《An Attentive Survey of Attention Models》阅读笔记
本文是对文献 《An Attentive Survey of Attention Models》 的总结,详细内容请参照原文。
引言
注意力模型现在已经成为神经网络中的一个重要概念,并已经应用到多个应用领域。本文给出了注意力机制的主要思想,并对现有的一些注意力模型进行了分类,以及介绍了注意力机制与不同的神经结构的融合方法,并且还展示了注意力是如何提高神经网络模型的可解释性的。最后,本文讨论了一些具体应用程序中注意力机制的应用与建模过程。
Attention Model(AM)首次被 Bahdanau[1] 等人引用来解决机器翻译等问题,并已经作为神经网络架构的重要组成部分来广泛应用与自然语言处理,统计学习,语音和计算机视觉等多种领域。注意力机制的主要思想请参考资料:浅谈 Attention 机制的理解。神经网络中的 attention model 的快速发展主要有三个原因:
- 注意力模型是最先进的模型,并且可以用于多种任务,如机器翻译,问答系统,情感分析,部分语音标记,选区分析和对话系统等;
- 注意力模型可以用于改善神经网络的可解释性。目前神经网络被认为是黑盒模型,而人们对影响人类生活的应用中的机器学习模型的公平性,责任性和透明度越来越感兴趣。
- 注意力模型有助于克服 RNN 中存在的一些问题,例如随着输入序列长度的增加,模型性能下降的问题,以及输入顺序处理导致的计算效率低下的问题。
Attention Model
该文献依然是从经典的 Encoder-Decoder 模型中来引入注意力模型,这有利于读者对 Attention 机制有更直观的理解,同样可以参考浅谈 Attention 机制的理解。
以 Sequence-to-sequence 模型为例,该模型包含了一个 Encoder-Decoder 架构。其中,Encoder 是一个 RNN 结构,将序列 \(\lbrace x_1,x_2,\dots,x_T \rbrace\) 作为其输入,\(T\) 表示输入序列的长度,并将该序列编码成固定长度的向量集合 \(\lbrace h_1,h_2,\dots,h_T \rbrace\) 。Decoder 也是一个 RNN 结构,将一个单一的固定长度的向量 \(h_T\) 作为输入,并且迭代地生成一个输出序列 \(\lbrace y_1,y_2,\dots,y_{T'} \rbrace\),\(T^{'}\) 表示输出序列的长度。在每个时刻 \(t\),\(h_t\) 和 \(s_t\) 分布表示 Encoder 和 Decoder 的隐藏层状态。
传统 encoder-decoder 的挑战
- Encoder 需要将所有的输入信息压缩成传递给 Decoder 的单个固定长度的向量 \(h_T\),该向量可能无法表示输入序列的详细信息,导致信息丢失;
- 无法模拟输入和输出序列之间的对齐,而这在结构化输出任务(如翻译或摘要)中十分重要;
- Decoder 无法在生成输出时重点关注与其相关的输入的单词,而是同权地考虑所有的输入元素。
关键思想
Attention Model 旨在通过允许 Decoder 访问整个编码的输入序列 \(\lbrace h_1,h_2,\dots,h_T \rbrace\) 来解决上述的问题。中心思想时在输入序列上引入 attention 权重 \(\alpha\) ,从而在生成下一个输出标记时优先考虑集合中存在相关信息的位置集。
attention 使用
