开发一个python万能分布式消费框架(基于mq redis中间件的函数调度框架)。只需要一行代码就 将任何函数实现 分布式 、并发、 控频、断点接续运行、定时、指定时间不运行、消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。大大简化比使用celery,很强大简单,已在多个生产项目和模块验证。
更新 python万能消费框架,新增7种中间件(或操作mq的包)和三种并发模式。
框架目的是分布式调度起一切任何函数(当然也包括调度起一切任何方法)。
之前写的是基于rabbitmq的,作为专用的消息队列好处比redis的list结构好很多。但有的人还是强烈喜欢用redis,以及rabbitmq安装比redis麻烦点。
现在加入reids作为中间件的方式。(支持仅仅修改一个字母就达到全局切换使用何种中间件,其余代码不需要做任何一处修改就可以 正常运行)
使用 模板模式 加工厂模式 加策略模式(消费者调用的函数,用户自己写的每一个被消费的函数单元都是策略函数)
解释下为什么不直接用celery呢?
1、写法过于麻烦了,运行方式也麻烦一些。
2、对文件的位置要求高一点,可以设置main来解决。但还是没太方便。这个可以把消费代码随意移动文件到任何层级的文件夹或者移到任何地方。
3、配置项高达200个,复杂,英文文档2000页,我是看了5遍,太复杂了公司推广很麻烦,不是每个人都喜欢反复几千页看好几次。
这是之前的,运行方式很古怪,不喜欢命令行方式,ide不能补全爱出错。
celery_main = 'app.apis.list_page_live_price.live_price_celery_app'
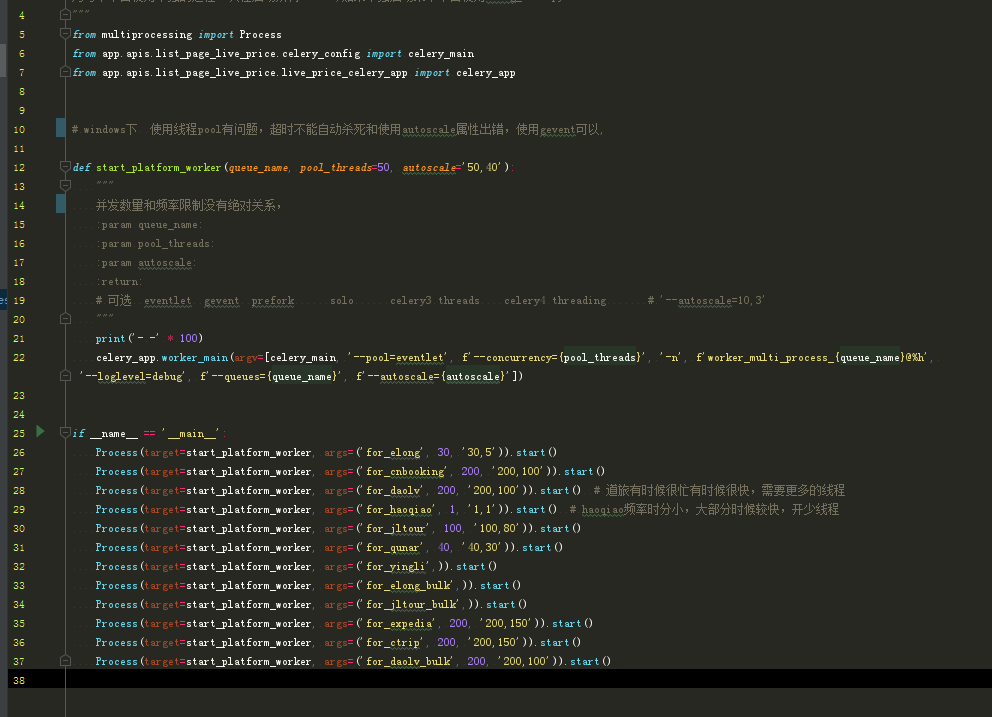
# -*- coding: utf-8 -*- # @Author : ydf """ 类celery的worker模式,可用于一切需要分布式并发的地方,最好是io类型的。可以分布式调度起一切函数。 rabbitmq生产者和消费者框架。完全实现了celery worker模式的全部功能,使用更简单。支持自动重试指定次数,消费确认,指定数量的并发线程,和指定频率控制1秒钟只运行几次, 同时对mongodb类型的异常做了特殊处理 最开始写得是使用pika包,非线程安全,后来加入rabbitpy,rabbitpy包推送会丢失部分数据,推荐pika包使用 单下划线代表保护,双下划线代表私有。只要关注公有方法就可以,其余是类内部自调用方法。 3月15日 1)、新增RedisConsumer 是基于redis中间件的消费框架,不支持随意暂停程序或者断点,会丢失一部分正在运行中的任务,推荐使用rabbitmq的方式。 get_consumer是使用工厂模式来生成基于rabbit和reids的消费者,使用不同中间件的消费框架更灵活一点点,只需要修改一个数字。 3月20日 2)、增加支持函数参数过滤的功能,可以随时放心多次推送相同的任务到中间件,会先检查该任务是否需要执行,避免浪费cpu和流量,加快处理速度。 基于函数参数值的过滤,需要设置 do_task_filtering 参数为True才生效,默认为False。 3)、新增支持了函数的参数是多个参数,需要设置is_consuming_function_use_multi_params 为True生效,为了兼容老代码默认为False。 区别是消费函数原来需要 def f(body): # 函数有且只能有一个参数,是字典的多个键值对来表示参数的值。 print(body['a']) print(body['b']) 现在可以 def f(a,b): print(a) print(b) 对于推送的部分,都是一样的,都是推送 {"a":1,"b":2} 6月3日 1) 增加了RedisPublisher类,和增加get_publisher工厂模式 方法同mqpublisher一样,这是为了增强一致性,以后每个业务的推送和消费,如果不直接使用RedisPublisher RedisConsumerer RabbitmqPublisher RabbitMQConsumer这些类,而是使用get_publisher和get_consumer来获取发布和消费对象,支持修改一个全局变量的broker_kind数字来切换所有平台消费和推送的中间件种类。 2)增加指定不运行的时间的配置。例如可以白天不运行,只在晚上运行。 3)增加了函数超时的配置,当函数运行时间超过n秒后,自动杀死函数,抛出异常。 4) 增加每分钟函数运行次数统计,和按照最近一分钟运行函数次数来预估多久可以运行完成当前队列剩余的任务。 5) 增加一个判断函数,阻塞判断连续多少分钟队列里面是空的。判断任务疑似完成。 6)增加一个终止消费者的标志,设置标志后终止循环调度消息。 7) consumer对象增加内置一个属性,表示相同队列名的publisher实例。 """ # import functools import abc import copy import traceback import typing import json from collections import Callable, OrderedDict import time from concurrent.futures import ThreadPoolExecutor from functools import wraps from threading import Lock, Thread import unittest import rabbitpy from pika import BasicProperties # noinspection PyUnresolvedReferences from pika.exceptions import ChannelClosed, AMQPError # from rabbitpy.message import Properties import pika from pika.adapters.blocking_connection import BlockingChannel from pymongo.errors import PyMongoError from app.utils_ydf import (LogManager, LoggerMixin, RedisMixin, BoundedThreadPoolExecutor, RedisBulkWriteHelper, RedisOperation, decorators, time_util, LoggerLevelSetterMixin, nb_print) from app import config as app_config # LogManager('pika').get_logger_and_add_handlers(10) # LogManager('pika.heartbeat').get_logger_and_add_handlers(10) # LogManager('rabbitpy').get_logger_and_add_handlers(10) # LogManager('rabbitpy.base').get_logger_and_add_handlers(10) def delete_keys_from_dict(dictx: dict, keys: list): for dict_key in keys: dictx.pop(dict_key) class ExceptionForRetry(Exception): """为了重试的,抛出错误。只是定义了一个子类,用不用都可以""" class ExceptionForRequeue(Exception): """框架检测到此错误,重新放回队列中""" class ExceptionForRabbitmqRequeue(ExceptionForRequeue): # 以后去掉这个异常,抛出上面那个异常就可以了。 """遇到此错误,重新放回队列中""" class RabbitmqClientRabbitPy: """ 使用rabbitpy包。 """ # noinspection PyUnusedLocal def __init__(self, username, password, host, port, virtual_host, heartbeat=0): rabbit_url = f'amqp://{username}:{password}@{host}:{port}/{virtual_host}?heartbeat={heartbeat}' self.connection = rabbitpy.Connection(rabbit_url) def creat_a_channel(self) -> rabbitpy.AMQP: return rabbitpy.AMQP(self.connection.channel()) # 使用适配器,使rabbitpy包的公有方法几乎接近pika包的channel的方法。 class RabbitmqClientPika: """ 使用pika包,多线程不安全的包。 """ def __init__(self, username, password, host, port, virtual_host, heartbeat=0): """ parameters = pika.URLParameters('amqp://guest:guest@localhost:5672/%2F') connection = pika.SelectConnection(parameters=parameters, on_open_callback=on_open) :param username: :param password: :param host: :param port: :param virtual_host: :param heartbeat: """ credentials = pika.PlainCredentials(username, password) self.connection = pika.BlockingConnection(pika.ConnectionParameters( host, port, virtual_host, credentials, heartbeat=heartbeat)) def creat_a_channel(self) -> BlockingChannel: return self.connection.channel() class RabbitMqFactory: def __init__(self, username=app_config.RABBITMQ_USER, password=app_config.RABBITMQ_PASS, host=app_config.RABBITMQ_HOST, port=app_config.RABBITMQ_PORT, virtual_host=app_config.RABBITMQ_VIRTUAL_HOST, heartbeat=60 * 10, is_use_rabbitpy=0): """ :param username: :param password: :param port: :param virtual_host: :param heartbeat: :param is_use_rabbitpy: 为0使用pika,多线程不安全。