
非极大值抑制Non-Maximum Suppression(NMS)
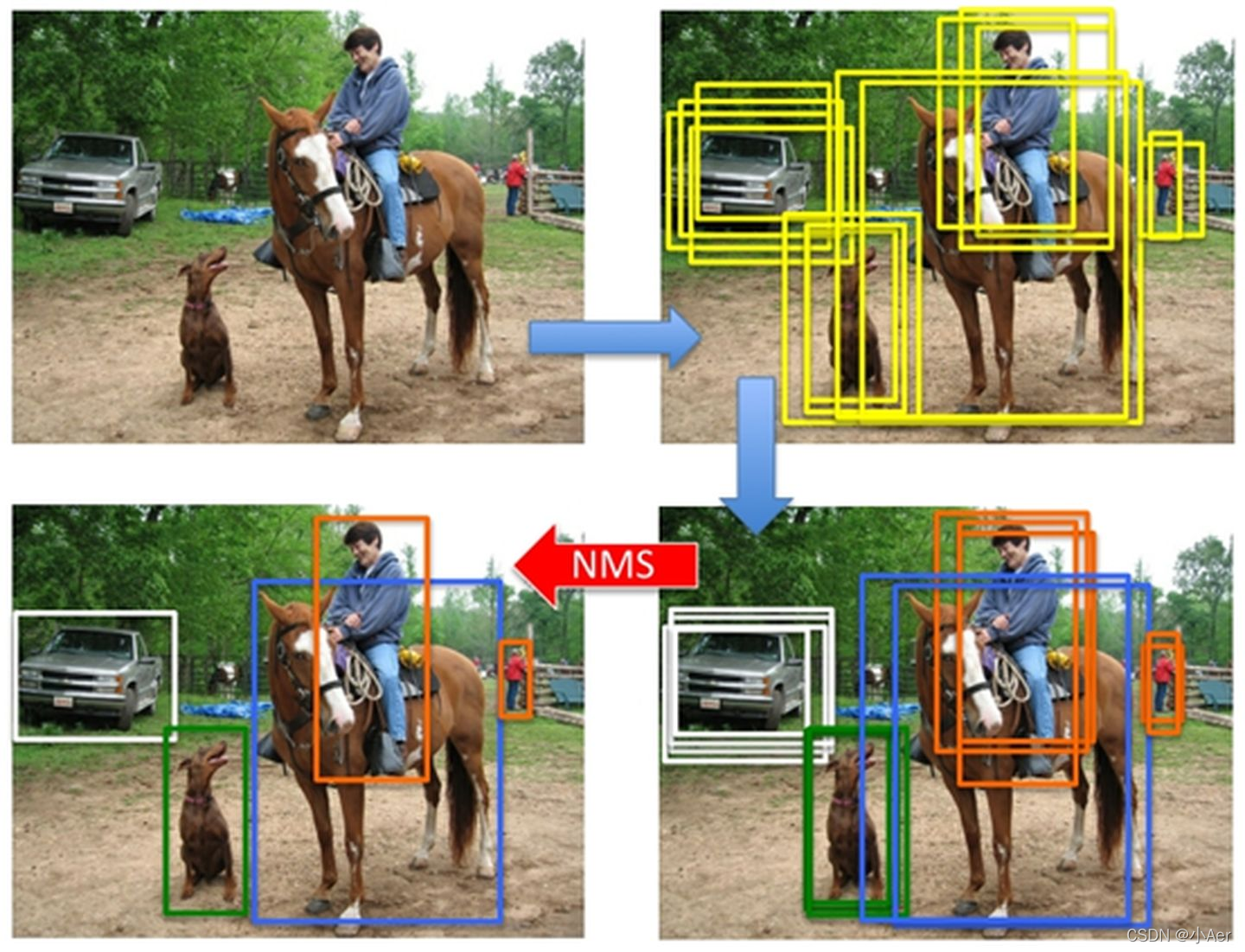
1. 目的
使用NMS目的:提高召回率,但是召回率是“宁肯错杀一千,绝不放过一个”。因此在目标检测中,模型往往会提出远高于实际数量的区域提议(Region Proposal,SSD等one-stage的Anchor也可以看作一种区域提议)。
这就导致最后输出的边界框数量往往远大于实际数量,而这些模型的输出边界框往往是堆叠在一起的。因此,我们需要NMS从堆叠的边框中挑出最好的那个。
2. 何时使用NMS?
