Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
一、语义分割、实例分割和全景分割的区别
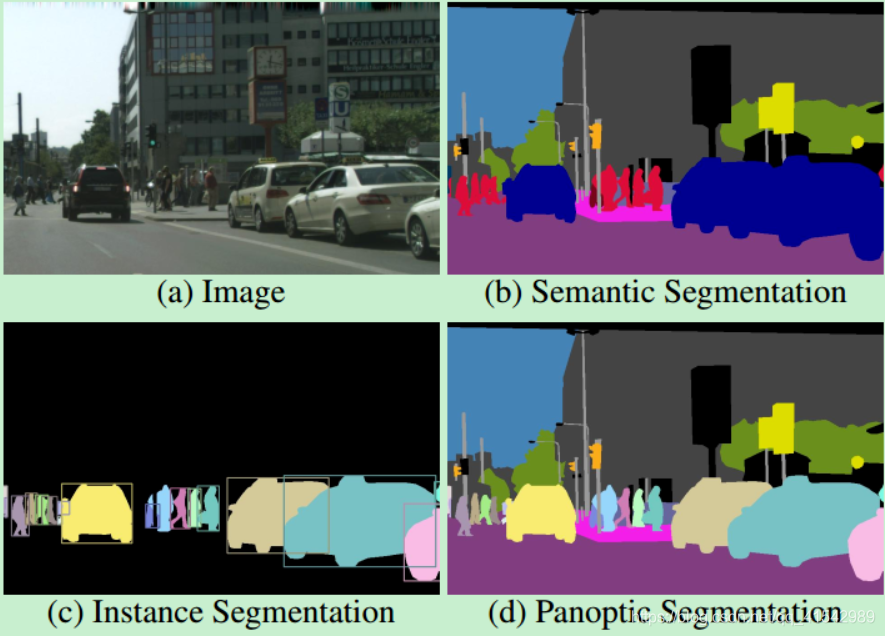
b图是语义分割,包括背景,但是同一个类别都是同一个颜色;
c图是实力分割,背景全部变为黑色,但是同一个类别中每一个实例都要区分开,就是要有自己的id
d图是全景分割,b+c的结合
二、全景分割
目标:图像中的每个像素分配一个唯一的值,编码语义标签和实例id。它需要识别图像中每个单独“thing”的类别和范围,并标记属于每个“thing”类别的所有像素。(所有语义标签要么属于stuff,要么属于thing,不能同时属于二者;且stuff类别没有实例id,即id统一为一个)
问题:与语义分割相比,全景分割的困难在于要优化全连接网络的设计,使其网络结构能够区分不同类别的实例;而与实例分割相比,由于全景分割要求每个像素只能有一个类别和id标注,因此不能出现实例分割中的重叠现象
目前有两种方法:
自上而下:将一个语义分割分支附加到掩码R-CNN ,生成重叠的实例掩码以及重复的像素语义预测。为了解决冲突,常用的启发式方法通过预测的置信度得分,或者甚至通过类别之间的成对关系来解决重叠的实例掩码。此外,语义和实例分割结果之间的差异通过支持实例预测来分类。虽然有效,但以快速和并行的方式实现手工制作的试探法可能很难。另一个有效的方法是开发高级模块来融合语义和实例分割结果。
缺点:这些自上而下的方法通常速度较慢。
自下而上:自下而上的方法通过预测不重叠的片段来自然地解决冲突。只有少数作品采用自下而上的方法,这种方法通常从语义分割预测开始,然后进行分组操作以生成实例掩码。以这种顺序处理全景分割允许简单快速的方案,例如多数投票,来合并语义和实例分割结果。尽管获得了令人满意的快速推理速度,但与公共基准中流行的自上而下的方法相比,自下而上的方法仍然表现出较差的性能。
三、全景深度实验室
目的:旨在为自下而上的方法建立一个坚实的baseline,该方法可以实现两阶段方法的可比性能,同时产生快速的推理速度。
全景视觉深度实验室分别采用了特定于语义和实例分割的双ASPP和双解码器结构。语义分割分支与任何语义分割模型(例如DeepLab)的典型设计相同,而实例分割分支与类无关,涉及简单的实例中心回归。
核心思想:
1.一种高效的bottom-up全景分割方法,比two-stage更快。
