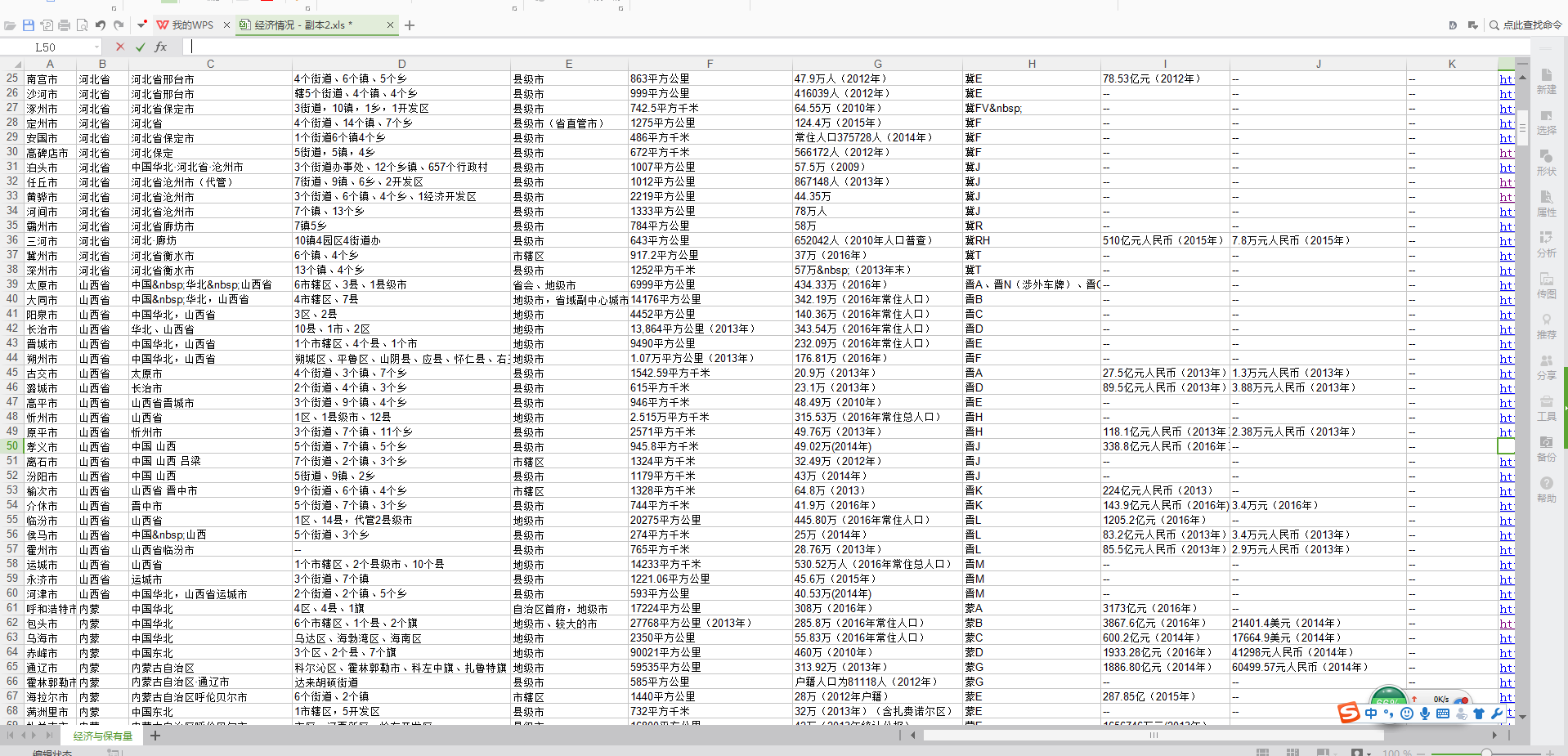
爬取百度百科上中国所有城市的信息
1 # coding=utf-8 2 import xlrd 3 import xlwt 4 import requests 5 import re 6 import json 7 import os 8 import sys 9 reload(sys) 10 sys.setdefaultencoding('utf8') 11 from xlutils.copy import copy 12 13 14 data = xlrd.open_workbook(u'经济情况 - 副本.xlsx') 15 table=data.sheets()[0] 16 nrows = table.nrows 17 ncols = table.ncols 18 print nrows,ncols 19 20 print '--'.join(table.row_values(1)) 21 errortxt=open(u'错误城市.txt','a') 22 23 24 class WriteExcel(object): 25 def __init__(self,filename): 26 self.file=filename 27 def write2excel(self,row, col, strx): 28 rb = xlrd.open_workbook(self.file)#, formatting_info=True) 29 wb = copy(rb) 30 ws = wb.get_sheet(0) 31 ws.write(row, col, unicode(strx)) 32 wb.save(self.file) 33 34 class Crawlcity(WriteExcel): 35 def __init__(self,cityname): 36 super(Crawlcity,self).__init__(u'经济情况 - 副本.xlsx') 37 self.cityname=cityname 38 print '爬取%s的百科信息'%cityname 39 40 def myserch(self,fieldx,content): 41 matchx=re.search('%s</dt>\s*?<dd class="basicInfo-item value">\s*?(.*?)\s*?</dd>'%fieldx, content) 42 if matchx: 43 #print '%s的原始匹配是:%s' % (fieldx,matchx.group(1)) 44 matchx_str=re.sub('<sup.*','',matchx.group(1)) 45 return re.sub('<.*?>|<.*?>','',matchx_str) 46 else: 47 print '###########没找到%s的%s字段的匹配'%(self.cityname,fieldx) 48 return '--' 49 50 def get_baike_city(self,citynamex=None): 51 if not citynamex: 52 url='https://baike.baidu.com/item/%s'%self.cityname 53 else: 54 url='https://baike.baidu.com/item/%s'%citynamex 55 print '%s的百科链接是%s'%(self.cityname,url) 56 resp=requests.get(url) 57 #print resp.content 58 if 'https://baike.baidu.com/item' not in resp.url: 59 print '%s跳转到错误链接%s'%(self.cityname,resp.url) 60 return