

详解多级目标检测体系结构Cascade RCNN
0. 前言
这篇文章是自己阅读多篇大佬的文章后进行融合整理所得,尽量把Cascade RCNN每一部分讲解清楚,可根据自己掌握情况选择性阅读,引用文章的链接也会在文末给出。
0.1 简易版理解
随着box回归带来proposal质量提高的同时(也就是IoU提高了),提高训练时检测器的IoU阈值,让他们保持相近,从而训练多个级联的检测器。
1. 简单回顾R-CNN结构
图片引用自该链接
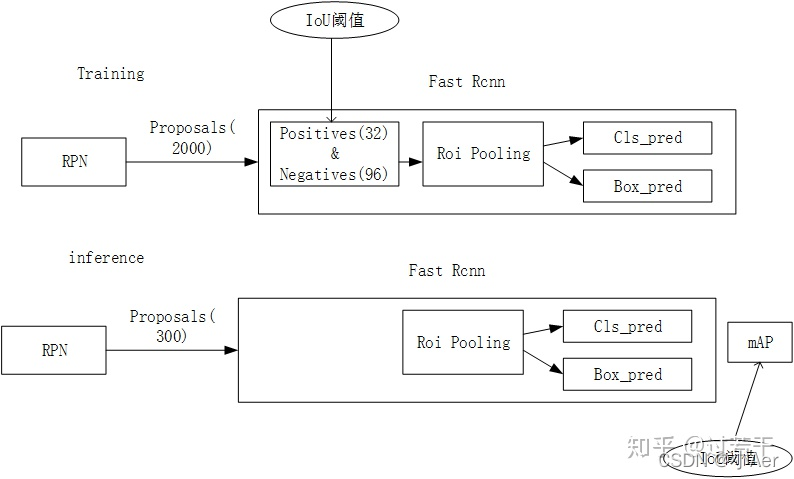
首先,以经典的Faster R-CNN为例。整个网络可以分为两个阶段,training阶段和inference阶段,如上图所示。
- training阶段,RPN网络提出了2000左右的proposals,这些proposals被送入到Fast R-CNN结构中,在Fast R-CNN结构中,首先计算每个proposal和gt之间的iou,通过人为的设定一个IoU阈值(通常为0.5),把这些Proposals分为正样本(前景)和负样本(背景),并对这些正负样本采样,使得他们之间的比例尽量满足(1:3,二者总数量通常为128),之后这些proposals(128个)被送入到Roi Pooling,最后进行类别分类和box回归。
- inference阶段,RPN网络提出了300左右的proposals,这些proposals被送入到Fast R-CNN结构中,和training阶段不同的是,inference阶段没有办法对这些proposals采样(inference阶段肯定不知道gt的,也就没法计算iou),所以他们直接进入Roi Pooling,之后进行类别分类和box回归。
在这里插一句,在R-CNN中用到IoU阈值的有两个地方,分别是Training时Positive与Negative判定,和Inference时计算mAP。论文中强调的IoU阈值指的是Training时Positive和Negative判定处。
上面提到了RPN 和 Roi Pooling,下面重点讲解一下这两个网络
1.1 RPN网络[4]
RPN全称是Region Proposal Network,Region Proposal的中文意思是“区域选取”,也就是“提取候选框”的意思,所以RPN就是用来提取候选框的网络。
1.1.1. RPN的意义
