opencv4.2.0.34+python3.8.2+(获取图片视频并打开、numpy、色彩空间、数值与逻辑计算、图像的切割合并填充、floodFill、卷积模糊处理、高斯噪声处理高斯模糊、ERF)
(有的运行结果没弄上去,但文中代码本人亲测均通过;至于有人因版本问题出现个别错误,我相信对于大家应该没什么问题,文档就是很好的辅助学习资料)
文章目录
- 一、openCV和openGL的区别
- 二、opencv的安装和测试(win10环境下)
- 三、opencv的模块
- 四、读取显示图片及其信息
- 五、获取摄像头并打开
- 六、numpy操作数组输出图片
- (1)读取一张图片,修改颜色通道后输出
- (2)多通道函数:zeros和ones
- (3)单通道函数:zeros和ones
- (4)像素取反
- (5)矩阵填充和重塑矩阵
- 七、色彩空间
- (1)通过inRange函数进行色彩捕捉
- (2)通道合并
- 八、图片色素的数值运算(加减乘除)和逻辑运算(与或非异或)
- (1)数值运算
- (2)逻辑运算(按位与或非异或运算+粗略提高图像对比度和亮度)
- 九、图像的切割,合并和填充
- 十、floodFill填充函数(泛洪填充)
- 十一、利用卷积对图像模糊处理
- 十二、添加高斯噪声并使用高斯模糊处理
- 十三、边缘保留滤波(EPF)
一、openCV和openGL的区别
OpenCV是 Open Source Computer Vision Library
OpenGL是 Open Graphics Library
OpenCV主要是提供图像处理和视频处理的基础算法库,还涉及一些机器学习的算法。比如你想实现视频的降噪、运动物体的跟踪、目标(比如人脸)的识别这些都是CV的领域
OpenGL则专注在Graphics,3D绘图。
其实两者的区别就是Computer Vision和Computer Graphics这两个学科之间的区别,前者专注于从采集到的视觉图像中获取信息,是用机器来理解图像;后者是用机器绘制合适的视觉图像给人看。
二、opencv的安装和测试(win10环境下)
一般opencv有四个模块:
opencv-python: 只包含opencv库的主要模块. 一般不推荐安装.
opencv-contrib-python: 包含主要模块和contrib模块, 功能基本完整, 推荐安装.
opencv-python-headless: 和opencv-python一样, 但是没有GUI功能, 无外设系统可用.
opencv-contrib-python-headless: 和opencv-contrib-python一样但是没有GUI功能. 无外设系统可用.
因此一般来说都会选择安装opencv-contrib-python
window环境下安装命令:pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple
(当然pip命令有可能也需要安装更新之类的,网上查找更新命令即可,如果可以运行当我没说;如果直接使用安装命令pip install opencv-contrib-python会比较慢,所以我使用了国内资源)
不要同时安装opencv-python和opencv-contrib-python
1.可以在window终端下进行简单的测试(当然我写的时候按python代码块处理了,所以出现下面情况)
>>>import cv2
>>>cv2.__version__
'4.2.0'
2.在pycharm中的测试(pycharm的安装和破解网上很多,我这里不进行解释;还有在pycharm中进行测试的时候,虽然cv2模块已经下载好,但是pycharm中并没有导入,可参考下面网址,将下载好的模块导入到pycharm中【https://blog.csdn.net/ShadowFox_/article/details/82871575】)
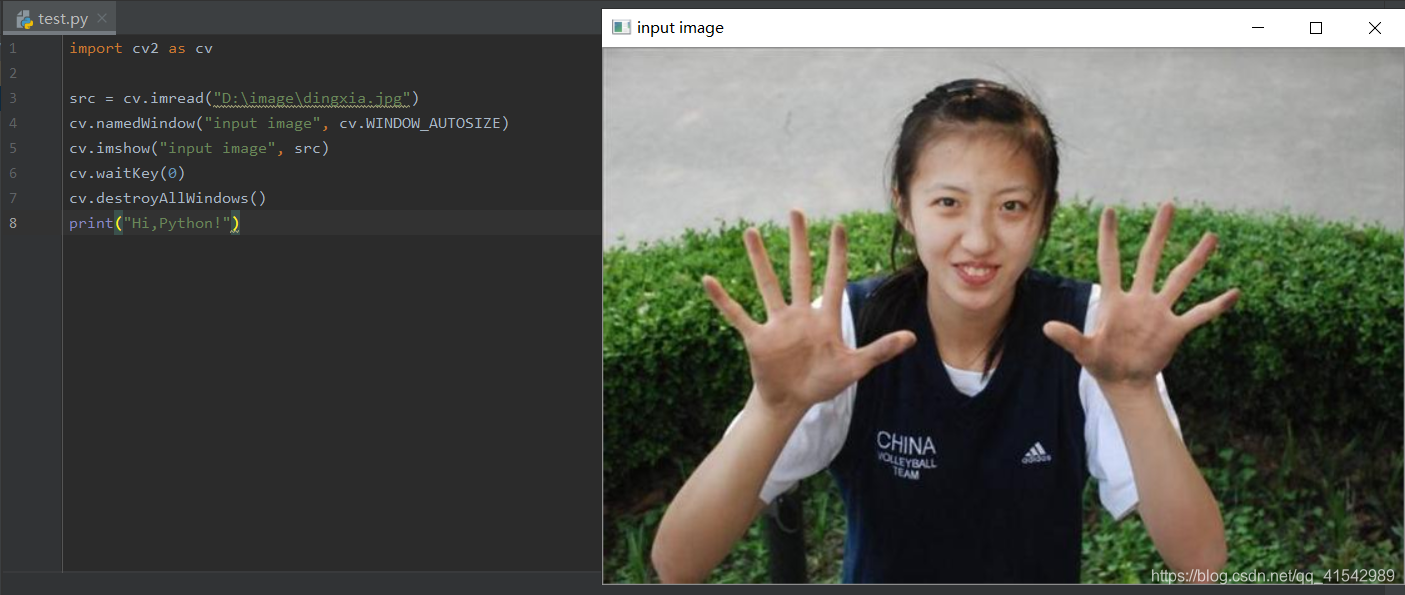
如果可以输出图片,并且在关闭后输出Hi,Python!那么表示安装成功(第三行代码处图片路径最好是英文;代码中注意W是大写,如果不是同样会输出图片,但关闭图片之后不会输出Hi,Python!)
三、opencv的模块
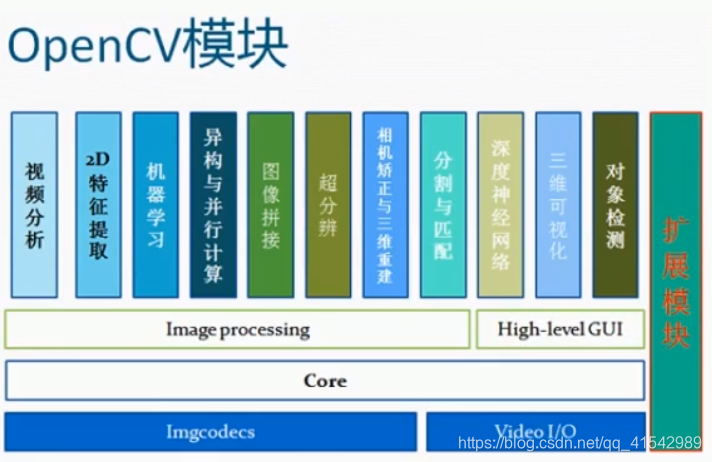
下面的五个横框表示基础模块。右边是扩展的模块,也就是opencv-contrib-python中的contrib,下载该模块之后才可以使用。上面的11个模块是基于下面五个基础模块的。
四、读取显示图片及其信息
import cv2 as cv
import numpy as np
# 输出图片属性
def get_image_info(image):
"""
查看图片的属性
:param image: 要输出的图片
"""
# 显示图片类型 numpy类型的数组
print(type(image))
# 图像矩阵的shape属性表示图像的大小,shape会返回tuple元组,第一个元素表示矩阵行数,第二个元组表示矩阵列数,第三个元素是3,表示像素值由光的三原色组成
print(image.shape)
# 图像大小
print(image.size)
# 图像类型
print(image.dtype)
# 将图片作为矩阵进行输出
pixel_data = np.array(image)
print(type(pixel_data))
print(pixel_data)
# 读取图片
src = cv.imread("D:/image/dingxia.jpg")
# 创建窗口,不写也可show出来,第一个参数是窗口名字,第二个参数为窗口显示方式
# 为0或cv.WINDOW_NORMAL:可以改变窗口大小
# 不写或cv.WINDOW_AUTOSIZE则不可改变大小
cv.namedWindow("Hello opencv!",cv.WINDOW_AUTOSIZE)
# 显示图片窗口,第一个参数是窗口名称,第二个参数是要显示的图片
cv.imshow("Hello opencv!",src)
# 调用函数
get_image_info(src)
# 对图片另存,不要存C盘,要用权限
cv.imwrite("D:/image/1.png",src)
# 窗口显示时间waitKey(k),k<=0,窗口一直显示,按下数字键消失,k>0,表示显示多少毫秒
cv.waitKey(0)
# 删除建立的全部窗口,释放资源
cv.destroyAllWindows()
print("Hi,Python!")