为1使用rabbitpy,多线程安全的包。 """ if is_use_rabbitpy: self.rabbit_client = RabbitmqClientRabbitPy(username, password, host, port, virtual_host, heartbeat) else: self.rabbit_client = RabbitmqClientPika(username, password, host, port, virtual_host, heartbeat) def get_rabbit_cleint(self): return self.rabbit_client class AbstractPublisher(LoggerLevelSetterMixin, metaclass=abc.ABCMeta, ): def __init__(self, queue_name, log_level_int=10, logger_prefix='', is_add_file_handler=True, clear_queue_within_init=False): """ :param queue_name: :param log_level_int: :param logger_prefix: :param is_add_file_handler: :param clear_queue_within_init: """ self._queue_name = queue_name if logger_prefix != '': logger_prefix += '--' logger_name = f'{logger_prefix}{self.__class__.__name__}--{queue_name}' self.logger = LogManager(logger_name).get_logger_and_add_handlers(log_level_int, log_filename=f'{logger_name}.log' if is_add_file_handler else None) # # self.rabbit_client = RabbitMqFactory(is_use_rabbitpy=is_use_rabbitpy).get_rabbit_cleint() # self.channel = self.rabbit_client.creat_a_channel() # self.queue = self.channel.queue_declare(queue=queue_name, durable=True) self._lock_for_pika = Lock() self._lock_for_count = Lock() self._current_time = None self.count_per_minute = None self._init_count() self.init_broker() self.logger.info(f'{self.__class__} 被实例化了') self.publish_msg_num_total = 0 if clear_queue_within_init: self.clear() def _init_count(self): with self._lock_for_count: self._current_time = time.time() self.count_per_minute = 0 @abc.abstractmethod def init_broker(self): pass def publish(self, msg: typing.Union[str, dict]): if isinstance(msg, dict): msg = json.dumps(msg) t_start = time.time() decorators.handle_exception(retry_times=10, is_throw_error=True, time_sleep=0.1)(self.concrete_realization_of_publish)(msg) self.logger.debug(f'向{self._queue_name} 队列,推送消息 耗时{round(time.time() - t_start, 5)}秒 {msg}') with self._lock_for_count: self.count_per_minute += 1 self.publish_msg_num_total += 1 if time.time() - self._current_time > 10: self.logger.info(f'10秒内推送了 {self.count_per_minute} 条消息,累计推送了 {self.publish_msg_num_total} 条消息到 {self._queue_name} 中') self._init_count() @abc.abstractmethod def concrete_realization_of_publish(self, msg): raise NotImplementedError @abc.abstractmethod def clear(self): raise NotImplementedError @abc.abstractmethod def get_message_count(self): raise NotImplementedError @abc.abstractmethod def close(self): raise NotImplementedError def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): self.close() self.logger.warning(f'with中自动关闭publisher连接,累计推送了 {self.publish_msg_num_total} 条消息 ') def deco_mq_conn_error(f): def _inner(self, *args, **kwargs): try: return f(self, *args, **kwargs) except AMQPError as e: self.logger.error(f'rabbitmq链接出错 ,方法 {f.__name__} 出错 ,{e}') self.init_broker() return f(self, *args, **kwargs) return _inner class RabbitmqPublisher(AbstractPublisher): """ 使用pika实现的。 """ # noinspection PyAttributeOutsideInit def init_broker(self): self.logger.warning(f'使用pika 链接mq') self.rabbit_client = RabbitMqFactory(is_use_rabbitpy=0).get_rabbit_cleint() self.channel = self.rabbit_client.creat_a_channel() self.queue = self.channel.queue_declare(queue=self._queue_name, durable=True) # noinspection PyAttributeOutsideInit @deco_mq_conn_error def concrete_realization_of_publish(self, msg): with self._lock_for_pika: # 亲测pika多线程publish会出错。 # if self.channel.connection.is_closed or self.channel.is_closed: # 有时候断了。 # self.logger.critical('发布消息,pika链接断了 “self.channel.connection.is_closed or self.channel.is_closed ”') # self.rabbit_client = RabbitMqFactory(is_use_rabbitpy=0).get_rabbit_cleint() # self.channel = self.rabbit_client.creat_a_channel() # self.queue = self.channel.queue_declare(queue=self._queue_name, durable=True) # import random # if random.randint(0, 3) != 1: # raise AMQPError self.channel.basic_publish(exchange='', routing_key=self._queue_name, body=msg, properties=BasicProperties( delivery_mode=2, # make message persistent 2(1是非持久化) ) ) @deco_mq_conn_error def clear(self): self.channel.queue_purge(self._queue_name) self.logger.warning(f'清除 {self._queue_name} 队列中的消息成功') @deco_mq_conn_error def get_message_count(self): queue = self.channel.queue_declare(queue=self._queue_name, durable=True) return queue.method.message_count # @deco_mq_conn_error def close(self): self.channel.close() self.rabbit_client.connection.close() self.logger.warning('关闭pika包 链接') class RabbitmqPublisherUsingRabbitpy(AbstractPublisher): """ 使用rabbitpy包实现的。 """ # noinspection PyAttributeOutsideInit def init_broker(self): self.logger.warning(f'使用rabbitpy包 链接mq') self.rabbit_client = RabbitMqFactory(is_use_rabbitpy=1).get_rabbit_cleint() self.channel = self.rabbit_client.creat_a_channel() self.queue = self.channel.queue_declare(queue=self._queue_name, durable=True) @deco_mq_conn_error def concrete_realization_of_publish(self, msg): # noinspection PyTypeChecker self.channel.basic_publish( exchange='', routing_key=self._queue_name, body=msg, properties={'delivery_mode': 2}, ) @deco_mq_conn_error def clear(self): self.channel.queue_purge(self._queue_name) self.logger.warning(f'清除 {self._queue_name} 队列中的消息成功') @deco_mq_conn_error def get_message_count(self): # noinspection PyUnresolvedReferences ch_raw_rabbity = self.channel.channel return rabbitpy.amqp_queue.Queue(ch_raw_rabbity, self._queue_name, durable=True) # @deco_mq_conn_error def close(self): self.channel.close() self.rabbit_client.connection.close() self.logger.warning('关闭rabbitpy包 链接mq') class RedisPublisher(AbstractPublisher, RedisMixin): """ 使用redis作为中间件 """ def init_broker(self): pass def concrete_realization_of_publish(self, msg): # noinspection PyTypeChecker self.redis_db7.rpush(self._queue_name, msg) def clear(self): self.redis_db7.delete(self._queue_name) self.logger.warning(f'清除 {self._queue_name} 队列中的消息成功') def get_message_count(self): return self.redis_db7.llen(self._queue_name) def close(self): # self.redis_db7.connection_pool.disconnect() pass class RedisFilter(RedisMixin): def __init__(self, redis_key_name): self._redis_key_name = redis_key_name @staticmethod def _get_ordered_str(value): """对json的键值对在redis中进行过滤,需要先把键值对排序,否则过滤会不准确如 {"a":1,"b":2} 和 {"b":2,"a":1}""" if isinstance(value, str): value = json.loads(value) ordered_dict = OrderedDict() for k in sorted(value): ordered_dict[k] = value[k] return json.dumps(ordered_dict) def add_a_value(self, value: typing.Union[str, dict]): self.redis_db7.sadd(self._redis_key_name, self._get_ordered_str(value)) def check_value_exists(self, value): return self.redis_db7.sismember(self._redis_key_name, self._get_ordered_str(value)) class AbstractConsumer(LoggerLevelSetterMixin, metaclass=abc.ABCMeta, ): shedual_task_thread_for_join_on_linux_multiprocessing = list() time_interval_for_check_do_not_run_time = 60 BROKER_KIND = None @property @decorators.synchronized def publisher_of_same_queue(self): if not self._publisher_of_same_queue: self._publisher_of_same_queue = get_publisher(self._queue_name, broker_kind=self.BROKER_KIND) return self._publisher_of_same_queue @classmethod def join_shedual_task_thread(cls): """ :return: """ """ def ff(): RabbitmqConsumer('queue_test', consuming_function=f3, threads_num=20, msg_schedule_time_intercal=2, log_level=10, logger_prefix='yy平台消费', is_consuming_function_use_multi_params=True).start_consuming_message() RabbitmqConsumer('queue_test2', consuming_function=f4, threads_num=20, msg_schedule_time_intercal=4, log_level=10, logger_prefix='zz平台消费', is_consuming_function_use_multi_params=True).start_consuming_message() AbstractConsumer.join_shedual_task_thread() # 如果开多进程启动消费者,在linux上需要这样写下这一行。 if __name__ == '__main__': [Process(target=ff).start() for _ in range(4)] """ for t in cls.shedual_task_thread_for_join_on_linux_multiprocessing: t.join() def __init__(self, queue_name, *, consuming_function: Callable = None, function_timeout=0, threads_num=50, specify_threadpool: ThreadPoolExecutor = None, max_retry_times=3, log_level=10, is_print_detail_exception=True, msg_schedule_time_intercal=0.0, logger_prefix='', create_logger_file=True, do_task_filtering=False, is_consuming_function_use_multi_params=True, is_do_not_run_by_specify_time_effect=False, do_not_run_by_specify_time=('10:00:00', '22:00:00'), schedule_tasks_on_main_thread=False): """ :param queue_name: :param consuming_function: 处理消息的函数。 :param function_timeout : 超时秒数,函数运行超过这个时间,则自动杀死函数。为0是不限制。 :param threads_num: :param specify_threadpool:使用指定的线程池,可以多个消费者共使用一个线程池,不为None时候。threads_num失效 :param max_retry_times: :param log_level: :param is_print_detail_exception: :param msg_schedule_time_intercal:消息调度的时间间隔,用于控频 :param logger_prefix: 日志前缀,可使不同的消费者生成不同的日志 :param create_logger_file : 是否创建文件日志 :param do_task_filtering :是否执行基于函数参数的任务过滤 :is_consuming_function_use_multi_params 函数的参数是否是传统的多参数,不为单个body字典表示多个参数。 :param is_do_not_run_by_specify_time_effect :是否使不运行的时间段生效 :param do_not_run_by_specify_time :不运行的时间段 :param schedule_tasks_on_main_thread :直接在主线程调度任务,意味着不能直接在当前主线程同时开启两个消费者。 """ self._queue_name = queue_name self.consuming_function = consuming_function self._function_timeout = function_timeout self._threads_num = threads_num self.threadpool = specify_threadpool if specify_threadpool else BoundedThreadPoolExecutor(threads_num + 1) # 单独加一个检测消息数量和心跳的线程 self._max_retry_times = max_retry_times self._is_print_detail_exception = is_print_detail_exception self._msg_schedule_time_intercal = msg_schedule_time_intercal self._logger_prefix = logger_prefix self._log_level = log_level if logger_prefix != '': logger_prefix += '--' logger_name = f'{logger_prefix}{self.