多标签分类中的损失函数与评估指标
文章目录
1 引言
各位朋友大家好,欢迎来到月来客栈。在前面的一篇文章[1]中笔者介绍了在单标签分类问题中模型损失的度量方法,即交叉熵损失函数。同时也介绍了多分类任务中常见的评价指标及其实现方法[2]。在接下来的这篇文章中,笔者将会详细介绍在多标签分类任务中两种常见的损失评估方法,以及在多标签分类场景中的模型评价指标。
2 方法一
将原始输出层的softmax操作替换为simoid操作,然后通过计算输出层与标签之间的sigmoid交叉熵来作为误差的衡量标准,具体计算公式如下:
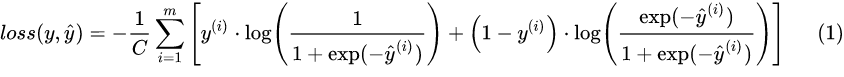
其中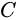 表示类别数量,
表示类别数量,![[公式]](https://img-blog.csdnimg.cn/783b46769e7442ac80a6192885ea50eb.png) 和
和![[公式]](https://img-blog.csdnimg.cn/2578d4771cdd4c9da010ff8f62aee9ed.png) 均为一个向量,分别用来表示真实标签和未经任何激活函数处理的网络输出值。
均为一个向量,分别用来表示真实标签和未经任何激活函数处理的网络输出值。
从式[1]可以发现,这种误差损失衡量方式其实就是在逻辑回归中用来衡量预测概率与真实标签之间误差的方法。
2.1 numpy实现
根据式[1]的计算公式,可以通过如下Python代码来完成损失值的计算:
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def compute_loss_v1(y_true, y_pred):
t_loss = y_true * np.log(sigmoid(y_pred)) + \
(1 - y_true) * np.log(1 - sigmoid(y_pred)) # [batch_size,num_class]
loss = t_loss.mean(axis=-1) # 得到每个样本的损失值, 这里可以是
return -loss.mean() # 返回整体样本的损失均值(或其他)
if __name__ == '__main__':
y_true = np.array([[1, 1, 0, 0], [0, 1, 0, 1]])
y_pred = np.array([[0.2, 0.5, 0, 0], [0.1, 0.5, 0, 0.8]])
print(compute_loss_v1(y_true, y_pred)) # 0.5926
当然,在TensorFlow 1.x和Pytorch中也分别对这两种方法进行了实现。
2.2 TensorFlow实现
在Tensorflow 1.x中,可以通过tf.nn模块下的sigmoid_cross_entropy_with_logits方法进行调用:
def sigmoid_cross_entropy_with_logits(labels, logits):
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits)
loss = tf.reduce_mean(loss, axis=-1)
return tf.reduce_mean(loss)
if __name__ == '__main__':
y_true = tf.constant([[1, 1, 0, 0], [0, 1, 0, 1]],dtype=tf.float16)
y_pred = tf.constant([[0.2, 0.5, 0, 0], [0.1, 0.5, 0, 0.8]],dtype=tf.float16)
with tf.Session() as sess:
loss = sess.run(sigmoid_cross_entropy_with_logits(y_true,y_pred))
print(loss) # 0.5926
当然,在模型训练完成后,可以通过如下代码来得到预测的标签结果和相应的概率值:
def prediction(logits, K):
y_pred = np.argsort(-logits, axis=-1)[:,:K]
print("预测标签:",y_pred)
p = np.vstack([logits[r,c] for r,c in enumerate(y_pred)])
print("预测概率:",p)
prediction(y_pred,2)
#####
预测标签:
[[1 0]
[3 1]]
预测概率:
[[0.5 0.2]
[0.8 0.5]]
2.3 Pytorch实现
在Pytorch中,可以通过torch.nn模块中的MultiLabelSoftMarginLoss类来完成损失的计算:
if __name__ == '__main__':
y_true = torch.tensor([[1, 1, 0, 0], [0, 1, 0, 1]],dtype=torch.int16)
y_pred = torch.tensor([[0.2, 0.5, 0, 0], [0.1, 0.5, 0, 0.8]],dtype=torch.float32)
loss = nn.MultiLabelSoftMarginLoss(reduction='mean')
print(loss(y_pred, y_true)) #0.5926
同样,在模型训练完成后也可以通过上面的prediction函数来完成推理预测。需要注意的是,在TensorFlow 1.x中sigmoid_cross_entropy_with_logits方法返回的是所有样本损失的均值;而在Pytorch中,MultiLabelSoftMarginLoss默认返回的是所有样本损失的均值,但是可以通过指定参数reduction为mean或sum来指定返回的类型。
3 方法二
在衡量多标签分类结果损失的方法中,除了上面介绍的方法一之外还有一种常用的损失函数。这种损失函数其实就是我们在单标签分类中用到的交叉熵损失函数的拓展版,单标签可以看作是其中的一种特例情况。其具体计算公式如下所示:
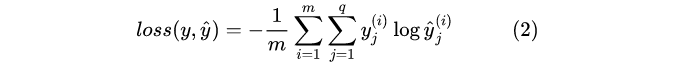
其中![[公式]](https://img-blog.csdnimg.cn/b983310cec4f46728f22de3a69e42f8c.png) 表示第i个样本第j个类别的真实值
表示第i个样本第j个类别的真实值![[公式]](https://img-blog.csdnimg.cn/7780a3d355944cd8ad7312f27f3f7979.png) 表示第i个样本第j个类别的输出经过softmax处理后的结果。例如对于如下样本来说:
表示第i个样本第j个类别的输出经过softmax处理后的结果。例如对于如下样本来说:
y_true = np.array([[1, 1, 0, 0], [0, 1, 0, 1.]])