回顾我在Cascade-RCNN中提到的流程:
- 提议区域
- 提取特征
- 目标分类
- 回归边框
NMS使用在4. 回归边框之后,即所有的框已经被分类且精修了位置。且所有区域提议的预测结果已经由置信度与阈值初步筛选之后。
3. 算法流程
算法输入
算法对一幅图产生的所有的候选框,每个框有坐标与对应的打分(置信度)。
如一组5维数组:
- 每个组表明一个边框,组数是待处理边框数
4个数表示框的坐标:X_max,X_min,Y_max,Y_min
1个数表示对应分类下的置信度
注意:每次输入的不是一张图所有的边框,而是一张图中属于某个类的所有边框(因此极端情况下,若所有框的都被判断为背景类,则NMS不执行;反之若存在物体类边框,那么有多少类物体则分别执行多少次NMS)。除此之外还有一个自行设置的参数:阈值 TH。
算法输出
- 输入的一个子集,同样是一组5维数组,表示筛选后的边界框。
算法流程
- 将所有的框按类别划分,并剔除背景类,因为无需NMS。
- 对每个物体类中的边界框(B_BOX),按照分类置信度降序排列。
- 在某一类中,选择置信度最高的边界框B_BOX1,将B_BOX1从输入列表中去除,并加入输出列表。
- 逐个计算B_BOX1与其余B_BOX2的交并比IoU,若IoU(B_BOX1,B_BOX2) > 阈值TH,则在输入去除B_BOX2,否则保留。
- 重复步骤3~4,直到输入列表为空,完成一个物体类的遍历。
- 重复2~5,直到所有物体类的NMS处理完成。
- 输出列表,算法结束
tips: IoU=两个框的交集/两个框的并集
4. 算法实现(pytorch)
import torch
import cv2
# NMS算法
# bboxes维度为[N,4],scores维度为[N,], 均为tensor
def nms(bboxes, scores, threshold=0.5):
x1 = bboxes[:,0] # [N,]
y1 = bboxes[:,1] # [N,]
x2 = bboxes[:,2] # [N,]
y2 = bboxes[:,3] # [N,]
areas = (x2-x1)*(y2-y1) # [N,] 每个bbox的面积
_, order = scores.sort(0, descending=True) # 降序排列 tensor([0, 2, 1])
picked_boxes = []
picked_score = []
keep = []
while order.numel() > 0: # torch.numel()返回张量元素个数
if order.numel() == 1: # 保留框只剩一个
i = order.item()
keep.append(i)
picked_boxes.append(bboxes[i])
picked_score.append(scores[i])
break
else:
i = order[0].item() # 保留scores最大的那个框box[i]
keep.append(i)
picked_boxes.append(bboxes[i])
picked_score.append(scores[i])
# 计算box[i]与其余各框的IOU(思路很好)
xx1 = x1[order[1:]].clamp(min=x1[i]) # [N-1,] torch.clamp(min, max) 设置上下限
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0) # [N-1,]
iou = inter / (areas[i]+areas[order[1:]]-inter) # [N-1,]
idx = (iou <= threshold).nonzero().squeeze() # 注意此时idx为[N-1,] 而order为[N,], idx为此时iou <= threshold对应下标
if idx.numel() == 0:
break
order = order[idx+1] # 修补索引之间的差值,idx是从order第二个开始计数的,需要直到在order中的下标,所以加1
return torch.LongTensor(keep), torch.stack(picked_boxes), torch.stack(picked_score) # Pytorch的索引值为LongTensor
# Image name
image_name = 'nms.jpg'
# Bounding boxes
bounding_boxes = [[187, 82, 337, 317], [150, 67, 305, 282], [246, 121, 368, 304]]
confidence_score = [0.9, 0.75, 0.8]
# Read image
image = cv2.imread(image_name)
# Copy image as original
org = image.copy()
# Draw parameters
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
thickness = 2
# IoU threshold
threshold = 0.4
# Draw bounding boxes and confidence score
for (start_x, start_y, end_x, end_y), confidence in zip(bounding_boxes, confidence_score):
(w, h), baseline = cv2.getTextSize(str(confidence), font, font_scale, thickness)
cv2.rectangle(org, (start_x, start_y - (2 * baseline + 5)), (start_x + w, start_y), (0, 255, 255), -1)
cv2.rectangle(org, (start_x, start_y), (end_x, end_y), (0, 255, 255), 2)
cv2.putText(org, str(confidence), (start_x, start_y), font, font_scale, (0, 0, 0), thickness)
# Run non-max suppression algorithm
# picked_boxes, picked_score = nms(bounding_boxes, confidence_score, threshold)
keep, picked_boxes, picked_score = nms(torch.tensor(bounding_boxes), torch.tensor(confidence_score), threshold)
picked_boxes = picked_boxes.numpy().tolist()
picked_score = picked_score.numpy().tolist()
# Draw bounding boxes and confidence score after non-maximum supression
for (start_x, start_y, end_x, end_y), confidence in zip(picked_boxes, picked_score):
(w, h), baseline = cv2.getTextSize(str(confidence), font, font_scale, thickness)
cv2.rectangle(image, (start_x, start_y - (2 * baseline + 5)), (start_x + w, start_y), (0, 255, 255), -1)
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), (0, 255, 255), 2)
cv2.putText(image, str(confidence), (start_x, start_y), font, font_scale, (0, 0, 0), thickness)
# Show image
cv2.imshow('Original', org)
cv2.imshow('NMS', image)
cv2.waitKey(0)
下面是样例图片

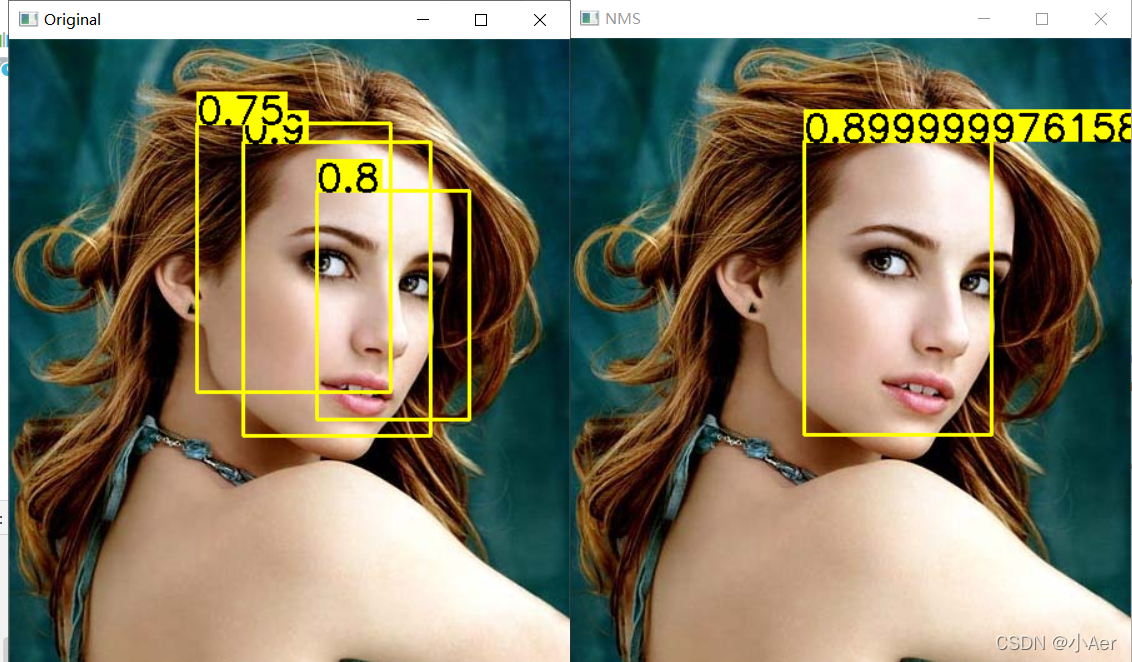
我使用tolist之后0.9就变成0.8999…,不知道为什么,有知道的欢迎评论指出;
还有我使用的IoU是0.4,可以自己设置0.5 0.6试试