相应的具有注意力机制的 Encoder-Decoder 的架构如 Figure 2(b) 所示。架构中的 attention block 负责自动学习注意力权重 \(\alpha_{ij}\) ,该参数表示了 \(h_i\) 和 \(s_i\) 之间的相关性,其中 \(h_i\) 为 Encoder 隐藏状态,也称之为候选状态,\(s_i\) 为 Decoder 隐藏层状态,也称之为查询状态。这些注意力权重然后被用来建立一个上下文向量 \(c\),该向量作为一个输入传递给 Decoder。在每个解码位置 \(j\),上下文向量 \(c_j\) 是所有 Encoder 的隐藏层状态和他们对应的注意力权重的加权和,即 \(c_j=\sum_{i=1}^T{\alpha_{ij}h_i}\)。该机制的优势是 Decoder 不仅考虑了整个输入序列的信息,而且集中关注了那些在输入序列中相关的信息。
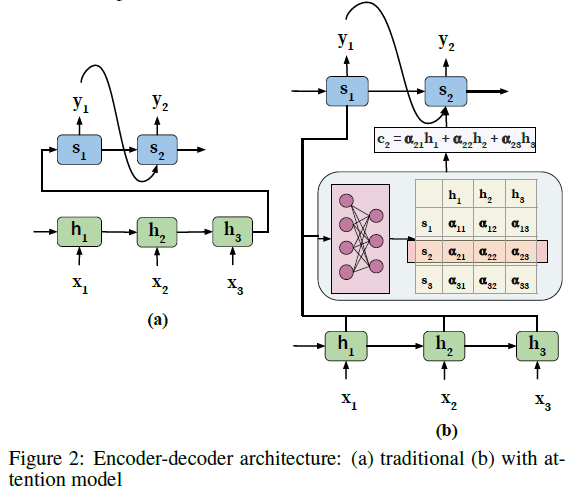
学习 attention 权重
注意力权重是通过在体系结构中并入一个额外的前馈神经网络来学习的。该前馈神经网络学习将候选状态和查询状态作为神经网络的输入,并学习一个关于这两个隐藏层状态 \(h_i\) 和 \(s_{j-1}\) 的特定注意力权重 \(\alpha_{ij}\)。注意,此前馈神经网络需要和架构中的 encoder-decoder 组件一起联合训练。
此处在计算注意力权重的时候使用的是 \(s_{j-1}\),这是因为我们当前在计算 \(y_j\) 时是不知道 \(s_j\) 状态的,所以只能使用前一个状态。
注意力分类
该文献将注意力主要分为四大类,但是需要注意的是这些类别并不是互斥的,Attention 可以应用于多种类型的组合当中,例如 Yang[2] 等人将 multi-level 和 self and soft attention 进行组合使用。因此,我们可以将这些类别看作是将注意力用于感兴趣的应用时可以考虑的维度。
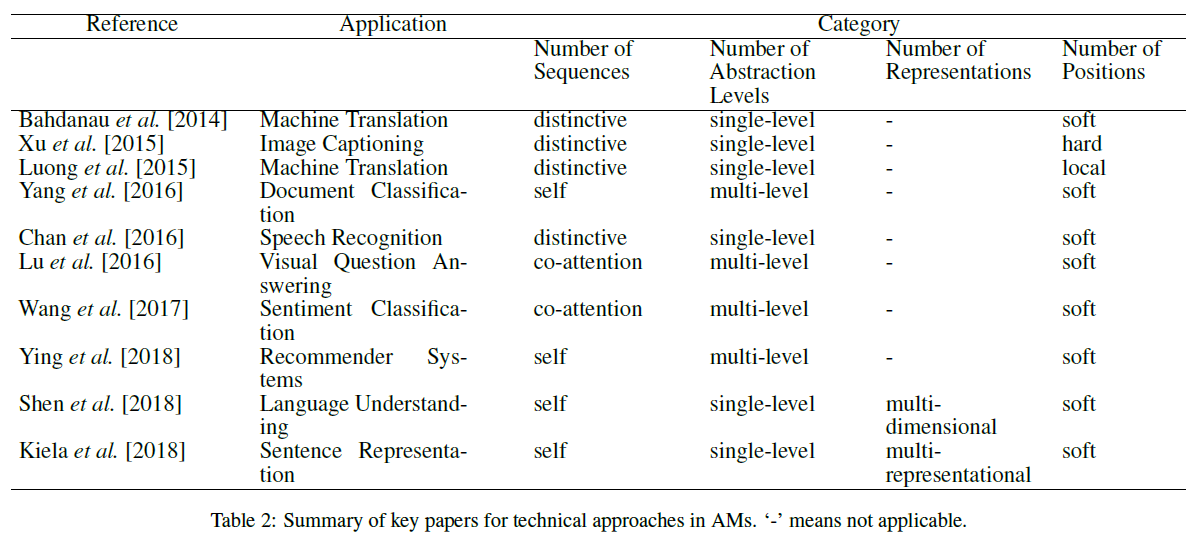
Number of sequences
到目前为止,我们只考虑了涉及到单个输入和对应输出序列的情况。当候选状态和查询状态分布属于两个不同的输入序列和输出序列时,就会使用这种类型的注意力,我们称之为 distinctive 。
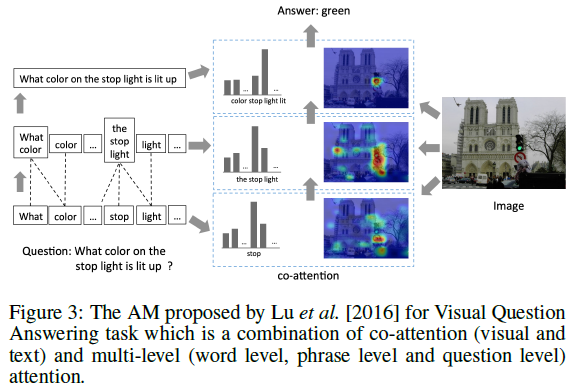
co-attention 模型同时对多个输入序列进行操作,并共同学习它们的注意力,以捕获这些输入之间的相互作用。
相反,对于诸如文本分类和推荐之类的任务,输入是序列,但输出不是序列。在这种情况下,可以使用注意力来学习输入序列中对应于相同输入序列中的每个标记的相关标记。换句话说,查询和候选状态属于这种类型的关注的相同序列,这种注意力模型称为 self-attention。
Number of abstraction levels
在最一般的情况中,仅针对原始的输入序列计算注意力权重,这种类型的注意力可以称之为 single-level。另一方面,可以按照顺序将注意力应用于输入序列的多个抽象层次,较低抽象级别的输出(上下文向量)成为较高抽象级别的查询状态。此外,使用 multi-level 注意力的模型可以进一步根据权重自上而下学习或者自下而上学习来进一步分类。多层注意力模型的最典型的示例就是文档的学习,文档是由句子组成的,而句子是由单词组成的,因此可以建立两层的 attention 机制。
Number of positions
在该分类依据中,主要是根据在计算注意力函数时输入序列的位置。Bahdanau[1:1] 等人提出的注意力也被称为 soft-attention 。顾名思义,它使用输入序列的所有隐藏状态的加权平均值来构建上下文向量。这种软加权方法的使用使得神经网络易于通过反向传播进行有效学习,但也导致二次计算成本。
Xu[3] 等人提出了一种 hard-attention 模型,其中上下文向量是通过从输入序列中随机采样隐藏层状态来计算得到,这是通过一个由注意力权重参数化的多项式分布来实现的。由于降低了计算成本,hard-attention 模型是有效的,但是在输入的每个位置做出一个艰难的判决使得所得到的框架不可微并且难以优化。因此,为了克服这一局限性,文献中提出了变分学习方法和强化学习中的策略梯度方法。