__class__.__name__}--{queue_name}' self.logger = LogManager(logger_name).get_logger_and_add_handlers(log_level, log_filename=f'{logger_name}.log' if create_logger_file else None) self.logger.info(f'{self.__class__} 被实例化') self._do_task_filtering = do_task_filtering self._redis_filter_key_name = f'filter:{queue_name}' self._redis_filter = RedisFilter(self._redis_filter_key_name) self._is_consuming_function_use_multi_params = is_consuming_function_use_multi_params self._lock_for_pika = Lock() self._execute_task_times_every_minute = 0 # 每分钟执行了多少次任务。 self._lock_for_count_execute_task_times_every_minute = Lock() self._current_time_for_execute_task_times_every_minute = time.time() self._msg_num_in_broker = 0 self._last_timestamp_when_has_task_in_queue = 0 self._last_timestamp_print_msg_num = 0 self._is_do_not_run_by_specify_time_effect = is_do_not_run_by_specify_time_effect self._do_not_run_by_specify_time = do_not_run_by_specify_time # 可以设置在指定的时间段不运行。 self._schedule_tasks_on_main_thread = schedule_tasks_on_main_thread self.stop_flag = False self._publisher_of_same_queue = None def keep_circulating(self, time_sleep=0.001, exit_if_function_run_sucsess=False, is_display_detail_exception=True): """间隔一段时间,一直循环运行某个方法的装饰器 :param time_sleep :循环的间隔时间 :param is_display_detail_exception :param exit_if_function_run_sucsess :如果成功了就退出循环 """ def _keep_circulating(func): # noinspection PyBroadException @wraps(func) def __keep_circulating(*args, **kwargs): while 1: if self.stop_flag: break try: result = func(*args, **kwargs) if exit_if_function_run_sucsess: return result except Exception as e: msg = func.__name__ + ' 运行出错\n ' + traceback.format_exc(limit=10) if is_display_detail_exception else str(e) self.logger.error(msg) finally: time.sleep(time_sleep) return __keep_circulating return _keep_circulating def start_consuming_message(self): # self.threadpool.submit(decorators.keep_circulating(20)(self.check_heartbeat_and_message_count)) self.threadpool.submit(self.keep_circulating(20)(self.check_heartbeat_and_message_count)) if self._schedule_tasks_on_main_thread: # decorators.keep_circulating(1)(self._shedual_task)() self.keep_circulating(1)(self._shedual_task)() else: # t = Thread(target=decorators.keep_circulating(1)(self._shedual_task)) t = Thread(target=self.keep_circulating(1)(self._shedual_task)) self.__class__.shedual_task_thread_for_join_on_linux_multiprocessing.append(t) t.start() @abc.abstractmethod def _shedual_task(self): raise NotImplementedError def _run_consuming_function_with_confirm_and_retry(self, kw: dict, current_retry_times=0): if self._do_task_filtering and self._redis_filter.check_value_exists(kw['body']): # 对函数的参数进行检查,过滤已经执行过并且成功的任务。 self.logger.info(f'redis的 [{self._redis_filter_key_name}] 键 中 过滤任务 {kw["body"]}') self._confirm_consume(kw) return with self._lock_for_count_execute_task_times_every_minute: self._execute_task_times_every_minute += 1 if time.time() - self._current_time_for_execute_task_times_every_minute > 60: self.logger.info( f'一分钟内执行了 {self._execute_task_times_every_minute} 次函数 [ {self.consuming_function.__name__} ] ,预计' f'还需要 {time_util.seconds_to_hour_minute_second(self._msg_num_in_broker / self._execute_task_times_every_minute * 60)} 时间' f'才能执行完成 {self._msg_num_in_broker}个剩余的任务 ') self._current_time_for_execute_task_times_every_minute = time.time() self._execute_task_times_every_minute = 0 if current_retry_times < self._max_retry_times + 1: # noinspection PyBroadException t_start = time.time() try: function_run = self.consuming_function if self._function_timeout == 0 else decorators.timeout(self._function_timeout)(self.consuming_function) if self._is_consuming_function_use_multi_params: # 消费函数使用传统的多参数形式 function_run(**kw['body']) else: function_run(kw['body']) # 消费函数使用单个参数,参数自身是一个字典,由键值对表示各个参数。 self._confirm_consume(kw) if self._do_task_filtering: self._redis_filter.add_a_value(kw['body']) # 函数执行成功后,添加函数的参数排序后的键值对字符串到set中。 self.logger.debug(f'函数 {self.consuming_function.__name__} 第{current_retry_times + 1}次 运行, 正确了,函数运行时间是 {round(time.time() - t_start, 2)} 秒,入参是 【 {kw["body"]} 】') except Exception as e: if isinstance(e, (PyMongoError, ExceptionForRequeue)): # mongo经常维护备份时候插入不了或挂了,或者自己主动抛出一个ExceptionForRequeue类型的错误会重新入队,不受指定重试次数逇约束。 self.logger.critical(f'函数 [{self.consuming_function.__name__}] 中发生错误 {type(e)} {e}') return self._requeue(kw) self.logger.error(f'函数 {self.consuming_function.__name__} 第{current_retry_times + 1}次发生错误,函数运行时间是 {round(time.time() - t_start, 2)} 秒,\n 入参是 【 {kw["body"]} 】 \n 原因是 {type(e)} ', exc_info=self._is_print_detail_exception) self._run_consuming_function_with_confirm_and_retry(kw, current_retry_times + 1) else: self.logger.critical(f'函数 {self.consuming_function.