self.get_baike_city(citynamex=self.cityname.replace('市','')) 61 # errortxt.write('%s %s'%(self.cityname,url)) 62 # return 63 64 65 belong_area = self.myserch('所属地区',resp.content) 66 governs_area = self.myserch('下辖地区',resp.content) 67 region_type = self.myserch('行政区类别',resp.content) 68 area = self.myserch('面 积',resp.content) 69 population = self.myserch('人 口',resp.content) 70 plata_code = self.myserch('车牌代码',resp.content) 71 gdp = self.myserch('地区生产总值',resp.content) 72 avarage_gdp = self.myserch('人均生产总值',resp.content) 73 per_capita_income = self.myserch('人均支配收入',resp.content) 74 75 print '%s\n的所属地区是:%s\n下辖地区是:%s\n行政区类别是:%s\n面积是:%s\n人口是:%s\n车牌代码是:%s\n地区生产总值是:%s\n人均生产总值是:%s\n人均支配收入是:%s\n'%(self.cityname,belong_area,governs_area, 76 region_type,area,population,plata_code,gdp,avarage_gdp,per_capita_income) 77 print '*'*100 78 79 for n in range(1,nrows): 80 if self.cityname==table.row_values(n)[0]: 81 self.write2excel(n,2,belong_area) 82 self.write2excel(n, 3, governs_area) 83 self.write2excel(n, 4, region_type) 84 self.write2excel(n, 5, area) 85 self.write2excel(n, 6, population) 86 self.write2excel(n, 7, plata_code) 87 self.write2excel(n, 8, gdp) 88 self.write2excel(n, 9, avarage_gdp) 89 self.write2excel(n, 10, per_capita_income) 90 self.write2excel(n, 11, url) 91 break 92 93 94 if __name__=="__main__": 95 for n in range(1,nrows): 96 cityname = table.row_values(n)[0] 97 if table.row_values(n)[2]!='': 98 pass 99 print 'excel已记录了,跳过%s这个城市城市'%cityname 100 else: 101 Crawlcity(cityname).get_baike_city()
百度百科的规律是https://baike.baidu.com/item/xxxx
例如要爬取黄冈市的信息,就用https://baike.baidu.com/item/黄冈市,然后请求会自动重定向到该词条。注意结尾不要加一个/,否则会是一个错误的页面。
从excel读取要爬的城市,然后爬取城市信息,把数据插入到excel中。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号