分类问题的评估指标
1️⃣ 起始源头
这是西瓜书P30的图,细化一下就是下面这张图

2️⃣ 重要三点
- 🎈 不要想着把字母在表格中对应
- 🍕 TP、TN、FP、FN 中的第二个字母是机器学习算法或模型预测的结果标识(正例:P、反例:N)
- 🍔TP、TN、FP、FN 中的第一个字母是根据真实情况判断模型的预测结果是否正确的标识(正确:T、错误:F)
- 即:🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃
正确地预测为正例(真正例):TP
正确地预测为反例(真反例):TN
错误地预测为正例(假正例):FP
错误地预测为反例(假反例):FN
3️⃣ 衍生而出的指标
🍞 召回率==查全率R

表示:所有正例中被正确预测出来的比例。
用途:用于评估检测器对所有待检测目标的检测覆盖率
举例:以物体检测为例,我们往往把图片中的物体作为正例,此时召回率高代表着模型可以找出图片中更多的物体
🍦 精确率==查准率P

表示:预测结果中真正的正例的比例。
用途:用于评估检测器在检测成功基础上的正确率
举例:以物体检测为例,精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体
🍞 + 🍦 = 🍰 PR曲线
召回率(查全率)和精确率(查准率)是一对矛盾的度量。一般来说,查全率和查准率成反比

采用平衡点来衡量,令每个分类模型的召回率与精准率相等即为该模型的 BEP,BEP 越大,则模型的性能越好
表示:以召回率(查全率)为横坐标,精确率(查准率)为纵坐标,构成PR图,上面的线段叫做PR曲线
用途:平衡两个指标达到最优,避免出现某个指标偏低或偏高
🍱 准确率

表示:模型判断正确的数据(TP+TN)占总数据的比例
用途:判断模型分辨正负样本的能力
举例:以物体检测为例,准确率高模型检测出的正样本本身就是正样本,负样本本身就是负样本,可以判断模型辨别正负样本的能力
缺点:准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
🌮 F1

F1 指标综合考虑了召回率(= =查全率)与精准率(= = 查准率)两种情况,相比于BEP更常用
🍠 Fβ
在一些应用中,对召回率(= =查全率)和精确率(= = 查准率)的重视程度不同。
举例:在商品推荐系统中,为了尽可能少打扰客户,更希望推荐内容确实是客户所感兴趣的,此时精确率(= = 查准率)更重要;而在逃犯信息检测系统中,更希望尽可能少漏掉逃犯,此时召回率(= =查全率)更重要,所以出现了下面这个公式,更好的针对召回率和精确率的偏好
tips: 我感觉从字面意思看,查准率和查全率,对于上述举例更好理解,鉴名知义(推荐就是要准!= = >> 查准率;查犯人就要全!= = >> 查全率)
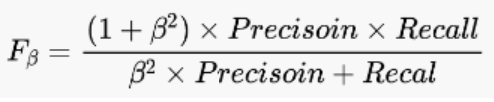
当β=1 时,Fβ 指标蜕化为 F1 指标,此时召回率与精准率的重要程度相同;
当 β>1 时召回率(= =查全率)的影响大于精准率;
相反,当β<1 时,精准率(= = 查准率)的影响大于召回率
tps: 标准评估指标的本质是从模型预测结果出发来度量模型性能优劣的,如分类模型从混淆矩阵中得到各种不同的性能指标,回归模型直接从预测结果与真实结果的偏差角度进行分析。
想学习更多指标问题,可参考该链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号