y_pred = np.array([[0.2, 0.5, 0.1, 0], [0.1, 0.5, 0, 0.8]])
输出值经过softmax处理后的结果为:
[[0.24549354 0.33138161 0.22213174 0.20099311]
[0.18482871 0.27573204 0.16723993 0.37219932]]
那么,根据公式[2]可知,对于上述2个样本来说其损失值为:
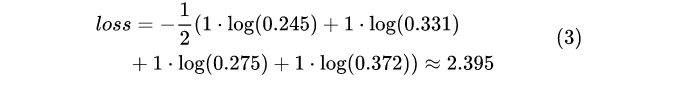
3.1 numpy实现
根据式[3]的计算公式,可以通过如下Python代码来完成损失值的计算:
def softmax(x):
s = np.exp(x)
return s / np.sum(s, axis=-1, keepdims=True)
def compute_loss_v2(logits, y):
logits = softmax(logits)
print(logits)
c = -(y * np.log(logits)).sum(axis=-1) # 计算每一个样本的在各个标签上的损失和
return np.mean(c) # 计算所有样本损失的平均值
y_true = np.array([[1, 1, 0, 0], [0, 1, 0, 1.]])
y_pred = np.array([[0.2, 0.5, 0.1, 0], [0.1, 0.5, 0, 0.8]])
print(compute_loss_v2(y_pred, y_true))# 2.392
3.2TensorFlow实现
在Tensorflow 1.x中,可以通过tf.nn模块下的softmax_cross_entropy_with_logits_v2方法进行调用:
def softmax_cross_entropy_with_logits(labels, logits):
loss = tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels, logits=logits)
return tf.reduce_mean(loss)
y_true = tf.constant([[1, 1, 0, 0], [0, 1, 0, 1.]], dtype=tf.float16)
y_pred = tf.constant([[0.2, 0.5, 0.1, 0], [0.1, 0.5, 0, 0.8]], dtype=tf.float16)
with tf.Session() as sess:
loss = sess.run(softmax_cross_entropy_with_logits(y_true, y_pred))
print(loss)# 2.395
3.3 Pytorch实现
在Pytorch中,笔者目前还没找到可以调用的相应模型,但是可以通过自己来编码实现:
def cross_entropy(logits, y):
s = torch.exp(logits)
logits = s / torch.sum(s, dim=1, keepdim=True)
c = -(y * torch.log(logits)).sum(dim=-1)
return torch.mean(c)
y_true = torch.tensor([[1, 1, 0, 0], [0, 1, 0, 1.]])