2.一个统一的backbone,分出两个结构非常相似的头部,实现两种任务:一个是one-stage的实例分割,一个是语义分割,最终通过后处理将二者集成起来。
3.one-stage实例分割实际上是class-agnostic(类别无关)的offset回归 + 实例中心heatmap。
4.这个框架可以用任意的语义分割的代替,具有很强的灵活性。
四、全景深度实验室组成
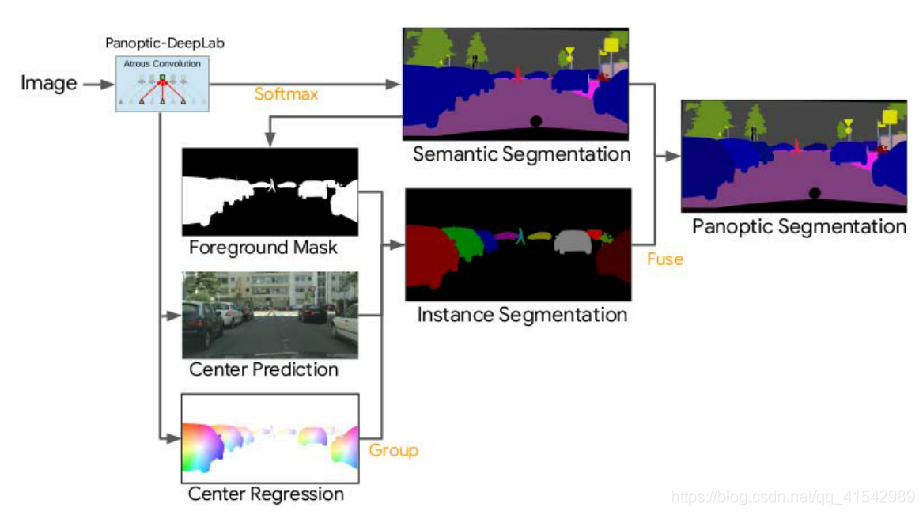
全景深度实验室预测三个输出:语义分割、实例中心预测和实例中心回归。通过将预测的前景像素分组到它们最近的预测实例中心而获得的类无关的实例分割,然后通过多数投票规则与语义分割融合以生成最终的全景分割。
该文章涉及到东西:
使用三个损失函数:
1.语义分割头(Lsem)的加权自举交叉熵损失
2.中心热图头的均方误差损失(Lheatmap)
3.中心偏置头的L1损耗
全景深度实验室比语义深度实验室增加了边缘参数和少量计算开销。
此外,通过合并操作的快速GPU实现,全景深度实验室提供了近乎实时的端到端全景分割预测。
损失函数:
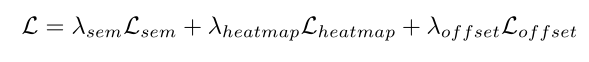
五、全景深度实验室原理图
六、全景深度实验室结构详解
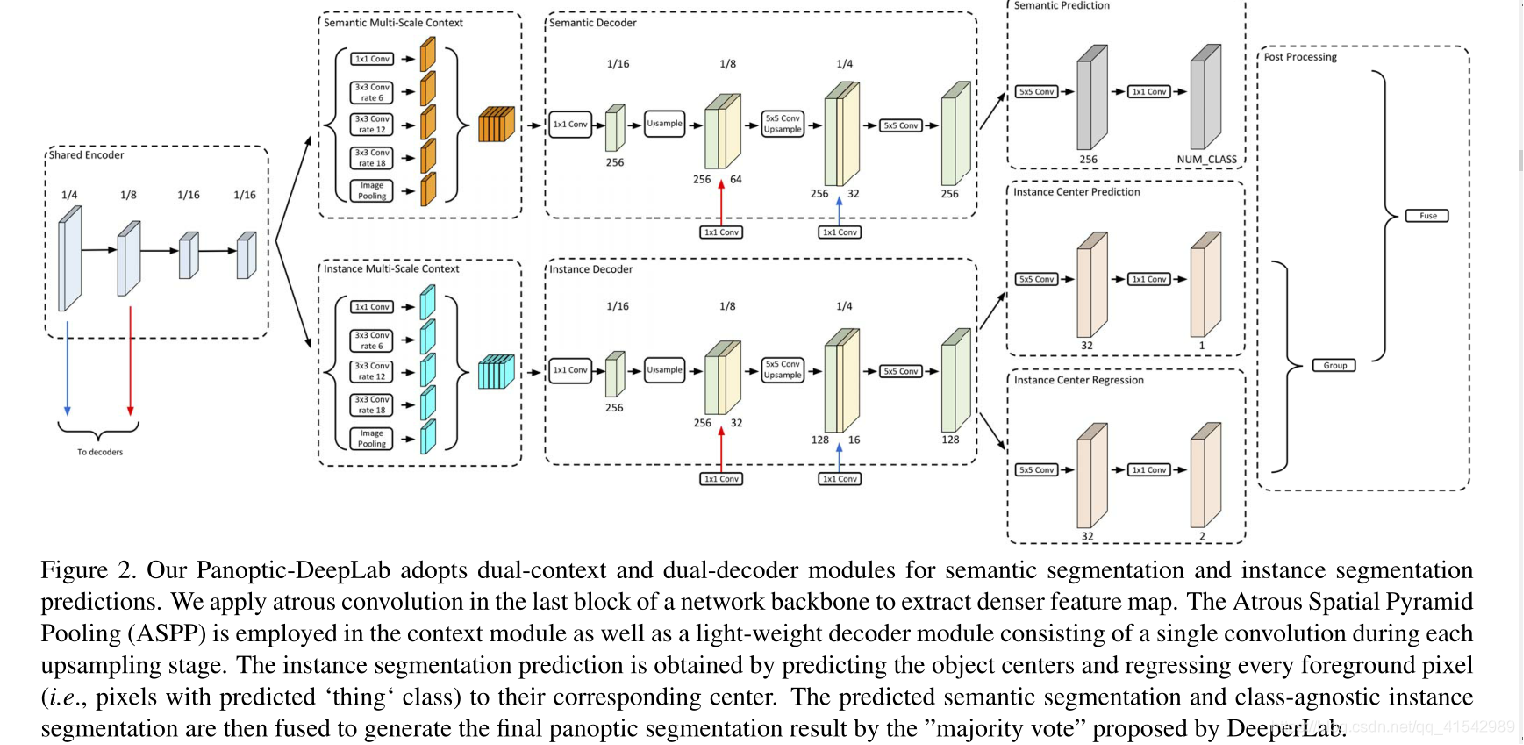
全景深度实验室由四个部分组成:
(1)一个编码器中枢,用于语义分割和实例分割;
(2)解耦的ASPP模块(空洞空间金字塔池化);
(3)解耦的特定于每个任务的解码器模块;
(4)特定于任务的预测头。
1.Backbone:基于ImageNet Pretrain,在最后一层加上Atrous Convolution(空洞卷积)
2.ASPP模块: 用于提取multi-scale的context
3.Decoder: 基于DeepLab V3修改了2部分,包括引入了1/8尺度的skip-connection,以及每次上采样之后加上了5x5的卷积。至此,语义分割和实例分割的分支结构都完全相同。这么做的一大优势在于各任务的梯度能够更均衡,这样的多任务网络能够更好地收敛
4.语义分割的头部是一个很常见的FCN(全卷积网络)
5.实例分割:
5.1通过实例的质心 + 实例对应的每个像素点对于质心的偏移量来表征一个实例
5.2对于质心的回归用L2,偏移量的回归用L1
七、全景深度实验室结构改进
解码器模块遵循DeepLabV3+ ,并做了两项修改:
(1)在解码器中引入了一个输出步长为8的附加低电平特性,因此空间分辨率逐渐恢复到2倍;
(2)在每个上采样阶段,我们应用一个5 × 5深度可分离卷积。