五、获取摄像头并打开
import cv2 as cv
def video_demo():
"""
打开摄像头或视频文件
"""
# 打开摄像头,0代表的是设备id,如果有多个摄像头,可以设置其他数值
# 第二个参数是因为采用默认的API控制出错,所以加上cv.CAP_DSHOW
capture = cv.VideoCapture(0, cv.CAP_DSHOW)
while True:
# 读取摄像头,它能返回两个参数,第一个参数是bool型的ret,其值为True或False,代表有没有读到图片;第二个参数是frame,是当前截取一帧的图片
ret, frame = capture.read()
# 翻转 0:上下颠倒 大于0:水平颠倒 小于0:180旋转
frame = cv.flip(frame, 1)
cv.imshow("video", frame)
# esc对应的ascii值为27,使用esc关闭窗口
c = cv.waitKey(50)
if c == 27:
break
video_demo()
cv.destroyAllWindows()
特别注意第10行代码处,参数cv.CAP_DSHOW一开始我没有写,在关闭摄像头时出现下列报错,所以我加上该参数,这是由于采用默认的API控制出错
[ WARN:0] global C:\projects\opencv-python\opencv\modules\videoio\src\cap_msmf.cpp (674) SourceReaderCB::~SourceReaderCB terminating async callback
六、numpy操作数组输出图片
(1)读取一张图片,修改颜色通道后输出
# -*- coding=GBK -*-
import cv2 as cv
import numpy as np
# numpy数组操作
def access_pixels(image):
print(image.shape)
height = image.shape[0]
width = image.shape[1]
channel = image.shape[2]
print("width : %s, height : %s, channel : %s" % (width, height, channel))
for row in range(height):
for col in range(width):
for c in range(channel):
# 得到行数,列数,通道数的矩阵
pv = image[row, col, c]
# 对矩阵进行操作可改变图像像素,为什么255减去原因暂时不知,后续知道会进行更改
image[row, col, c] = 255 - pv
cv.imshow("later", image)
src = cv.imread("D:/image/dingxia.jpg")
# cv.namedWindow("原来", cv.WINDOW_NORMAL) 可以不写
cv.imshow("start", src)
t1 = cv.getTickCount() # 毫秒级别的计时函数,记录了系统启动以来的时间毫秒
access_pixels(src)
t2 = cv.getTickCount()
time = (t2 - t1) * 1000 / cv.getTickFrequency() # getTickFrequency用于返回CPU的频率,就是每秒的计时周期数
print("time: %s" % time) # 输出运行的时间
cv.waitKey(0)
cv.destroyAllWindows()
(2)多通道函数:zeros和ones
import cv2 as cv
import numpy as np
# 自定义多通道图片1
def create_image_zeros():
# zeros:double类零矩阵 创建400*400 3个通道的矩阵图像 参数时classname为uint8
img = np.zeros([400, 400, 3], np.uint8)
# ones([400, 400])是创建一个400*400的全1矩阵,*255即是全255矩阵 *后面数字可以自由变换 并将这个矩阵的值赋给img的第一维
img[:, :, 0] = np.ones([400, 400]) * 0
img[:, :, 1] = np.ones([400, 400]) * 0
img[:, :, 2] = np.ones([400, 400]) * 0
# 输出一张400*400的白色图片(255 255 255):蓝(B)、绿(G)、红(R),bgr顺序不能乱,和常说的rgb反过来了
cv.imshow("自制图片1", img)
# 自定义多通道图片2
def create_image_ones():
img = np.ones([400, 400, 3], np.uint8)
img[:, :, 0] = img[:, :, 0] * 255
img[:, :, 1] = img[:, :, 1] * 255
img[:, :, 2] = img[:, :, 2] * 255
cv.imshow("自制图片2", img)
create_image_zeros()
create_image_ones()
cv.waitKey(0)
cv.destroyAllWindows()
区别:
zeros:生成全0的矩阵
ones:生成全1的矩阵
(3)单通道函数:zeros和ones
# -*- coding=GBK -*-
import cv2 as cv
import numpy as np
def create_image_zeros():
img = np.zeros([400, 400, 1], np.uint8)
# img[:, :, 0] = 127, 下面代码也可以这样写,直接赋值127,效果相同
img[:, :, 0] = np.ones([400, 400]) * 127
cv.imshow("自制图片1", img)
def create_image_ones():
img = np.zeros([400, 400, 1], np.uint8)