Luong[4]等人提出了两种注意力模型用于机器翻译任务,分别命名为 local attention 和 global attention。其中,global attention 和 soft-attention 是相似的,而 local attention 介于 soft-attention 和 hard-attention 之间。关键思想是首先检测输入序列中的注意点或位置,并在该位置周围选择一个窗口以创建局部软注意(local soft attention)模型。输入序列的位置可以直接设置(单调对齐)或通过预测函数(预测对齐)学习。因此,local attention 的优点是在 soft-attention 和 hard-attention 、计算效率和窗口内的可微性之间提供参数权衡。
Number of representations
通常,大多数应用程序都使用输入序列的单一特征表示。然后,在某些场景中,使用输入的一个特征表示可能无法满足下游任务。在这种情况下,一般会通过多个特征表示来捕获输入的不同方面。attention 机制可以用于将重要性权重分配给这些不同的表示,这些表示可以确定最相关的方面,而忽略输入中的噪声和冗余。我们将这种模型称为 multi representational AM,因此它可以确定下游应用的输入的多个表示的相关性。最终表示形式是这些多个表示形式及其注意权重的加权组合。attention 机制的一个好处是通过检查权重可以直接评估哪些嵌入更适合哪些特定的下游任务。例如,Kiela[5]等人通过学习相同输入句子的不同单词嵌入的注意权重,以改善句子表示。
基于相似的直觉,在 multi-dimensional 注意中,可以引入权重来确定输入嵌入向量的每个维度的相关性。因为计算向量的每个特征的得分可以选择能够在任何给定的上下文中最好地描述标记的特定含义的特征。这对于自然语言应用程序来说尤其有用,因为在自然语言应用程序中,word 嵌入会存在一词多义的问题。
注意力网络架构
文献介绍了三个主要与 attention 机制进行结合的神经网络架构:(1)encoder-decoder 架构;(2)将注意力扩展到单个输入序列之外的内存网络(memort networks);(3)利用注意力绕过递归模型的顺序处理组件的体系结构。
Encoder-Decoder
注意力机制的早期使用是作为基于 RNN 的 encoder-decoder 架构的一部分来对长的输入语句进行编码。
一个有趣的事实是,Attention Model 可以采用任何输入表示,并将其减少为一个固定长度的上下文向量,以应用于解码步骤。因此,它允许将输入表示与输出解耦。人们可以利用这个好处来引入混合编码器 - 解码器,最流行的就是将卷积神经网络(CNN)作为编码器,而把 RNN 或长短期存储器(LSTM)作为解码器。这种类型的架构特别适用于那些多模态任务,例如图像和视频字幕,视觉问答和语音识别。
然而,并非所有输入和输出都是顺序数据的问题都可以用上述模式解决,例如排序和旅行商问题。文献给出了一个指针网络的示例,可以阅读文献进一步了解。
Memory Network
像问答和聊天机器人这样的应用程序需要能够从事实数据库中的信息进行学习。网络的输入是一个知识数据库和一个查询,其中存在一些事实比其他事实更与查询相关。端到端内存网络通过使用一组内存块存储事实数据库来实现这一点,并使用 attention 机制在回答查询时在内存中为每个事实建立关联模型。attention 机制通过使目标连续,并支持端到端的训练反向传播模型来提高计算效率。端到端内存网络(End-to-End Memory Networks)可以看作是 AM 的一种泛化,它不是只在单个序列上建模注意力,而是在一个包含大量序列 (事实) 的数据库上建模注意力。