RPN第一次出现在世人眼中是在Faster RCNN这个结构中,专门用来提取候选框,在RCNN和Fast RCNN等物体检测架构中,用来提取候选框的方法通常是Selective Search[6][7],是比较传统的方法,而且比较耗时,在CPU上要2s一张图。所以作者提出RPN,专门用来提取候选框,一方面RPN耗时少,另一方面RPN可以很容易结合到Fast RCNN中,称为一个整体。
RPN的引入,可以说是真正意义上把物体检测整个流程融入到一个神经网络中,这个网络结构叫做Faster RCNN; Faster RCNN = RPN + Fast RCNN
下面使用Faster RCNN的图讲解RPN
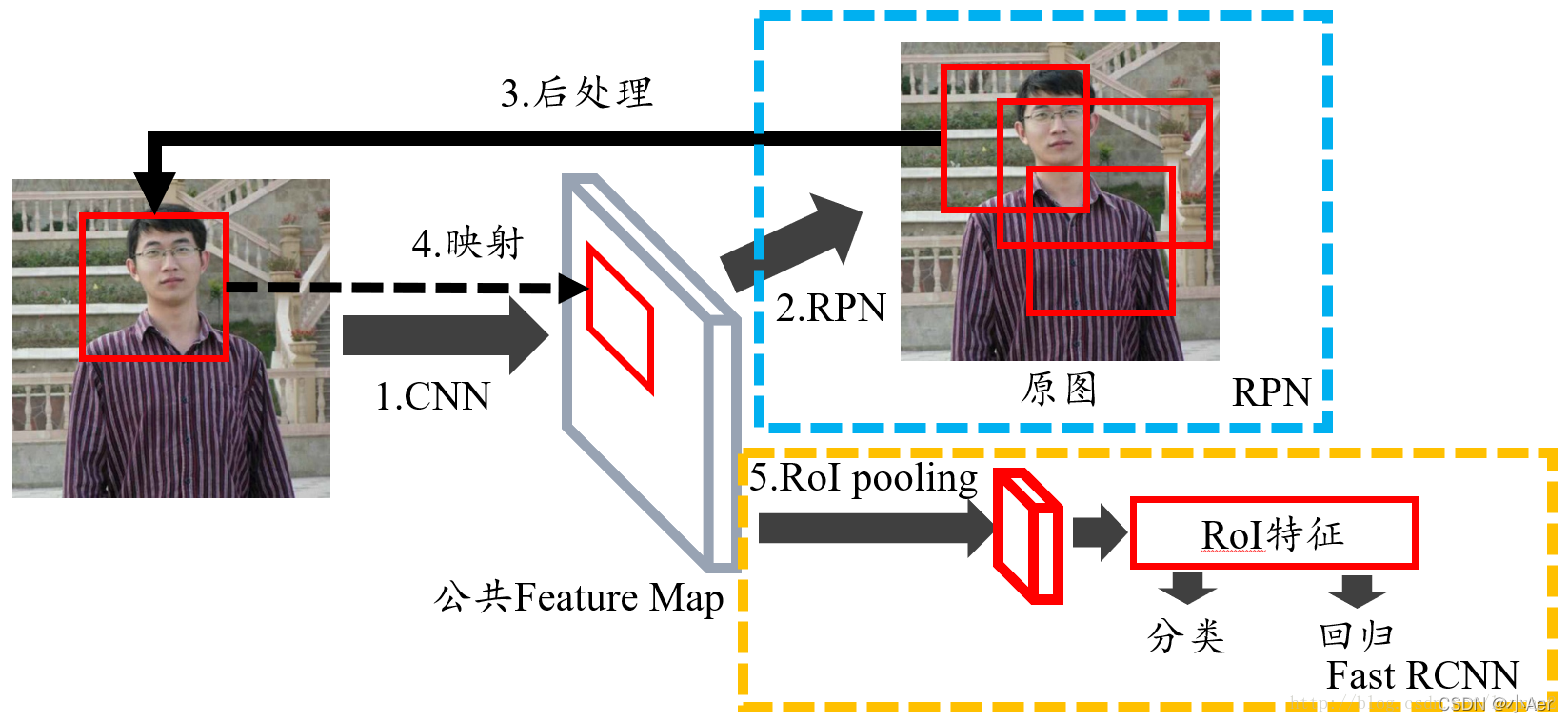
图1 Faster RCNN的整体结构
1.1.2. RPN的运作机制
我们先来看看Faster RCNN原文中的图:
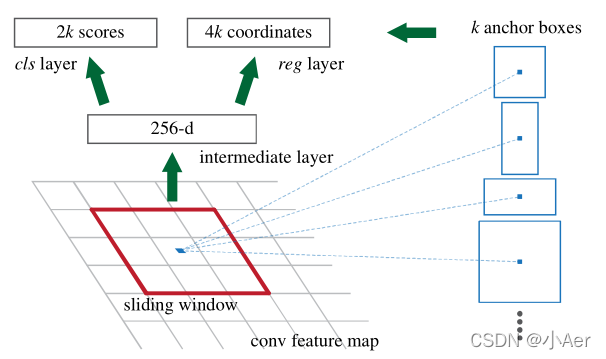
图2 RPN的结构
图2展示了RPN的整个过程,一个特征图经过sliding window处理,得到256维特征,然后通过两次全连接得到结果2k个分数和4k个坐标;相信大家一定有很多不懂的地方;我把相关的问题一一列举:
1.RPN的input 特征图指的是哪个特征图?
2.为什么是用sliding window?文中不是说用CNN么?
3.256维特征向量如何获得的?
4.2k和4k中的k指的是什么?
5.图右侧不同形状的矩形和Anchors又是如何得到的?
-
首先回答第一个问题,RPN的输入特征图就是图1中Faster RCNN的公共Feature Map,也称共享Feature Map,主要用以RPN和RoI Pooling共享;
-
对于第二个问题,我们可以把3x3的sliding window看作是对特征图做了一次3x3的卷积操作,最后得到了一个channel数目是256的特征图,尺寸和公共特征图相同,我们假设是256 x (H x W);
-
对于第三个问题,我们可以近似的把这个特征图看作有H x W个向量,每个向量是256维,那么图中的256维指的就是其中一个向量,然后我们要对每个特征向量做两次全连接操作,一个得到2个分数,一个得到4个坐标,由于我们要对每个向量做同样的全连接操作,等同于对整个特征图做两次1 x 1的卷积,得到一个2 x H x W和一个4 x H x W大小的特征图,换句话说,有H x W个结果,每个结果包含2个分数和4个坐标;
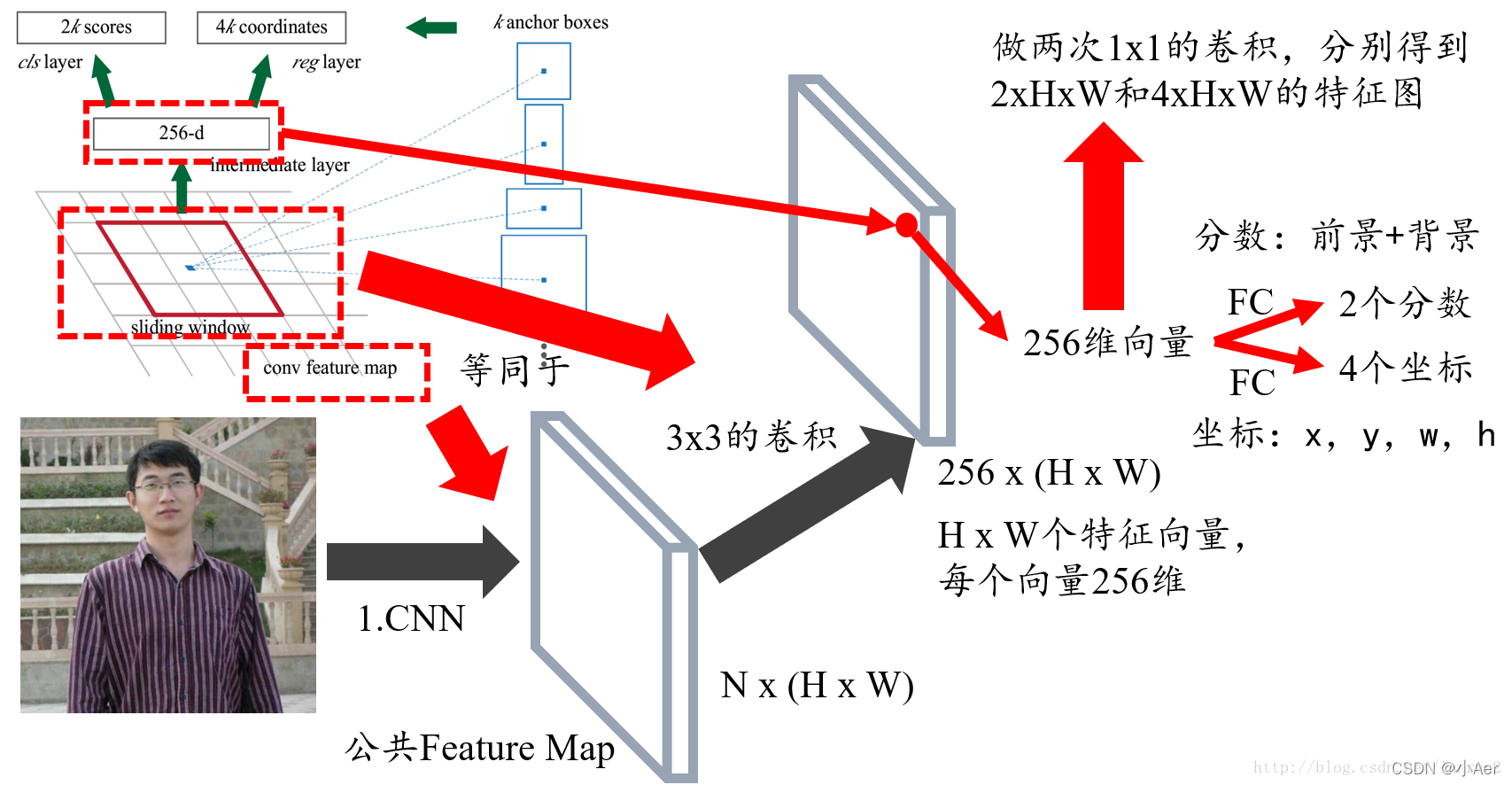
图3 问题1,2,3的解答描述图
这里我们需要解释一下为何是2个分数,因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,那么就有两个分数,前景(物体)的分数,和背景的分数;
我们还需要注意:4个坐标是指针对原图坐标的偏移,首先一定要记住是原图;
此时读者肯定有疑问,原图哪里来的坐标呢?
这里我要解答最后两个问题了:
4. 首先我们知道有H x W个结果,我们随机取一点,它跟原图肯定是有个一一映射关系的,由于原图和特征图大小不同,所以特征图上的一个点对应原图肯定是一个框,然而这个框很小,比如说8 x 8,这里8是指原图和特征图的比例,所以这个并不是我们想要的框,那我们不妨把框的左上角或者框的中心作为锚点(Anchor),然后想象出一堆框,具体多少,聪明的读者肯定已经猜到,K个,这也就是图中所说的K anchor boxes(由锚点产生的K个框);换句话说,H x W个点,每个点对应原图有K个框,那么就有H x W x k个框默默的在原图上,那RPN的结果其实就是判断这些框是不是物体以及他们的偏移;
5. 那么K个框到底有多大,长宽比是多少?这里是预先设定好的,共有9种组合,所以k等于9,最后我们的结果是针对这9种组合的,所以有H x W x 9个结果,也就是18个分数和36个坐标;
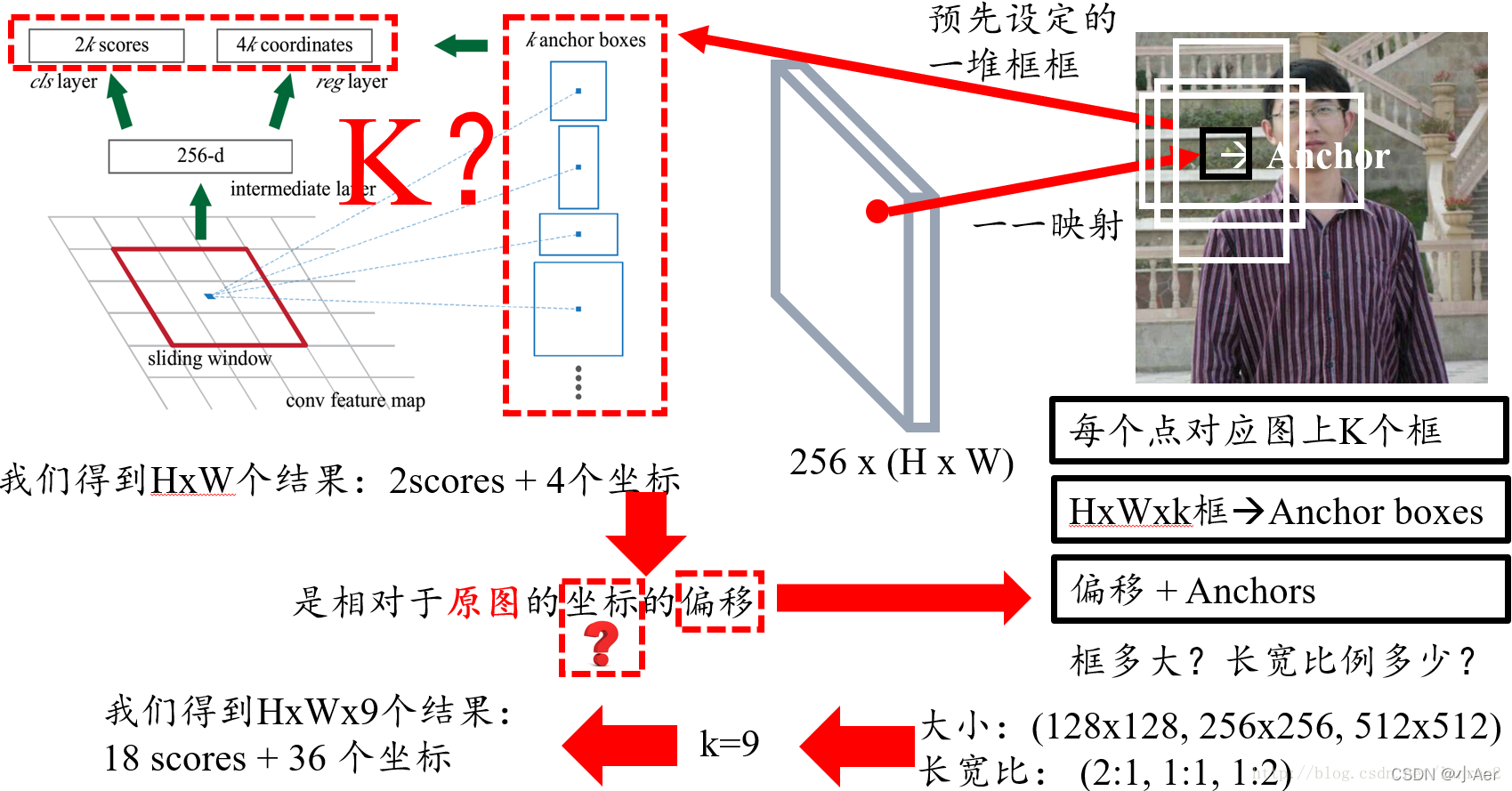
图4 问题4,5的解答描述图
1.1.3 3. RPN的整个流程回顾
最后我们再把RPN整个流程走一遍,首先通过一系列卷积得到公共特征图,假设他的大小是N x 16 x 16,然后我们进入RPN阶段,首先经过一个3 x 3的卷积,得到一个256 x 16 x 16的特征图,也可以看作16 x 16个256维特征向量,然后经过两次1 x 1的卷积,分别得到一个18 x 16 x 16的特征图,和一个36 x 16 x 16的特征图,也就是16 x 16 x 9个结果,每个结果包含2个分数和4个坐标,再结合预先定义的Anchors,经过后处理,就得到候选框;整个流程如图5:
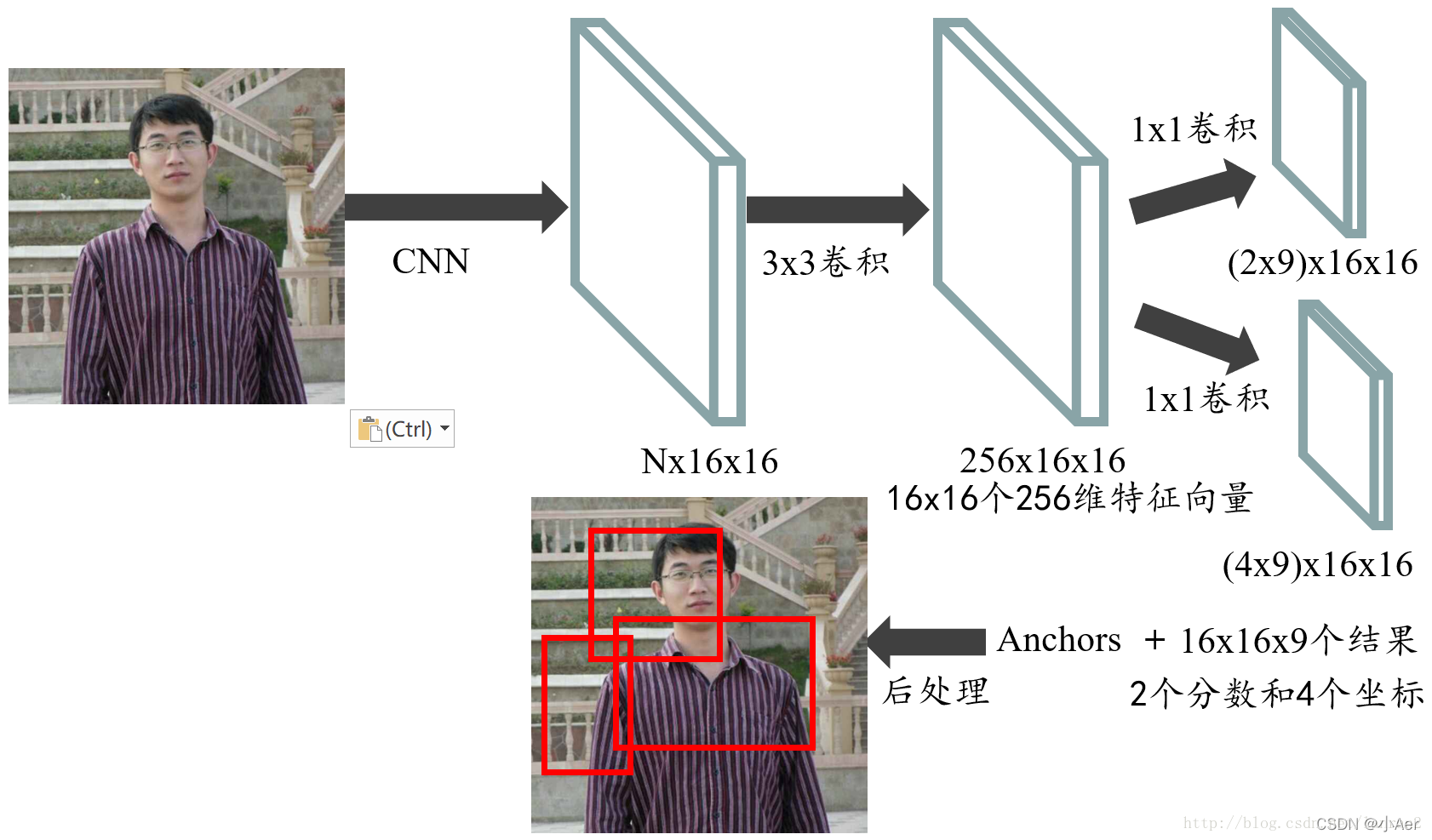
图5 RPN整个流程
1.2 Roi Pooling[5]
1.2.1 ROI Pooling的意义
ROIs Pooling顾名思义,是Pooling层的一种,而且是针对RoIs的Pooling,他的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定;
什么是ROI呢?
ROI是Region of Interest的简写,指的是在“特征图上的框”;
1)在Fast RCNN中, RoI是指Selective Search完成后得到的“候选框”在特征图上的映射,如下图所示;