__name__} 达到最大重试次数 {self._max_retry_times} 后,仍然失败, 入参是 【 {kw["body"]} 】') # 错得超过指定的次数了,就确认消费了。 self._confirm_consume(kw) @abc.abstractmethod def _confirm_consume(self, kw): """确认消费""" raise NotImplementedError # noinspection PyUnusedLocal def check_heartbeat_and_message_count(self): self._msg_num_in_broker = self.publisher_of_same_queue.get_message_count() if time.time() - self._last_timestamp_print_msg_num > 60: self.logger.info(f'[{self._queue_name}] 队列中还有 [{self._msg_num_in_broker}] 个任务') self._last_timestamp_print_msg_num = time.time() if self._msg_num_in_broker != 0: self._last_timestamp_when_has_task_in_queue = time.time() return self._msg_num_in_broker @abc.abstractmethod def _requeue(self, kw): """重新入队""" raise NotImplementedError def _submit_task(self, kw): if self._judge_is_daylight(): self._requeue(kw) time.sleep(self.time_interval_for_check_do_not_run_time) return self.threadpool.submit(self._run_consuming_function_with_confirm_and_retry, kw) def _judge_is_daylight(self): if self._is_do_not_run_by_specify_time_effect and self._do_not_run_by_specify_time[0] < time_util.DatetimeConverter().time_str < self._do_not_run_by_specify_time[1]: self.logger.warning(f'现在时间是 {time_util.DatetimeConverter()} ,现在时间是在 {self._do_not_run_by_specify_time} 之间,不运行') return True def wait_for_possible_has_finish_all_tasks(self, minutes: int, mannu_call_check_heartbeat_and_message_count=False, stop_flag=0): """ 由于是异步消费,和存在队列一边被消费,一边在推送,或者还有结尾少量任务还在确认消费者实际还没彻底运行完成。 但有时候需要判断 所有任务,务是否完成,提供一个不精确的判断,要搞清楚原因和场景后再慎用。 :param minutes 连续多少分钟没任务就判断为消费已完成 :param mannu_call_check_heartbeat_and_message_count 如果消费者没有执行startconsuming,需要手动调用这个方法 :param stop_flag 设置停止标志。停止当前实例无限循环调度消息。 :return: """ if minutes <= 1: raise ValueError('疑似完成任务,判断时间最少需要设置为2分钟内,每隔20秒检测一次都是0个任务,') if mannu_call_check_heartbeat_and_message_count: self.threadpool = BoundedThreadPoolExecutor(2) self.threadpool.submit(self.keep_circulating(20)(self.check_heartbeat_and_message_count)) while True: if minutes * 60 < time.time() - self._last_timestamp_when_has_task_in_queue < 3650 * 24 * 60 * 60: # 初次时间戳是0,确保不是无限大。 # print(self._last_timestamp_print_msg_num) self.logger.warning(f'最后一次有任务的时间是{time_util.DatetimeConverter(self._last_timestamp_when_has_task_in_queue)},已经有 {minutes} 分钟没有任务了,疑似完成。') self.stop_flag = stop_flag if self.stop_flag: self.logger.warning('当前实例退出循环调度消息') break else: time.sleep(30) """ continuou_no_task_times = 0 check_interval_time = 10 while True: try: msg_num_in_broker = self.check_heartbeat_and_message_count() except Exception: msg_num_in_broker = 9999 if msg_num_in_broker == 0: continuou_no_task_times += 1 else: continuou_no_task_times = 0 if continuou_no_task_times >= minutes * (60//check_interval_time): break time.sleep(check_interval_time) """ class RabbitmqConsumer(AbstractConsumer): """ 使用pika包实现的。 """ BROKER_KIND = 0 def _shedual_task_old(self): channel = RabbitMqFactory(is_use_rabbitpy=0).get_rabbit_cleint().creat_a_channel() channel.queue_declare(queue=self._queue_name, durable=True) channel.basic_qos(prefetch_count=self._threads_num) def callback(ch, method, properties, body): body = body.decode() self.logger.debug(f'从rabbitmq的 [{self._queue_name}] 队列中 取出的消息是: {body}') time.sleep(self._msg_schedule_time_intercal) body = json.loads(body) kw = {'ch': ch, 'method': method, 'properties': properties, 'body': body} self._submit_task(kw) if self.stop_flag: ch.close() # 使start_consuming结束。 channel.basic_consume(callback, queue=self._queue_name, # no_ack=True ) channel.start_consuming() def _shedual_task(self): channel = RabbitMqFactory(is_use_rabbitpy=0).get_rabbit_cleint().creat_a_channel() channel.queue_declare(queue=self._queue_name, durable=True) channel.basic_qos(prefetch_count=self._threads_num) while True: if self.stop_flag: return method, properties, body = channel.basic_get(self._queue_name, no_ack=False) if body is None: time.sleep(0.001) else: body = body.decode() self.logger.debug(f'从rabbitmq的 [{self._queue_name}] 队列中 取出的消息是: {body}') body = json.loads(body) kw = {'ch': channel, 'method': method, 'properties': properties, 'body': body} self._submit_task(kw) time.sleep(self._msg_schedule_time_intercal) def _confirm_consume(self, kw): with self._lock_for_pika: kw['ch'].basic_ack(delivery_tag=kw['method'].delivery_tag) # 确认消费 def _requeue(self, kw): with self._lock_for_pika: # ch.connection.add_callback_threadsafe(functools.partial(self.__ack_message_pika, ch, method.delivery_tag)) return kw['ch'].basic_nack(delivery_tag=kw['method'].delivery_tag) # 立即重新入队。 @staticmethod def __ack_message_pika(channelx, delivery_tagx): """Note that `channel` must be the same pika channel instance via which the message being ACKed was retrieved (AMQP protocol constraint). """ if channelx.is_open: channelx.basic_ack(delivery_tagx) else: # Channel is already closed, so we can't ACK this message; # log and/or do something that makes sense for your app in this case. pass class RabbitmqConsumerRabbitpy(AbstractConsumer): """ 使用rabbitpy实现的 """ BROKER_KIND = 1 def _shedual_task(self): # noinspection PyTypeChecker channel = RabbitMqFactory(is_use_rabbitpy=1).get_rabbit_cleint().creat_a_channel() # type: rabbitpy.AMQP # channel.queue_declare(queue=self._queue_name, durable=True) channel.basic_qos(prefetch_count=self._threads_num) for message in channel.basic_consume(self._queue_name, no_ack=False): body = message.body.decode() self.logger.debug(f'从rabbitmq {self._queue_name} 队列中 取出的消息是: {body}') time.sleep(self._msg_schedule_time_intercal) kw = {'message': message, 'body': json.loads(message.body.decode())} if self.stop_flag: return # channel.channel.close() self._submit_task(kw) def _confirm_consume(self, kw): kw['message'].ack() def _requeue(self, kw): kw['message'].nack(requeue=True) class RedisConsumer(AbstractConsumer, RedisMixin): """ redis作为中间件实现的。 """ BROKER_KIND = 2 def _shedual_task_old(self): while True: t_start = time.time() task_bytes = self.redis_db7.blpop(self._queue_name)[1] # 使用db7 if task_bytes: task_dict = json.loads(task_bytes) # noinspection PyProtectedMember self.logger.debug(f'取出的任务时间是 {round(time.time() - t_start, 2)} 消息是: {task_bytes.decode()} ') time.sleep(self._msg_schedule_time_intercal) kw = {'body': task_dict} if self.stop_flag: return self._submit_task(kw) def _shedual_task(self): # 这样容易控制退出消费循环。 while True: if self.stop_flag: return t_start = time.time() task_bytes = self.redis_db7.lpop(self._queue_name) # 使用db7 if task_bytes: task_dict = json.loads(task_bytes) # noinspection PyProtectedMember self.logger.debug(f'取出的任务时间是 {round(time.time() - t_start, 2)} 消息是: {task_bytes.decode()} ') kw = {'body': task_dict} self._submit_task(kw) else: time.sleep(0.001) time.sleep(self._msg_schedule_time_intercal) def _confirm_consume(self, kw): pass # redis没有确认消费的功能。 def _requeue(self, kw): self.redis_db7.rpush(self._queue_name, json.dumps(kw['body'])) def get_publisher(queue_name, *, log_level_int=10, logger_prefix='', is_add_file_handler=False, clear_queue_within_init=False, broker_kind=0): """ :param queue_name: :param log_level_int: :param logger_prefix: :param is_add_file_handler: :param clear_queue_within_init: :param broker_kind: 中间件或使用包的种类。 :return: """ all_kwargs = copy.deepcopy(locals()) all_kwargs.pop('broker_kind') if broker_kind == 0: return RabbitmqPublisher(**all_kwargs) elif broker_kind == 1: return RabbitmqPublisherUsingRabbitpy(**all_kwargs) elif broker_kind == 2: return RedisPublisher(**all_kwargs) else: raise ValueError('设置的中间件种类数字不正确') def get_consumer(queue_name, *, consuming_function: Callable = None, function_timeout=0, threads_num=50, specify_threadpool: ThreadPoolExecutor = None, max_retry_times=3, log_level=10, is_print_detail_exception=True, msg_schedule_time_intercal=0.0, logger_prefix='', create_logger_file=True, do_task_filtering=False, is_consuming_function_use_multi_params=True, is_do_not_run_by_specify_time_effect=False, do_not_run_by_specify_time=('10:00:00', '22:00:00'), schedule_tasks_on_main_thread=False, broker_kind=0): """ 使用工厂模式再包一层,通过设置数字来生成基于不同中间件或包的consumer。 :param queue_name: :param consuming_function: 处理消息的函数。 :param function_timeout : 超时秒数,函数运行超过这个时间,则自动杀死函数。为0是不限制。 :param threads_num: :param specify_threadpool:使用指定的线程池,可以多个消费者共使用一个线程池,不为None时候。threads_num失效 :param max_retry_times: :param log_level: :param is_print_detail_exception: :param msg_schedule_time_intercal:消息调度的时间间隔,用于控频 :param logger_prefix: 日志前缀,可使不同的消费者生成不同的日志 :param create_logger_file : 是否创建文件日志 :param do_task_filtering :是否执行基于函数参数的任务过滤 :param is_consuming_function_use_multi_params 函数的参数是否是传统的多参数,不为单个body字典表示多个参数。 :param is_do_not_run_by_specify_time_effect :是否使不运行的时间段生效 :param do_not_run_by_specify_time :不运行的时间段 :param schedule_tasks_on_main_thread :直接在主线程调度任务,意味着不能直接在当前主线程同时开启两个消费者。 :param broker_kind:中间件种类 :return """ all_kwargs = copy.copy(locals()) all_kwargs.pop('broker_kind') if broker_kind == 0: return RabbitmqConsumer(**all_kwargs) elif broker_kind == 1: return RabbitmqConsumerRabbitpy(**all_kwargs) elif broker_kind == 2: return RedisConsumer(**all_kwargs) else: raise ValueError('设置的中间件种类数字不正确') # noinspection PyMethodMayBeStatic,PyShadowingNames class _Test(unittest.TestCase, LoggerMixin, RedisMixin): """ 演示一个简单求和的例子。 """ @unittest.skip def test_publisher_with(self): """ 测试上下文管理器。 :return: """ with RabbitmqPublisher('queue_test') as rp: for i in range(1000): rp.publish(str(i)) @unittest.skip def test_publish_rabbit(self): """ 测试mq推送 :return: """ rabbitmq_publisher = RabbitmqPublisher('queue_test', log_level_int=10, logger_prefix='yy平台推送') rabbitmq_publisher.clear() for i in range(500000): try: time.sleep(1) rabbitmq_publisher.publish({'a': i, 'b': 2 * i}) except Exception as e: print(e) rabbitmq_publisher = RabbitmqPublisher('queue_test2', log_level_int=20, logger_prefix='zz平台推送') rabbitmq_publisher.clear() [rabbitmq_publisher.publish({'somestr_to_be_print': str(i)}) for i in range(500000)] @unittest.skip def test_publish_redis(self): # 如果需要批量推送 for i in range(10007): # 最犀利的批量操作方式,自动聚合多条redis命令,支持多种redis混合命令批量操作。 