KNN与K-means的区别
整篇文章整合多人文章,并且加上自己的一些理解创作
文章目录
1. KNN(K-Nearest Neighbor)介绍
KNN是一种常用的监督学习办法,其工作机制十分简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。通常,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果;在回归任务中可使用“平均法”,即将这k个样本的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
下面给出个示例比较方便理解:
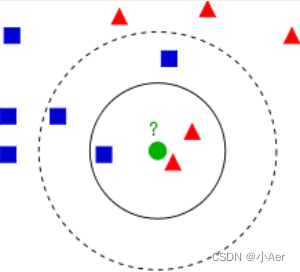
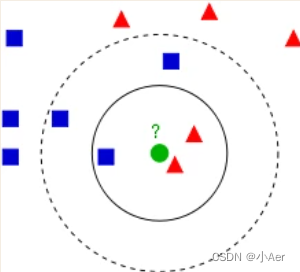
KNN的算法过程是是这样的:
-
从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
-
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
-
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。
总结:KNN是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。
具体是每次来一个未知的样本点,就在附近找K个最近的点进行投票。
1.1 优点
- 简单易用。相比其他算法,KNN 算是比较简洁明了的算法,即使没有很高的数学基础也能搞清楚它的原理。
- 模型训练时间快,上面说到 KNN 算法是惰性的,这里也就不再过多讲述。
- 预测效果好。
- 对异常值不敏感。
1.2 缺点
- 对内存要求较高,因为该算法存储了所有训练数据。
- 预测阶段可能很慢。
- 对不相关的功能和数据规模敏感。
1.3 skelearn库代码实现
查看具体数据集可移步另外我的一篇文章
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 使用鸢尾花数据集
iris = load_iris()
x = iris.data[:, :4]
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
clf = KNeighborsClassifier()
clf.fit(x_train, y_train)
print(clf.score(x_train, y_train))
print(clf.score(x_test, y_test))
1.4 手动实现KNN算法
import numpy as np
import operator as op
def create_data_set():
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify0(inx, dateset, labels, k):
"""
inx: 待分类向量
dataset: 训练样本集
labels: 标签向量
k: 选择最近邻居的数目
"""
# 计算欧式距离
datesetsize = dateset.shape[0]
diffmat = np.tile(inx, (datesetsize, 1)) - dateset
sqdiffmat = diffmat**2
# sum 默认axis=0,而要对矩阵每一行向量进行相加,就要设置axis=1
sqdistances = sqdiffmat.sum(axis=1)
distances = sqdistances**0.5
# argsort函数作用是将x从小到大排序,提取相应的索引,输出到y
sortsqDistances = distances.argsort()
classCount = {}
for i in range(k):
votelabel = labels[sortsqDistances[i]]
classCount[votelabel] = classCount.get(votelabel, 0) + 1
# 降序排序
sortedclassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True)
# 取k个点中出现频率最高的类别作为当前点的预测分类
return sortedclassCount[0][0]
if __name__ == '__main__':
group, labels = create_data_set()
flag = classify0([1.0, 1.0], group, labels, 3)
print(flag)
小提示
1.np.tile:diffmat = np.tile(inx, (datesetsize, 1)) - dateset
目的就是为了让inx向量可以与dataset进行矩阵的相减
>>> b = np.array([[1, 2], [3, 4]])
>>> np.tile(b, 2) #沿X轴复制2倍
array([[1, 2, 1, 2],
[3, 4, 3, 4]])
>>> np.tile(b, (2, 1))#沿X轴复制1倍(相当于没有复制),再沿Y轴复制2倍
array([[1, 2],
[3, 4],
[1, 2],
[3, 4]])
2.classCount.get(votelabel, 0)
python中字典的get()函数的作用
2. K-Means介绍
K-means 是我们最常用的基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大。
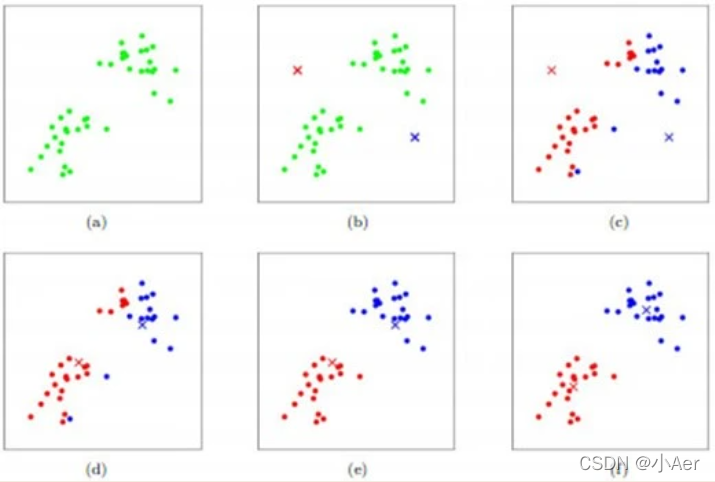
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。
- a刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。
- b假设数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两个类的中心点。
- (c-f)演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为止。
(图文来自Andrew ng的机器学习公开课)。
2.1 优点
- 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
- 处理大数据集的时候,该算法可以保证较好的伸缩性;
- 当簇近似高斯分布的时候,效果非常不错;
2.2 缺点
- 算法复杂度高
- K 值需要人为设定,不同 K 值得到的结果不一样;
- 对初始的簇中心敏感,不同选取方式会得到不同结果;
- 对异常值敏感;
- 样本只能归为一类,不适合多分类任务;
- 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
- 容易出现局部最优
聚类问题分为“硬聚类”和“软聚类”。硬聚类表示样本只能属于一个类别,软聚类表示样本可以以概率属于多个类别。k-means是属于硬聚类。
2.4 skelearn库代码实现
# 1.加载数据集
import numpy as np
from sklearn.datasets import load_digits
data, labels = load_digits(return_X_y=True)
(n_samples, n_features), n_digits = data.shape, np.unique(labels).size
print(f"# digits: {n_digits}; # samples: {n_samples}; # features {n_features}")
# digits: 10; # samples: 1797; # features 64
# 2.定义评估标准(引用自skelearn,作用就是整理输出格式)
from time import time
from sklearn import metrics
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
def bench_k_means(kmeans, name, data, labels):
"""Benchmark to evaluate the KMeans initialization methods.
Parameters
----------
kmeans : KMeans instance
A :class:`~sklearn.cluster.KMeans` instance with the initialization
already set.
name : str
Name given to the strategy. It will be used to show the results in a
table.
data : ndarray of shape (n_samples, n_features)
The data to cluster.
labels : ndarray of shape (n_samples,)
The labels used to compute the clustering metrics which requires some
supervision.
"""
t0 = time()
estimator = make_pipeline(StandardScaler(), kmeans).fit(data)
fit_time = time() - t0
results = [name, fit_time, estimator[-1].inertia_]
# Define the metrics which require only the true labels and estimator
# labels
clustering_metrics = [
metrics.homogeneity_score,
metrics.completeness_score,
metrics.v_measure_score,
metrics.adjusted_rand_score,
metrics.adjusted_mutual_info_score,
]
results += [m(labels, estimator[-1].labels_) for m in clustering_metrics]
# The silhouette score requires the full dataset
results += [
metrics.silhouette_score(
data,
estimator[-1].labels_,
metric="euclidean",
sample_size=300,
)
]
# Show the results
formatter_result = (
"{:9s}\t{:.3f}s\t{:.0f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}\t{:.3f}"
)
print(formatter_result.format(*results))
# 3.运行测试(有三种方法的KMeans,核心代码)
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
print(82 * "_")
print("init\t\ttime\tinertia\thomo\tcompl\tv-meas\tARI\tAMI\tsilhouette")
# 使用 kmeans++ 进行初始化。该方法是随机的,我们将运行初始化 4 次;
kmeans = KMeans(init="k-means++", n_clusters=n_digits, n_init=4, random_state=0)
bench_k_means(kmeans=kmeans, name="k-means++", data=data, labels=labels)
# 随机初始化。这个方法也是随机的,我们将运行初始化 4 次;
kmeans = KMeans(init="random", n_clusters=n_digits, n_init=4, random_state=0)
bench_k_means(kmeans=kmeans, name="random", data=data, labels=labels)
# 基于 PCA 投影的初始化。实际上,我们将使用 PCA 的组件来初始化 KMeans。这种方法是确定性的,一次初始化就足够了。
pca = PCA(n_components=n_digits).fit(data)
kmeans = KMeans(init=pca.components_, n_clusters=n_digits, n_init=1)
bench_k_means(kmeans=kmeans, name="PCA-based", data=data, labels=labels)
print(82 * "_")
""" 输出
__________________________________________________________________________________
init time inertia homo compl v-meas ARI AMI silhouette
k-means++ 0.060s 69662 0.680 0.719 0.699 0.570 0.695 0.159
random 0.052s 69707 0.675 0.716 0.694 0.560 0.691 0.181
PCA-based 0.018s 72686 0.636 0.658 0.647 0.521 0.643 0.143
__________________________________________________________________________________
"""
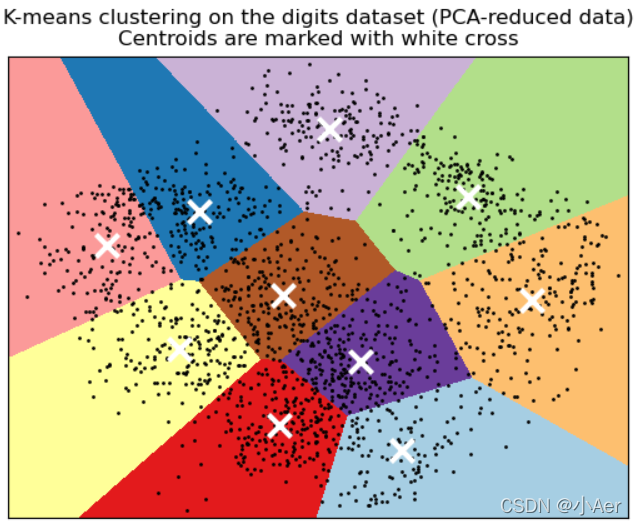
