爬中国联通
#coding=utf8 import requests class ChinaUnicom(object): headerx={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} login_url='https://uac.10010.com/portal/Service/MallLogin' info_url='https://uac.10010.com/cust/infomgr/anonymousInfoAJAX' def __init__(self,phone,server_passwd): self.ss=requests.session() self.phone=phone self.server_passwd=server_passwd def login(self): datax={ 'callback':'jQuery17208315958887266249_1502520335284', 'req_time':'1502520347528', 'redirectURL':'http://www.10010.com', 'userName':self.phone, 'password':self.server_passwd, 'pwdType':'01', 'productType':'01', 'redirectType':01, 'rememberMe':1, '_':'1502520347531', } self.ss.get(self.login_url,params=datax,headers=self.headerx) ##可以不要真实浏览器ua def get_infomgrInit(self): '''获取个人信息''' resp=self.ss.post(self.info_url) return resp.content if __name__=="__main__": cu=ChinaUnicom(1314880xxxx,37xxxx) cu.login() print cu.get_infomgrInit()
先登录再爬取。
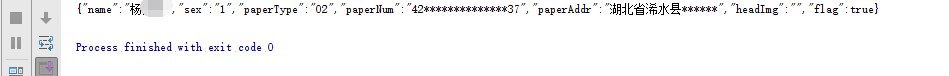
关于时间戳,就我见过的淘宝 联通 房天下和一些杂七杂八的网站来看,时间戳基本是不造成任何影响,请求参数中直接用一个固定的时间戳也没关系,如果你喜欢你也可以用time.time()来获得时间戳。
20170921:登录现在的header里面要加入refer,否则返回9974.
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号