语义分割头的改进:
加权自举交叉熵损失进行语义分割,预测“thing”和“thing”类。通过对每个像素进行不同的加权,该损失比自举交叉熵损失有所改善。
实例分割头的改进:
通过每个对象实例的质心来表示它。对于每个前景像素(即其类别为“thing”的像素),进一步预测到其对应质心的偏移。在训练期间,groundtruth instance centers由标准偏差为8像素的二维高斯编码。并且采用均方误差(MSE)损失来最小化预测的热图和2D高斯编码的地面实况热图之间的距离。使用L1loss进行偏移预测,它仅在属于对象实例的像素处激活。在推断过程中,预测的前景像素(通过从语义分割预测中过滤掉背景“填充”区域获得)被分组到它们最近的预测质心,形成我们的类不可知的实例分割结果。
八、全景分割(两个合并)
第一个合并:
简单的实例表示法:
简单地通过物体的质心{Cn: (in,jn)}来表示每个物体。为了获得中心点预测,我们首先在实例中心热图预测上执行基于关键点的非最大抑制(NMS),本质上相当于在热图预测上应用最大池化,并保持其值在最大池化前后不变的位置。最后,使用硬阈值过滤掉低置信度的预测,只保留置信度得分最高的位置。在实验中,我们使用最大池,内核大小为7,阈值为0.1,k = 200。
简单实例分组:
为了获得每个像素的实例id,使用简单的实例中心回归。例如,考虑位置(I,j)处的预测“thing”像素,预测到其实例中心的offset vectorO(i,j)。O(i,j)是一个包含两个元素的向量,分别表示水平和垂直方向的偏移量。因此,像素的实例id是在将像素位置(I,j)移动偏移量O(i,j)后最近的实例中心的索引。
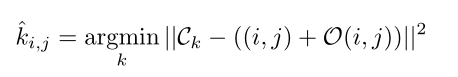
其中左侧k是(i,j)处像素的预测实例id。使用语义分割预测来过滤掉实例id总是设置为0的“填充”像素。
第二个合并:
计算每个实例掩码的类特定置信度得分如下(对每个像素点的分数进行重新整合)
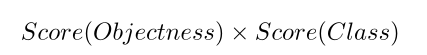
其中,Score(Objectness)是从实例分割中类无关的中心点热图获得的非标准化对象性分数,Score(Class)是语义分割中每个点的置信度。
高效的合并:给定预测的语义分割和类无关的实例分割结果,遵循DeeperLab中提出的“多数投票”原则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号