Networks without RNNs
循环体系结构依赖于在编码步骤对输入的顺序处理,这导致计算效率低,因为处理不能并行化。为此,Vaswani[6] 等人提出了 Transformer 架构,其中 encoder 和 decoder 由一堆具有两个子层的相同的层组成,两个子层分别为位置定向前馈网络层(FFN)和多抽头自注意层(multi-head self attention)。
Position-wise FFN:输入是顺序的,要求模型利用输入的时间方面,但是不使用捕获该位置信息的组件(即 RNN/CNN)。为此,转换器中的编码阶段使用 FFN 为输入序列的每个标记生成内容嵌入和位置编码。
Multi-head Self-Attention:在每个子层中使用 self-attention 来关联标记及其在相同输入序列中的位置。此外,注意力被称为 multi-head ,因为几个注意力层是并行堆叠的,具有相同输入的不同线性变换。这有助于模型捕获输入的各个方面,并提高其表达能力。转换结构实现了显著的并行处理,训练时间短,翻译精度高,无需任何重复的组件,具有显著的优势。
注意力的可解释性
受到模型的性能以及透明度和公平性的推动,人工智能模型的可解释性引起了人们的极大兴趣。然而,神经网络,特别是深度学习架构因其缺乏可解释性而受到广泛的吐槽。
从可解释性的角度来看,建模注意力机制特别有趣,因为它允许我们直接检查深度学习架构的内部工作。假设注意力权重的重要性与序列中每个位置的输出的预测和输入的特定区域的相关程度高度相关。这可以通过可视化一组输入和输出对的注意权重来轻松实现。

注意力机制的应用
注意力模型由于其直观性、通用性和可解释性,已成为研究的一个活跃领域。注意力模型的变体已经被用来处理不同应用领域的独特特征,如总结、阅读理解、语言建模、解析等。主要包括:
- MT:机器翻译,使用算法将文本或语音从一种语言翻译成另一种语言;
- QA:问答系统,根据问题给出相应的回答;
- MD:多媒体描述,根据多媒体输入序列,如语音、图片和视频等,生成自然语言文本描述;
- 文本分类:主要是使用 self-attention 来构建更有效的文档表示;
- 情感分析:在情绪分析任务中,self-attention 有助于关注对确定输入情绪很重要的词;
- 推荐系统:将注意力权重分配给用户的交互项目以更有效的方式捕获长期和短期利益。
近年来,人们的注意力以新颖的方式被利用,为研究开辟了新的途径。一些有趣的方向包括更平滑地整合外部知识库、训练前嵌入和多任务学习、无监督的代表性学习、稀疏性学习和原型学习,即样本选择。
总结
该文献讨论了描述注意力的不同方法,并试图通过讨论注意力的分类、使用注意力的关键神经网络体系结构和已经看到显著影响的应用领域来概述各种技术。文献讨论了在神经网络中加入注意力是如何带来显著的性能提高的,通过促进可解释性提供了对神经网络内部工作的更深入的了解,并通过消除输入的顺序处理提高了计算效率。
参考文献
Neural machine translation by jointly learning to align and translate ↩︎ ↩︎
Hierarchical attention networks for document classification ↩︎
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ↩︎
Effective approaches to attention-based neural machine translation ↩︎
Dynamic meta-embeddings for improved sentence representations ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号