2)在Faster RCNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs。
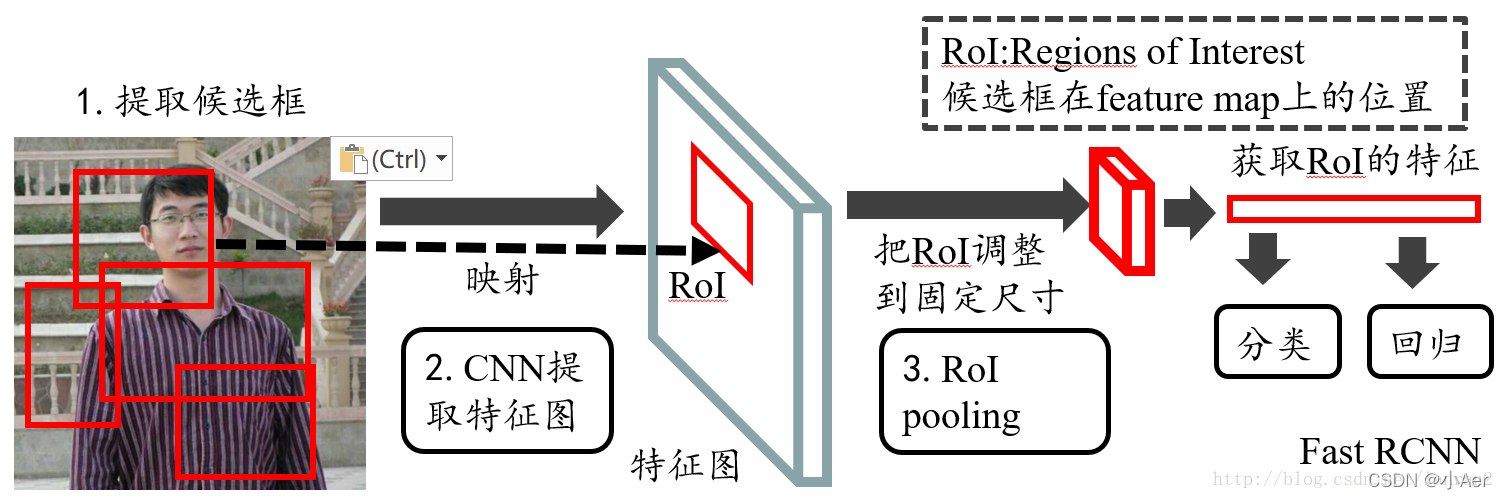
图1 Fast RCNN整体结构
往往经过rpn后输出的不止一个矩形框,所以这里我们是对多个ROI进行Pooling。
1.2.2 ROI Pooling的输入
输入有两部分组成:
- 特征图:指的是图1中所示的特征图,在Fast RCNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;
- rois:在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
1.2.3 ROI Pooling的输出
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框;
1.2.4 ROI Pooling的过程
如图所示,我们先把roi中的坐标映射到feature map上,映射规则比较简单,就是把各个坐标除以“输入图片与feature map的大小的比值”,得到了feature map上的box坐标后,我们使用Pooling得到输出;由于输入的图片大小不一,所以这里我们使用的类似Spp Pooling,在Pooling的过程中需要计算Pooling后的结果对应到feature map上所占的范围,然后在那个范围中进行取max或者取average。
2. 解释mismatch问题
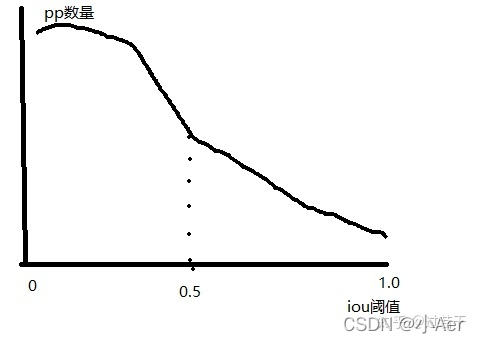
一张图说明问题,在上面这张图中,把RPN提出的Proposals的大致分布画了下,横轴表示Proposals和gt之间的iou值,纵轴表示满足当前iou值的Proposals数量。
- 在training阶段,由于我们知道gt,所以可以很自然的把与gt的iou大于threshold(0.5)的Proposals作为正样本,这些正样本参与之后的bbox回归学习。
- 在inference阶段,由于我们不知道gt,所以只能把所有的proposal都当做正样本,让后面的bbox回归器回归坐标。
我们可以明显的看到training阶段和inference阶段,bbox回归器的输入分布是不一样的,training阶段的输入proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU<threshold的),这就是论文中提到mismatch问题,这个问题是固有存在的,通常threshold取0.5时,mismatch问题还不会很严重。