RedisBulkWriteHelper(self.redis_db7, 1000).add_task(RedisOperation('lpush', 'queue_test', json.dumps({'a': i, 'b': 2 * i}))) [self.redis_db7.lpush('queue_test', json.dumps({'a': j, 'b': 2 * j})) for j in range(500)] print('推送完毕') @unittest.skip def test_consume(self): """ 单参数代表所有传参 :return: """ def f(body): self.logger.info(f'消费此消息 {body}') # print(body['a'] + body['b']) time.sleep(5) # 模拟做某事需要阻塞10秒种,必须用并发。 # 把消费的函数名传给consuming_function,就这么简单。 rabbitmq_consumer = RabbitmqConsumer('queue_test', consuming_function=f, threads_num=20, msg_schedule_time_intercal=0.5, log_level=10, logger_prefix='yy平台消费', is_consuming_function_use_multi_params=False) rabbitmq_consumer.start_consuming_message() @unittest.skip def test_consume2(self): """ 测试支持传统参数形式,不是用一个字典里面包含所有参数。 :return: """ def f2(a, b): self.logger.debug(f'a的值是 {a}') self.logger.debug(f'b的值是 {b}') print(f'{a} + {b} 的和是 {a + b}') time.sleep(3) # 模拟做某事需要阻塞10秒种,必须用并发。 # 把消费的函数名传给consuming_function,就这么简单。 RabbitmqConsumer('queue_test', consuming_function=f2, threads_num=60, msg_schedule_time_intercal=5, log_level=10, logger_prefix='yy平台消费', is_consuming_function_use_multi_params=True).start_consuming_message() @unittest.skip def test_redis_filter(self): """ 测试基于redis set结构的过滤器。 :return: """ redis_filter = RedisFilter('abcd') redis_filter.add_a_value({'a': 1, 'c': 3, 'b': 2}) redis_filter.check_value_exists({'a': 1, 'c': 3, 'b': 2}) redis_filter.check_value_exists({'a': 1, 'b': 2, 'c': 3}) with decorators.TimerContextManager(): print(redis_filter.check_value_exists('{"a": 1, "b": 2, "c": 3}')) with decorators.TimerContextManager(): # 实测百万元素的set,过滤检查不需要1毫秒,一般最多100万个酒店。 print(RedisFilter('filter:mafengwo-detail_task').check_value_exists({"_id": "69873340"})) @unittest.skip def test_run_two_function(self): # 演示连续运行两个consumer def f3(a, b): print(f'{a} + {b} = {a + b}') time.sleep(10) # 模拟做某事需要阻塞10秒种,必须用并发。 def f4(somestr_to_be_print): print(f'打印 {somestr_to_be_print}') time.sleep(20) # 模拟做某事需要阻塞10秒种,必须用并发。 RabbitmqConsumer('queue_test', consuming_function=f3, threads_num=20, msg_schedule_time_intercal=2, log_level=10, logger_prefix='yy平台消费', is_consuming_function_use_multi_params=True).start_consuming_message() RabbitmqConsumer('queue_test2', consuming_function=f4, threads_num=20, msg_schedule_time_intercal=4, log_level=10, logger_prefix='zz平台消费', is_consuming_function_use_multi_params=True).start_consuming_message() # AbstractConsumer.join_shedual_task_thread() # @unittest.skip def test_factory_pattern_consumer(self): """ 测试工厂模式来生成消费者 :return: """ def f2(a, b): # body_dict = json.loads(body) self.logger.info(f'消费此消息 {a} {b} ,结果是 {a+b}') # print(body_dict['a'] + body_dict['b']) time.sleep(2) # 模拟做某事需要阻塞10秒种,必须用并发。 # 把消费的函数名传给consuming_function,就这么简单。 consumer = get_consumer('queue_test5', consuming_function=f2, threads_num=30, msg_schedule_time_intercal=1, log_level=10, logger_prefix='zz平台消费', function_timeout=20, is_print_detail_exception=True, broker_kind=0) # 通过设置broker_kind,一键切换中间件为mq或redis consumer.publisher_of_same_queue.clear() [consumer.publisher_of_same_queue.publish({'a': i, 'b': 2 * i}) for i in range(80)] consumer.start_consuming_message() # consumer.stop_flag = 1 # 原则是不需要关闭消费,一直在后台等待任务,循环调度消息。如果需要关闭可以使用下面。 nb_print('判断完成阻塞中。。。') consumer.wait_for_possible_has_finish_all_tasks(2, stop_flag=1) nb_print('这一行要等疑似结束判断,才能运行。。。') if __name__ == '__main__': # noinspection PyArgumentList unittest.main(sleep_time=1)
1、虽然实现这样的万能异步分布式框架代码很长,代码看起来有点复杂(如果真正的懂oop,看起来就不复杂,里面用了大量 模板模式 工厂模式 装饰器 等)。但使用却极其简单。核心就是定义了一个函数,只需要把函数传给这个Consumer类的初始化方法,并和队列名绑定,就可以一行代码实现分布式消费了。Consumer类的实例初始化参数只有2个是最本质核心,分别是队列名字和函数,其余的参数全是辅助功能。目前框架已用于多个平台以及线上生产项目中,相当稳定。
我的写代码理念是做任何事,最好尽可能先设计好想好,然后抽取可复用流程或框架。我希望只麻烦、 很复杂一次,而不是使用无限复制粘贴扣字的做法来麻烦 复杂无数次。
2、使用这个框架,能大大简化一切需要分布式的代码,使你在写任何需要分布式的项目和平台时候,都不需要关心分布式本身,只需要专注于写好函数,写完后,直接把函数和队列名绑定,实例化一个consumer实例,然后执行start_consuming_message方法就可以。
3、有人有疑惑为什么反复强调的是函数?类行不行?
这个调度的本质是从中间件队列中取到一个消息,消息是json形式,例如取到的消息是 {"a":1,"b":2},
一个函数是 def add(a,b):
print(a + b)
那么框架自动使用 add(** {"a":1,"b":2}) 的参数来调用 add函数。如果是类,很难判断到底哪些参数传给实例的初始化方法,哪些传给其他方法。
如果是这样的形式 Aclass(x).fun(y), 那再用函数包装一层就可以了,
例如 def ffff(x,y):
Aclass(x).fun(y)
然后把ffff作为函数传给consumer的初始化方法就可以了。
虽然实现框架用了很多类,但消费的不使用类的原因,
1)使用类,那就是有状态的,分布式最好是无状态的,函数更好。
2)再者一般这里面的consuming_function要简单,每个函数只要做一件简单的事,然后由框架无限次循环调度。如果一个函数做的事情太大,一个函数内部啥都干了,一个函数运行需要持续几十分钟几个小时,那分布式就成了废物,可以吧这个巨大的函数任务弄成边消费边推送,分解成很多细粒度的任务。分布式就是要消费大量细粒度的任务,使每台机器都有机会消费),弄错一个细粒度的任务,重试时候不至于造成巨大代价。所以简单细粒度的任务一般也不需要用类。
3)再者 celery装饰器也是加在函数上,celery的任务也是函数单元,所以是不需要类的。
4、分布式为什么重要?