# 4.可视化PCA降维数据(作用:使用plt可视化对PCA降维数据后的KMeans聚类结果)
import matplotlib.pyplot as plt
reduced_data = PCA(n_components=2).fit_transform(data)
kmeans = KMeans(init="k-means++", n_clusters=n_digits, n_init=4)
kmeans.fit(reduced_data)
# Step size of the mesh. Decrease to increase the quality of the VQ.
h = 0.02 # point in the mesh [x_min, x_max]x[y_min, y_max].
# Plot the decision boundary. For that, we will assign a color to each
x_min, x_max = reduced_data[:, 0].min() - 1, reduced_data[:, 0].max() + 1
y_min, y_max = reduced_data[:, 1].min() - 1, reduced_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Obtain labels for each point in mesh. Use last trained model.
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(
Z,
interpolation="nearest",
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired,
aspect="auto",
origin="lower",
)
plt.plot(reduced_data[:, 0], reduced_data[:, 1], "k.", markersize=2)
# Plot the centroids as a white X
centroids = kmeans.cluster_centers_
plt.scatter(
centroids[:, 0],
centroids[:, 1],
marker="x",
s=169,
linewidths=3,
color="w",
zorder=10,
)
plt.title(
"K-means clustering on the digits dataset (PCA-reduced data)\n"
"Centroids are marked with white cross"
)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
2.5 手动实现K-Means算法
from numpy as np
# 1.处理数据,将文本导入到列表中
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataMat.append(fltLine)
return dataMat
# 2.计算两个向量的欧式距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
# 3.为数据集构建一个包含k个随机质心的集合。
def randCent(dataSet, k):
"""
随机质心要在整个数据集的边界之内,所以要通过最大和最小值来完成。
然后通过0-1.0的随机数,将质心=最小范围+最大最小的差通过0-1.0随机数之后的值
"""
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
return centroids
# 4.核心代码
def KMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataset)[0] # 判断有多少数据
clusterAssment = mat(zeros((m,2))) # 存储每个点的簇分配结果,一列存储簇索引值,一列存储误差,误差是指当前点到簇质心的距离
centroids = createCent(dataSet, k) # 创建k个初始质心
clusterChanged = True # 判断是否继续迭代
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf # 临时变量,存储点到簇质心的最小距离
minIndex = -1 # 临时变量,存储点所在簇的质心索引值
for j in range(k):
# for循环寻找最近的质心
distJI = distMeas(centroids[j, :], dataSet[i, :]) # 计算每个点到质心的距离
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex: # 如果簇的质心发生变化,则继续迭代
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
print(centroids)
# 更新质心的位置
for cent in range(k):
# 通过数组来过滤簇中的所有点
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A==cent)[0]]
# 计算均值,axis=0表示沿列进行均值计算
centroids[cent, :] = mean(ptsInClust, axis=0)
# 返回所有的类质心和点分配结果
return centroids, clusterAssment
3. KNN和K-Means的区别
| KNN | K-Means |
|---|---|
| KNN是分类算法 | K-Means是聚类算法 |
| 监督学习 | 非监督学习 |
| 喂给它的数据集是带label的数据,已经是完全正确的数据 | 喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序 |
| 没有明显的前期训练过程,属于memory-based learning | 有明显的前期训练过程 |
| K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c | K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识 |
| 相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。 | 相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。 |
4. 引用
1.机器学习(西瓜书)
2.https://www.cnblogs.com/nucdy/p/6349172.html
3.https://zhuanlan.zhihu.com/p/78798251