detector通常在proposal自身的IOU值与detector训练的IOU阈值较为接近的时候才会有更好的结果,如果二者差异较大那么很难产生良好的检测效果
3. 对文章中的实验分析
3.1 单纯提高IoU阈值带来的问题
提高检测的精确度,换句话说就是产生更高精度的box,那么我们可以提高产生正样本的IoU阈值,这样后面的detector接收到了更高精度的proposals,自然能产生高精度box。但是这样就会产生两个问题:
- 过拟合问题。提高了IoU阈值,满足这个阈值条件的proposals必然比之前少了,容易导致过拟合。
- 更严重的mismatch问题。前面我们说到,R-CNN结构本身就有这个问题,IoU阈值再提的更高,这个问题就更加严重。
上面的两个问题都会导致性能的下降,论文作者做了下面的的实验,证明问题确实存在。
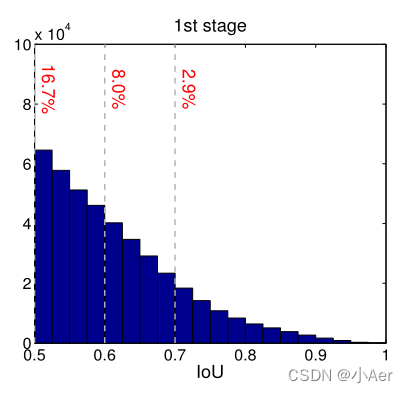
上图中表示RPN的输出proposal在各个IoU范围内的数量。可以看到,IoU在0.6,0.7以上的proposals数量很少,直接提高IoU阈值,确实有可能出现上述两个问题。
接着,论文作者继续用实验说话,做了3组实验,分别表示IoU阈值取0.5,0.6,0.7时,proposals的分布与检测精度。
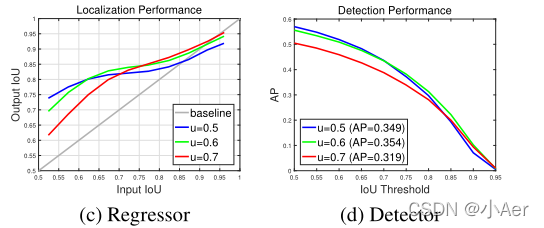
( c )图中横轴表示RPN的输出proposal的IoU,纵轴表示proposal经过box reg的新的IoU。可以得出以下结论:
- 一个检测器通常只在一个小范围的IOU阈值内(a single quality level)性能最好,从上图中可以发现,在0.55-0.6的范围内阈值为0.5的detector性能最好,在0.6~0.75阈值为0.6的detector性能最佳,而到了0.75之后就是阈值为0.7的detector了,比IOU阈值过高过低的proposal都会导致检测器性能下降,因此保证检测器训练时的IOU阈值与输入proposal 的IOU相近是十分重要并且有必要的,否则就会出现前文所说的mismatch的情况,这种由很多的实验证明,并没有严格的理论证明。
