使用scrapy_redis,实时增量更新东方头条网全站新闻
存储使用mysql,增量更新东方头条全站新闻的标题 新闻简介 发布时间 新闻的每一页的内容 以及新闻内的所有图片。东方头条网没有反爬虫,新闻除了首页,其余板块的都是请求一个js。抓包就可以看到。
项目文件结构。
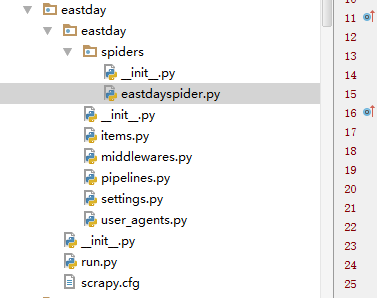
这是settings.py


1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for eastday project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # http://doc.scrapy.org/en/latest/topics/settings.html 9 # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 10 # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'eastday' 13 14 SPIDER_MODULES = ['eastday.spiders'] 15 NEWSPIDER_MODULE = 'eastday.spiders' 16 17 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" 18 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 19 REDIS_START_URLS_AS_SET=True #shezhi strat_urls键是集合,默认是false是列表 20 SCHEDULER_PERSIST = True 21 22 DEPTH_PRIORITY=0 23 RETRY_TIMES = 20 24 25 IMAGES_STORE = 'd:/' 26 IMAGES_EXPIRES = 90 27 28 REDIS_HOST = 'localhost' 29 REDIS_PORT = 6379 30 # Crawl responsibly by identifying yourself (and your website) on the user-agent 31 #USER_AGENT = 'eastday (+http://www.yourdomain.com)' 32 33 # Obey robots.txt rules 34 ROBOTSTXT_OBEY = False 35 36 # Configure maximum concurrent requests performed by Scrapy (default: 16) 37 CONCURRENT_REQUESTS = 10 38 39 # Configure a delay for requests for the same website (default: 0) 40 # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay 41 # See also autothrottle settings and docs 42 DOWNLOAD_DELAY = 0 43 # The download delay setting will honor only one of: 44 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 45 #CONCURRENT_REQUESTS_PER_IP = 16 46 47 # Disable cookies (enabled by default) 48 #COOKIES_ENABLED = False 49 50 # Disable Telnet Console (enabled by default) 51 #TELNETCONSOLE_ENABLED = False 52 53 # Override the default request headers: 54 #DEFAULT_REQUEST_HEADERS = { 55 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 56 # 'Accept-Language': 'en', 57 #} 58 59 # Enable or disable spider middlewares 60 # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html 61 #SPIDER_MIDDLEWARES = { 62 # 'eastday.middlewares.EastdaySpiderMiddleware': 543, 63 #} 64 65 # Enable or disable downloader middlewares 66 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html 67 68 DOWNLOADER_MIDDLEWARES = { 69 "eastday.middlewares.UserAgentMiddleware": 401, 70 #"eastday.middlewares.CookiesMiddleware": 402, 71 } 72 73 74 75 # Enable or disable extensions 76 # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html 77 #EXTENSIONS = { 78 # 'scrapy.extensions.telnet.TelnetConsole': None, 79 #} 80 81 # Configure item pipelines 82 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html 83 ITEM_PIPELINES = { 84 #'eastday.pipelines.EastdayPipeline': 300, 85 'eastday.pipelines.MysqlDBPipeline':400, 86 'eastday.pipelines.DownloadImagesPipeline':200, 87 #'scrapy_redis.pipelines.RedisPipeline': 400, 88 89 } 90 91 # Enable and configure the AutoThrottle extension (disabled by default) 92 # See http://doc.scrapy.org/en/latest/topics/autothrottle.html 93 #AUTOTHROTTLE_ENABLED = True 94 # The initial download delay 95 #AUTOTHROTTLE_START_DELAY = 5 96 # The maximum download delay to be set in case of high latencies 97 #AUTOTHROTTLE_MAX_DELAY = 60 98 # The average number of requests Scrapy should be sending in parallel to 99 # each remote server 100 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 101 # Enable showing throttling stats for every response received: 102 #AUTOTHROTTLE_DEBUG = False 103 104 # Enable and configure HTTP caching (disabled by default) 105 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 106 #HTTPCACHE_ENABLED = True 107 #HTTPCACHE_EXPIRATION_SECS = 0 108 #HTTPCACHE_DIR = 'httpcache' 109 #HTTPCACHE_IGNORE_HTTP_CODES = [] 110 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
这是items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # http://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class EastdayItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 title=scrapy.Field() 15 url=scrapy.Field() 16 tag=scrapy.Field() 17 article=scrapy.Field() 18 img_urls=scrapy.Field() 19 crawled_time=scrapy.Field() 20 pubdate=scrapy.Field() 21 origin=scrapy.Field() 22 23 24 brief = scrapy.Field() 25 miniimg = scrapy.Field() 26 27 28 pass 29 30 ''' 31 class GuoneiItem(scrapy.Item): 32 # define the fields for your item here like: 33 # name = scrapy.Field() 34 title=scrapy.Field() 35 url=scrapy.Field() 36 tag=scrapy.Field() 37 article=scrapy.Field() 38 img_urls=scrapy.Field() 39 crawled_time=scrapy.Field() 40 41 brief=scrapy.Field() 42 miniimg=scrapy.Field() 43 44 45 pass 46 '''
文件太多啦,不一一贴了,源码文件已打包已上传到博客园,但没找到分享文件链接的地方,如果要源码的可以评论中留言。
这是mysql的存储结果:

东方头条内容也是采集其他网站报刊的,内容还是很丰富,把东方头条的爬下来快可以做一个咨询内容的app了。
文章图片采用的是新闻中图片的连接的源文件名,方便前端开发在页面中展现正确的图片。用来做针对用户的数据挖掘的精准兴趣推荐。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号