即使是只有一台机器,做分布式也很重要
a/ 这可以保存未消费的消息,停止脚本可以继续接着运行未消耗的任务。
b/并且支持使用多进程而不需要考虑进程间通信,
c/而且支持重复启动同一个脚本10次,使这十个运行中的脚本都有机会消费任务
d/python有个垃圾的地方是只能使用单核,如果只使用单进程,那32核linux电脑本来可以达到3200%的cpu使用率,但python由于设计的原因,python程序繁忙得到天了也只能把cpu消耗到100%,这一点在linux使用top命令查看可以证实,一个python脚本即使再忙碌运算量再大,这个linux进程绝对不会超过120%cpu使用率,java能把cpu消耗到3000%都可以,所以需要使用多进程或多次启动来充分使用机器cpu。如果没有分布式,一个脚本在消耗任务,别的脚本又不知道这个脚本还需要做哪些任务,大大的浪费cpu空闲资源,python是解释性语言性能本来就垃圾再加上单进程不能充分使用多核优势,造成了py性能雪上加霜,比java性能差了50倍,比c语言速度差了100倍。所以python比其他语言更需要分布式了。
如果是winwods用户也可以证实,比如你电脑是i5 四核的,windows的cpu总数是100%使用率(和linux的统计不一样),即使你写个脚本反复计算运行100次1加到10亿,这毫无疑问会造成cpu很忙碌,但python的设计原因,你的python消耗的cpu会是25%。总之就是无论 在linux还是windows,python都不能 充分利用cpu,所以需要分布式,便于多进程消费。
这个框架最好是用于io任务非纯cpu计算的,但即使是io任务,由于python性能很差劲,做同样的事情要消耗比c语言更高的cpu使用率更长的运行时间,即使是io任务python也会消耗很多cpu,所以io任务通常也需要使用多进程来充分使用cpu,所以分布式很重要。这个Conusmer类不仅是可以分布式,还提供了标题中的另外10种功能。
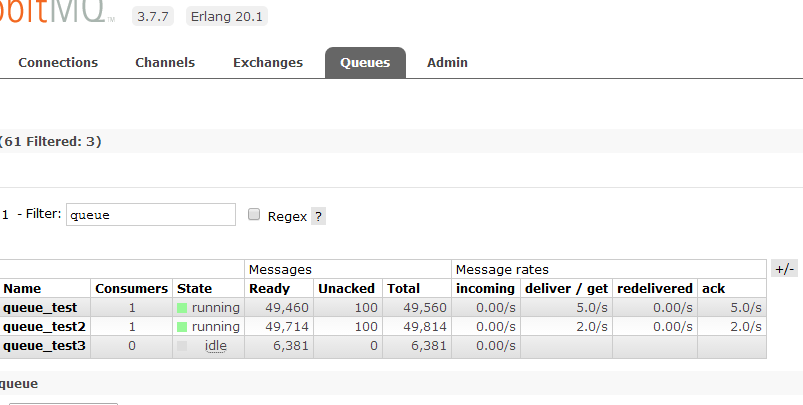
运行结果是这样。

如果设置msg_schedule_time_intervel 为0.2和0.5,可以发现,的确是做到了控频。精确地控制了每秒执行5次和2次的速度。
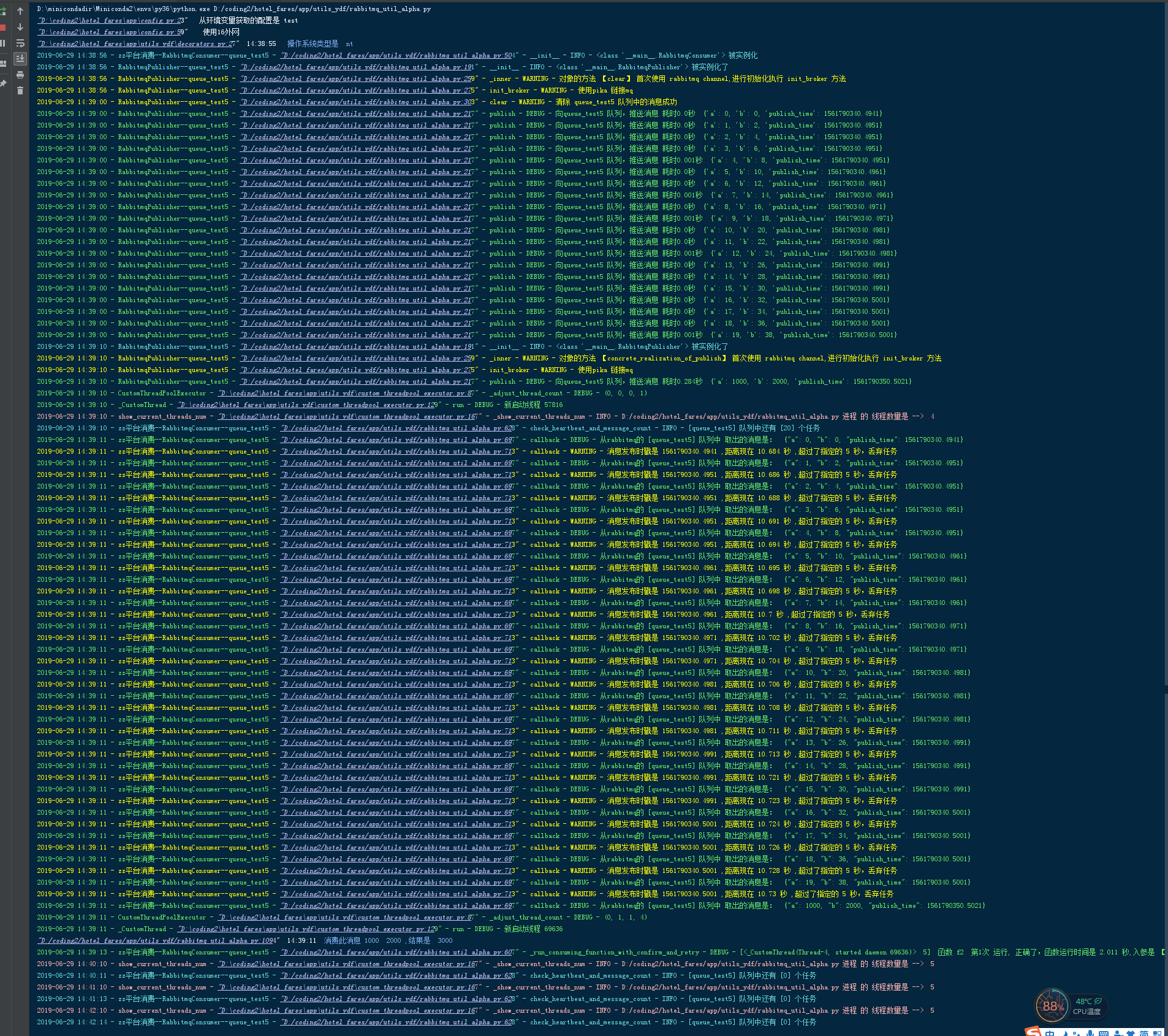
测试任务过期
也可以使用java发消息,py来运行。默认使用json来序列化和反序列化消息。所以推送的消息必须是简单的,不要把一个自定义类型的对象作为消费函数的入参,json键的值必须是简单类型,例如 数字 字符串 数组 字典这种。不可以是不可被json序列化的自定义类型的对象。用json序列化已经满足所有场景了, picke序列化更强,但仍然有一些自定义类型的对象的实例属性由于是一个不可被序列化的东西,picke解决不了,这种东西例如self.r = Redis() ,不可以序列化,就算能序列化也是要用一串很长的东西来表示这种属性,导致中间件要存储很大的东西传输效率会降低,这种完全可以使用json来解决,例如指定ip 和端口,在消费函数内部来使用redis。所以用json一定可以满足一切传参场景。
如果是使用celery,由于推送时候要读取项目配置,java和python基本不能配合。这一点可以从消息里面的结构可以证实,因为celery的消息包括了函数参数、celery项目的配置、装饰器的参数配置。
celery主要核心使用理念是在函数上加入装饰器,装饰器指定任务的路由,或者在独立的配置中指定路由。然后调用 函数名.delay(x,y),这样消费和发布都是自动使用同一个队列了。很魔术,但作用也不是很大,黑魔法实在python的ide里面代码是不能自动补全提示的,因为用了元编程,是一种动态的,pycharm只能解析死语法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号