y_pred = torch.tensor([[0.2, 0.5, 0.1, 0], [0.1, 0.5, 0, 0.8]])
loss = cross_entropy(y_pred,y_true)
print(loss)# 2.392
需要注意的是,由于各个框架在计算时保留小数的策略不同,所以最后的结果在小数位后面会出现略微的差异。
4 评估指标
4.1 不考虑部分正确的评估方法
(1) 绝对匹配率(Exact Match Ratio)
所谓绝对匹配率指的就是,对于每一个样本来说,只有预测值与真实值完全相同的情况下才算预测正确,也就是说只要有一个类别的预测结果有差异都算没有预测正确。因此,其准确率计算公式为:
![[公式]](https://img-blog.csdnimg.cn/ef0b49b700b94e1d88dbdd6554525489.png)
其中n表示样本总数;![[公式]](https://img-blog.csdnimg.cn/deceb83fa71c46a2ad3430d3a874115c.png) 为指示函数(indicator function),当
为指示函数(indicator function),当![[公式]](https://img-blog.csdnimg.cn/ef285587900c482098c65fc408a70c79.png) 完全等同于
完全等同于![[公式]](https://img-blog.csdnimg.cn/5978d23c6c534f8ebdea557aaf2eab6b.png) 时取1,否则为0。可以看出,MR值越大,表示分类的准确率越高。
时取1,否则为0。可以看出,MR值越大,表示分类的准确率越高。
例如现有如下真实值和预测值:
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
那么其对应的MR就应该是0.333,因为只有第2个样本才算预测正确。在sklearn中,可以直接通过sklearn.metrics模块中的accuracy_score方法来完成计算[3],如下所示:
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true,y_pred)) # 0.33333333
(2)0-1损失
除了绝对匹配率之外,还有另外一种与之计算过程恰好相反的评估标准,即0-1损失(Zero-One Loss)。绝对准确率计算的是完全预测正确的样本占总样本数的比例,而0-1损失计算的是完全预测错误的样本占总样本的比例。因此对于上面的预测和真实结果,其0-1损失就应该为0.667。计算公式如下:
![[公式]](https://img-blog.csdnimg.cn/51757ee6095b43d394ea7439c1ed9d80.png)
在sklearn中,可以通过sklearn.metrics模块中的zero_one_loss方法来完成计算[3],如下所示:
from sklearn.metrics import zero_one_loss
print(zero_one_loss(y_true,y_pred))# 0.66666
4.2 考虑部分正确的评估方法
从上面的两种评估指标可以看出,不管是绝对匹配率还是0-1损失,两者在计算结果的时候都没有考虑到部分正确的情况,而这对于模型的评估来说显然是不准确的。例如,假设正确标签为[1,0,0,1],模型预测的标签为[1,0,1,0]。可以看到,尽管模型没有预测对全部的标签,但是预测对了一部分。因此,一种可取的做法就是将部分预测正确的结果也考虑进去[4]。为了实现这一想法,文献[5]中提出了在多标签分类场景下的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和[公式]值([公式]-Measure)计算方法。
(1)准确率
对于准确率来说,其计算公式为:
![[公式]](https://img-blog.csdnimg.cn/cf465e9142f54356a956db2803f147ed.png)
从公式[6]可以看出,准确率其实计算的是所有样本的平均准确率。而对于每个样本来说,准确率就是预测正确的标签数在整个预测为正确或真实为正确标签数中的占比。例如对于某个样本来说,其真实标签为[0, 1, 0, 1],预测标签为[0, 1, 1, 0]。那么该样本对应的准确率就应该为:
![[公式]](https://img-blog.csdnimg.cn/cabad4e062034ba0aebe56a7936d37ab.png)
因此,对于如下真实结果和预测结果来说:
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
其准确率为:
![[公式]](https://img-blog.csdnimg.cn/f76f95a2d0a345b5b1f925d1487d94de.png)
对应的实现代码为[6]:
def Accuracy(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
p = sum(np.logical_and(y_true[i], y_pred[i]))
q = sum(np.logical_or(y_true[i], y_pred[i]))
count += p / q
return count / y_true.shape[0]
print(Accuracy(y_true, y_pred)) # 0.52777
(2)精确率
对于精确率来说,其计算公式为:
![[公式]](https://img-blog.csdnimg.cn/dab1d75e946b4afaa4b71964c191c3a8.png)
从公式[9]可以看出,精确率其实计算的是所有样本的平均精确率。而对于每个样本来说,精确率就是预测正确的标签数在整个预测为正确的标签数中的占比。例如对于某个样本来说,其真实标签为[0, 1, 0, 1],预测标签为[0, 1, 1, 0]。那么该样本对应的精确率就应该为:
![[公式]](https://img-blog.csdnimg.cn/8982b9847799460c937c46f329a1014a.png)
因此,对于上面的真实结果和预测结果来说,其精确率为:
![[公式]](https://img-blog.csdnimg.cn/8c8299bc214a4e689dd0d9aff1bb92a1.png)
对应的实现代码为:
def Precision(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
if sum(y_pred[i]) == 0:
continue
count += sum(np.logical_and(y_true[i], y_pred[i])) / sum(y_pred[i])
return count / y_true.shape[0]
print(Precision(y_true, y_pred))# 0.6666
(3)召回率
对于召回率来说,其计算公式为:
![[公式]](https://img-blog.csdnimg.cn/e4344c42917c4f76979504e00bf29027.png)
从公式[12]可以看出,召回率其实计算的是所有样本的平均精确率。而对于每个样本来说,召回率就是预测正确的标签数在整个正确的标签数中的占比。
因此,对于如下真实结果和预测结果来说:
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
其召回率为:
![[公式]](https://img-blog.csdnimg.cn/676c2734eb994338bb9afed41deb54a4.png)
对应的实现代码为:
def Recall(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
if sum(y_true[i]) == 0:
continue
count += sum(np.logical_and(y_true[i], y_pred[i])) / sum(y_true[i])
return count / y_true.shape[0]
print(Recall(y_true, y_pred))# 0.6111
(4)![[公式]](https://img-blog.csdnimg.cn/2dc4c36b567949e195030efe3ad3f3b1.png) 值
值
对于![[公式]](https://img-blog.csdnimg.cn/9191dba55c244f3f8f87e3e7d4244e6f.png) 值来说,其计算公式为:
值来说,其计算公式为:
![[公式]](https://img-blog.csdnimg.cn/4ac15ef231174d40abd11bf0f7a5df2b.png)
从公式[14]可以看出,![[公式]](https://img-blog.csdnimg.cn/5f92b933a6c44ff582935c77918c5507.png) 计算的也是所有样本的平均精确率。因此,对于上面的真实结果和预测结果来说,其
计算的也是所有样本的平均精确率。因此,对于上面的真实结果和预测结果来说,其![[公式]](https://img-blog.csdnimg.cn/5e06637154604f6f81b6563c9c9fbdbc.png) 值为:
值为:
![[公式]](https://img-blog.csdnimg.cn/b0d978f0d98840b6801114db66699ca4.png)
对应的实现代码为:
def F1Measure(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
if (sum(y_true[i]) == 0) and (sum(y_pred[i]) == 0):
continue
p = sum(np.logical_and(y_true[i], y_pred[i]))
q = sum(y_true[i]) + sum(y_pred[i])
count += (2 * p) / q
return count / y_true.shape[0]
print(F1Measure(y_true, y_pred))# 0.6333
在上述4项指标中,都是值越大,对应模型的分类效果越好。同时,从公式[6][9][12][14]可以看出,多标签场景下的各项指标尽管在计算步骤上与单标签场景有所区别,但是两者在计算各个指标时所秉承的思想却是类似的。
当然,对于后面3个指标的计算,还可以直接通过sklearn来完成,代码如下:
from sklearn.metrics import precision_score, recall_score, f1_score
print(precision_score(y_true=y_true, y_pred=y_pred, average='samples'))# 0.6666
print(recall_score(y_true=y_true, y_pred=y_pred, average='samples'))# 0.6111
print(f1_score(y_true,y_pred,average='samples'))# 0.6333
(5)Hamming Loss
除了前面已经介绍的6中评估方法外,下面再介绍另外一种更加直观的衡量方法Hamming Loss[3],它的计算公式为:
![[公式]](https://img-blog.csdnimg.cn/f536b5949382432fa5d47db531aca8da.png)
其中![[公式]](https://img-blog.csdnimg.cn/37a0bf0fb1c14b2d8f84d007f9b2b832.png) 表示第i个样本的第j个标签,q表示一种有多少个类别。
表示第i个样本的第j个标签,q表示一种有多少个类别。
从公式[16]可以看出,Hamming Loss衡量的是所有样本中,预测错的标签数在整个标签标签数中的占比。所以对于Hamming Loss损失来说,其值越小表示模型的表现结果越好。因此,对于如下真实结果和预测结果来说:
y_true = np.array([[0, 1, 0, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]])
y_pred = np.array([[0, 1, 1, 0],
[0, 1, 1, 0],
[0, 1, 0, 1]])
其Hamming Loss为:
![[公式]](https://img-blog.csdnimg.cn/5550a4fef5de4af290c58e4dcb48c784.png)
对应的实现代码为:
def Hamming_Loss(y_true, y_pred):
count = 0
for i in range(y_true.shape[0]):
p = np.size(y_true[i] == y_pred[i])
q = np.count_nonzero(y_true[i] == y_pred[i])
count += p - q
return count / (y_true.shape[0] * y_true.shape[3])
print(Hamming_Loss(y_true, y_pred))# 0.4166
同时也可以通过sklearn.metrics中的hamming_loss方法来实现:
from sklearn.metrics import hamming_loss
print(hamming_loss(y_true, y_pred))# 0.4166
当然,尽管这里介绍了7种不同的评价指标,但是在多标签分类中仍旧还有其它不同的评估方法,具体可以参见文件[4]。例如还可以通过sklearn.metric模块中的multilabel_confusion_matrix方法来分别计算多标签中每个类别的准确率、召回率等;最后再来求每个类别各项指标的平均值。
5 总结
在这篇文章中,笔者首先介绍了第一种在多标签分类任务中常见的损失度量方法,其实本质上它就是逻辑回归模型的目标函数;接着笔者介绍了多种用于评估多标签分类任务结果的评价指标,包括绝对匹配率、准确率、召回率等等;最后笔者还是介绍了另外一种常见的多标签分类任务中的损失函数。
引用
[1] 想明白多分类,必须得谈逻辑回归
[2] 多分类任务下的召回率与F值
[3] Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[4] Sorower, Mohammad S… “A Literature Survey on Algorithms for Multi-label Learning.” (2010).
[5] Godbole, S., & Sarawagi, S. Discriminative Methods for Multi-labeled Classification. Lecture Notes in Computer Science,(2004), 22–30.
[6] https://mmuratarat.github.io/20…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号