- 通过观察上图可以发现,几乎所有检测器输出的检测框的IOU都好于输入proposal的IOU(曲线几乎都在灰色对角线之上),因此这保证了我们通过一个检测器输出的检测框整体IOU相对输入的proposal的IOU都会提高,可以作为下一个使用更高IOU阈值训练检测器一个很好的数据输入。因此每个检测器输出的检测框质量都会变高,阈值的提高其实也相当于一个resample的过程,一些异常值也可以去掉,提高了模型的鲁棒性。
( d )图中横轴表示inference阶段,判定box为TP的IoU阈值,纵轴为mAP。可以看到IoU阈值从0.5提到0.7时,精度AP下降很多。
3.2 Cascade结构与相似的结构对比
既然单一一个阈值训练出的检测器效果有限,作者就提出了muti-stage的结构,每个stage都有一个不同的IoU阈值。如下图(d):
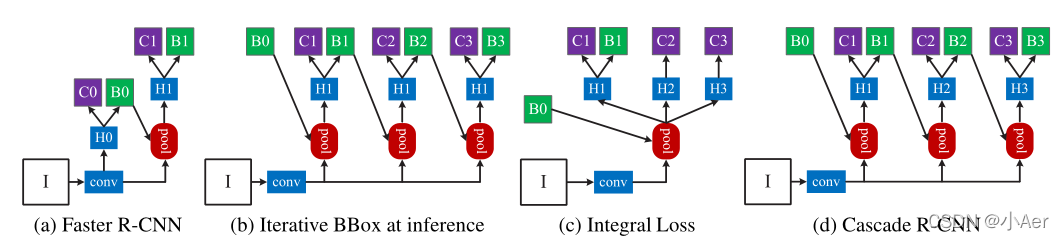
可以看到不止作者一个人想到过muti-stage的结构(图b,c),作者讨论了cascade结构和另外两种结构的不同之处,以及为什么cascade结构更优秀。
3.2.1 和Iterative BBox比较
Iterative BBox的H位置都是共享的,而且3个分支的IoU阈值都取0.5。Iterative BBox存在的问题:
我们已经知道单一阈值0.5,是无法对所有proposal取得良好效果的。
此外,detector会改变样本的分布,这时候再使用同一个共享的H对检测肯定是有影响的。作者做了下面的实验证明样本分布在各个stage的变化。
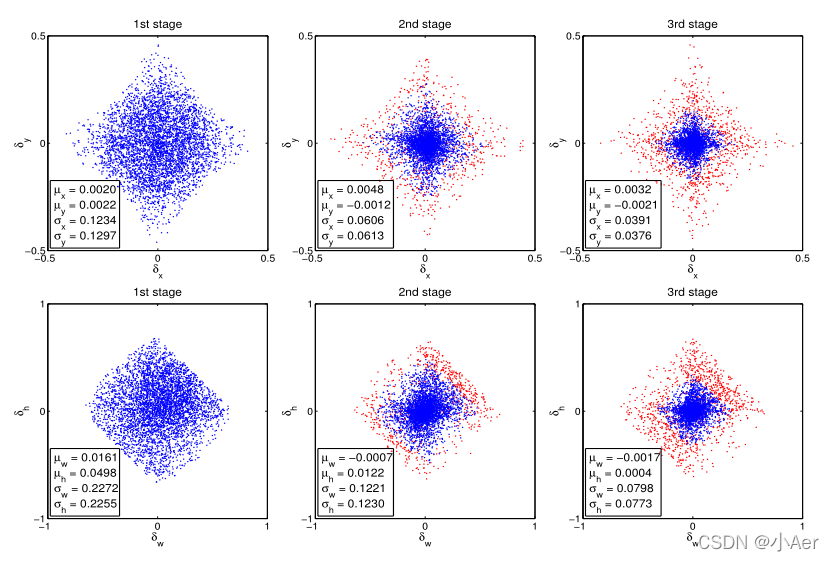
- 可以看到每经过一次回归,样本都更靠近gt一些,质量也就更高一些,样本的分布也在逐渐变化。如果还是用0.5的阈值,在后面两个stage就会有较多离群点,使用共享的H也无法满足detector的输入的变化。
从上面这个图也可以看出,每个阶段cascade都有不同的IoU阈值,可以更好地去除离群点,适应新的proposal分布。
3.2.2 和Integral Loss比较
Integral Loss共用pooling,只有一个stage,但有3个不共享的H,每个H处都对应不同的IoU阈值。Integral Loss存在的问题:
- 我们从下面的proposal分布可以看到,第一个stage的输入IoU的分布很不均匀,高阈值proposals数量很少,导致负责高阈值的detector很容易过拟合。
- 此外在inference时,3个detector的结果要进行ensemble,但是它们的输入的IoU大部分都比较低,这时高阈值的detector也需要处理低IoU的proposals,它就存在较严重的mismatch问题,它的detector效果就很差了。
