

解决梯度爆炸和梯度消失
文章目录
原因
梯度消失和梯度爆炸两种情况产生的原因可以总结成2类原因:1.深层网络的结构;2.不合适的损失函数,比如Sigmoid函数。梯度爆炸一般出现在深层网络和权值初始化值太大的情况下。
解决方案
1.预训练和微调
预训练:无监督逐层训练,每次训练一层隐藏点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入。称为逐层预训练。在预训练完成后还要对整个网络进行微调。
2.relu、leakyrelu、Relu等激活函数
具体介绍可参看我的另外一篇文章详解激活函数
3.Batch Normalization(批规范化)
因为在反向传播的时候,需要计算梯度,那么不可避免带有权重 W,而BN的作用就是通过对每一层的输出规范为均值和方差一致的方法,消除了 W 带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉到了非饱和区(比如Sigmoid函数)。
4.残差结构
具体介绍可参看我的另外一篇文章ResNet知识点补充
5.梯度剪切、正则
剪切的方法有两种
- 按值截断:在第t次迭代时,梯度为
g
t
g_t
gt ,给定一个区间[a,b],如果一个参数的梯度小于a时,就将其设为a;如果大于b时,就将其设为b。

- 按模截断:将梯度的模截断到一个给定的截断阈值b。如果 ∣ ∣ g t ∣ ∣ 2 < = b ||g_t||^2 <= b ∣∣gt∣∣2<=b ,保持 g t g_t gt 不变。如果 ∣ ∣ g t ∣ ∣ 2 > b ||g_t||^2 > b ∣∣gt∣∣2>b , ∣ ∣ g t ∣ ∣ = b / ∣ ∣ g t ∣ ∣ ∗ g t ||g_t|| = b/||g_t|| * g_t ∣∣gt∣∣=b/∣∣gt∣∣∗gt ,b为超参数,往往一个小的阈值可以达到很好的效果。在训练循环神经网络时,按模截断是避免题都爆炸问题的有效方法。
正则化的方法有比较常见的l1正则和l2正则,正则化是通过对网络权重做正则限制过拟合,仔细看正则项在损失函数的形式:
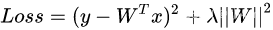
λ
λ
λ 是正则项系数,如果发生梯度爆炸,权值的范数会变得非常大,通过正则化项,可以部分限制梯度爆炸的发生。
6.LSTM(长短期记忆网络)
在RNN网络结构中,由于使用Logistic或者Tanh函数,所以很容易导致梯度消失的问题,即在相隔很远的时刻时,前者对后者的影响几乎不存在了,LSTM的机制正是为了解决这种长期依赖问题。这个算法不多,只是知道可以解决。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix