律可以发现这些噪点都是一些暗淡的像素点,可以把他们去掉(就是转换成白色的)。
#coding=utf-8
import pytesseract
from PIL import Image
import re
class YzmDiscern():
def __init__(self, threshold):
#self.threshold = threshold
self.table = [0 if _ < threshold else 1 for _ in range(256)]
def pic2text(self,picture_name):
im=Image.open(picture_name+'.jpg')
imgry = im.convert('L')
out = imgry.point(self.table,'1')
out = imgry.point(self.table,'1')
out.save(picture_name+'b.jpg')
# i = Image.open(name+'b.jpg')
# i.show()
text= pytesseract.image_to_string(out)
#print text
text2=re.sub('[^a-z0-9A-Z]','',text)
return text2
if __name__=="__main__":
yzmDiscern=YzmDiscern(threshold=140)
print yzmDiscern.pic2text('pictures/150873460574')

这是pycharmm调用的是远程linux环境的截图,如果要在linxu直接执行./do_yzm.py,那就需要在代码第一行指明解释器路径,然后修改do_yzm.py的权限为可执行的权限.
实际识别率几乎达到了95%,效果还可以。如果错了再换个验证码登录就可以了。
这是原图
threshold这个值要设置合理,设置太大了,那些噪点全部变成黑色了。

设置小了也不行,虽然噪点都去掉了,但会把字母也弄残了。
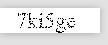
这样就会识别不出来了。
这是设置140的结果
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号