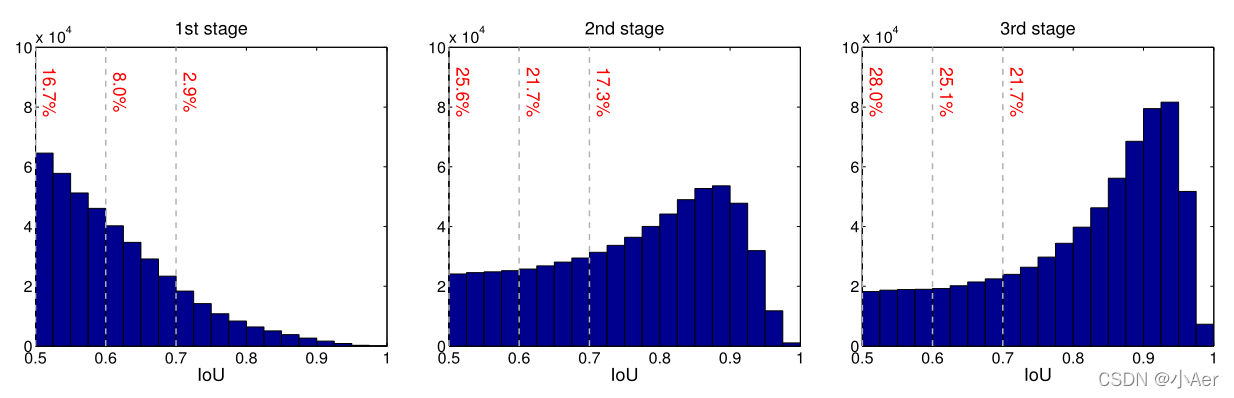
- 从上面这个图也可以看出,每个阶段cascade都有足够的样本,不会容易过拟合。
4. 实验细节
总的来说,Cascade R-CNN有四个阶段,一个RPN和三个用于检测U={0.5,0.6,0.7},除非另有说明。在以下阶段,只需使用前一阶段的回归输出即可实现重采样。除标准水平图像翻转外,未使用数据增强。推理是在一个单一的图像尺度上进行的。
- 级联结构公式

其中T是级联级的总数。请注意,级联中的每个回归因子ft都是经过优化的w.r.t.样本分布{bt}到达相应阶段,而不是{b1}的初始分布。这种级联逐步改进了初始假设
- 损失函数[8]
关于损失函数,跟Faster R-CNN基本一致,没有什么变化。分类采用softmax,回归采用smooth L1 loss,并且为了防止由于bounding box的大小以及位置带来的回归尺度的影响,我们一般会对box的坐标进行归一化操作,即:


softmax公式:

smooth L1 loss(采用该Loss的模型(Faster RCNN,SSD,,)):
SmoothL1 Loss是在Fast RCNN论文中提出来的,依据论文的解释,是因为smooth L1 loss让loss对于离群点更加鲁棒,即:相比于L2 Loss,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
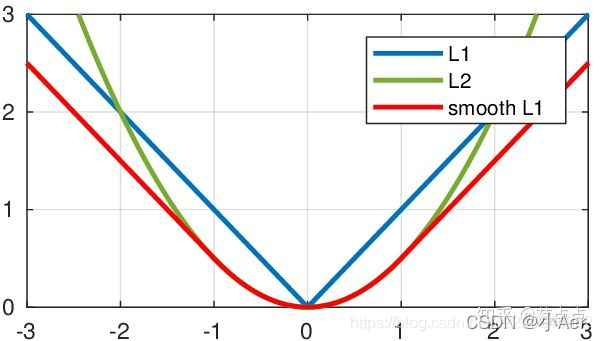
假设x是预测框与 groud truth 之间 elementwise 的差异,那么对比L1/L2/SmoothL1 Loss如下:

对应的曲线图如下:
对三个loss的x求导得到:
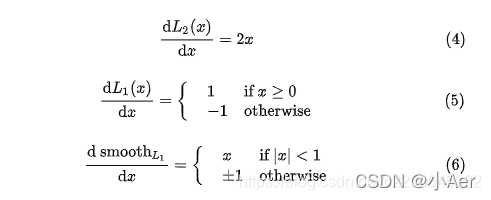
由(4)可以看到,当x值很大,即遇到的是离群点,异常值时,导数很大。所以在训练初期,预测值与 groud truth 差异过于大时,L2 Loss对预测值的梯度十分大,训练不稳定。
由(5)知道,L1 Loss的导数是常数,那么在训练后期,当预测值与 ground truth 差异很小时, L1 Loss 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
而(6)可以看出,smooth L1在 x 较小时,对x 的梯度也会变小,而在 x 很大时,对 x 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 smooth L1完美地避开了 L1 loss 和 L2 loss 损失的缺陷。
缺点:
- 上面的三种Loss用于计算目标检测的Bounding Box Loss时,独立的求出4个点的Loss,然后进行相加得到最终的Bounding Box Loss,这种做法的假设是4个点是相互独立的,实际是有一定相关性的
- 实际评价框检测的指标是使用IOU,这两者是不等价的,多个检测框可能有相同大小的smooth L1 Loss,但IOU可能差异很大,为了解决这个问题就引入了IOU LOSS。
5. 总结
RPN提出的proposals大部分质量不高,导致没办法直接使用高阈值的detector,Cascade R-CNN使用cascade回归作为一种重采样的机制,逐stage提高proposal的IoU值,从而使得前一个stage重新采样过的proposals能够适应下一个有更高阈值的stage。(通过增加IoU阈值,可以顺序删除一些异常值,从而实现经过更好训练的专用检测器序列)
- 每一个stage的detector都不会过拟合,都有足够满足阈值条件的样本。
- 更深层的detector也就可以优化更大阈值的proposals。
- 每个stage的H不相同,意味着可以适应多级的分布。
- 在inference时,虽然最开始RPN提出的proposals质量依然不高,但在每经过一个stage后质量都会提高,从而和有更高IoU阈值的detector之间不会有很严重的mismatch。
6. 引用
[1] https://zhuanlan.zhihu.com/p/42553957
[2] https://zhuanlan.zhihu.com/p/161530664
[3] https://zhuanlan.zhihu.com/p/89421243
[4] https://blog.csdn.net/tony_vip/article/details/108827910
[5] https://blog.csdn.net/lanran2/article/details/60143861
[6] https://zhuanlan.zhihu.com/p/27467369
[7] https://zhuanlan.zhihu.com/p/39927488
[8] https://blog.csdn.net/c2250645962/article/details/106023381


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!