# zeros是全0矩阵,所以需要用到ones全1矩阵乘像素值;img[:, :, 0] = 127,下面代码也可以这样写,直接赋值127,效果相同
img[:, :, 0] = np.ones([400, 400]) * 127
# 下面代码直接使用ones全1矩阵,所以可以直接使用该行代码 img = img * 127
# img = np.ones([400, 400, 1], np.uint8)
# img = img * 127
cv.imshow("自制图片2", img)
create_image_zeros()
create_image_ones()
cv.waitKey(0)
cv.destroyAllWindows()
对于单通道,像素在0-255之间变化,图像在黑与白之间变化;而对于多通道,三种通道bgr的出现,使图像出现彩色。
对于zeros和ones来说都可以处理多通道和单通道,唯一区别就是一个全0,一个全1,所以zeros还是需要用到ones函数进行像素的设置,全0进行乘法*的运算永远是全0,这样是达不到效果的
(4)像素取反
# -*- coding=GBK -*-
import cv2 as cv
import numpy as np
# 像素取反
def inverse(image):
dst = cv.bitwise_not(image)
cv.imshow("inverse", dst)
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("start", cv.WINDOW_NORMAL)
cv.imshow("start", src)
t1 = cv.getTickCount()
inverse(src)
t2 = cv.getTickCount()
time = (t2 - t1) * 1000 / cv.getTickFrequency()
print("time: %s" % time)
cv.waitKey(0)
cv.destroyAllWindows()
(5)矩阵填充和重塑矩阵
# -*- coding=GBK -*-
import cv2 as cv
import numpy as np
def create_image():
# 生成一个3*3维的单通道矩阵
m1 = np.ones([3, 3], np.uint8)
# 向矩阵中填充值,可以是int,float,complex,有时候注意np.uint8是整型,如果fill填充的是float型可能涉及到溢出,12222.388就是特殊案例,注意上下对应即可
m1.fill(12222.388)
print(m1)
# 对矩阵进行重塑,改变矩阵样式
m2 = m1.reshape([1, 9])
print(m2)
# array需要将数组内容一一列出,而ones只需给出大小进行填充即可
m3 = np.array([[2, 3, 4], [4, 5, 6], [6, 7, 8]], np.uint32)
# m3.fill(9)
print(m3)
create_image()
cv.waitKey(0)
cv.destroyAllWindows()
七、色彩空间
(1)通过inRange函数进行色彩捕捉
这个模型中颜色的参数分别是:色调Hue(H),饱和度Saturation(S),明度Value(V)。
import cv2 as cv
import numpy as np
def extract_object_demo():
"""
inRange函数色彩捕捉
"""
video = cv.VideoCapture("D:/image/white.mp4")
while True:
ret, frame = video.read()
if not ret:
break
# 通过inrange函数进行色彩捕捉,对白色进行捕捉,这个看自己视频中要捕捉颜色,然后根据下方表确定范围
hsv = cv.cvtColor(frame, cv.COLOR_RGB2HSV)
lower_hsv = np.array([0, 0, 221])
upper_hsv = np.array([180, 30, 255])
mask = cv.inRange(hsv, lowerb=lower_hsv, upperb=upper_hsv)
cv.imshow("mask", mask)
# 逻辑与运算,后面几节出现,对与运算加上mask也可以出现图像,mask是可选参数,具体参数含义可查看opencv官方文档
dst = cv.bitwise_and(frame, frame, mask=mask)
cv.imshow("dst", dst)
cv.imshow("video", frame)
c = cv.waitKey(40)
if c == 27:
break
def color_space_demo(image):
# 色彩空间转换API,当然还有很多,rgb,gray,hsv,yuv,ycrcb比较常见,尤其rgb到hsv和yuv的转换记牢
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
cv.imshow("gray", gray)
hsv = cv.cvtColor(image, cv.COLOR_RGB2HSV)
cv.imshow("hsv", hsv)
yuv = cv.cvtColor(image, cv.COLOR_RGB2YUV)
cv.imshow("yuv", yuv)
ycrcb = cv.cvtColor(image, cv.COLOR_RGB2YCrCb)
cv.imshow("ycrcb", ycrcb)
src = cv.imread("D:/image/dingxia.jpg")
# cv.namedWindow("start", cv.WINDOW_AUTOSIZE)
# cv.imshow("start", src)
extract_object_demo()
# color_space_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
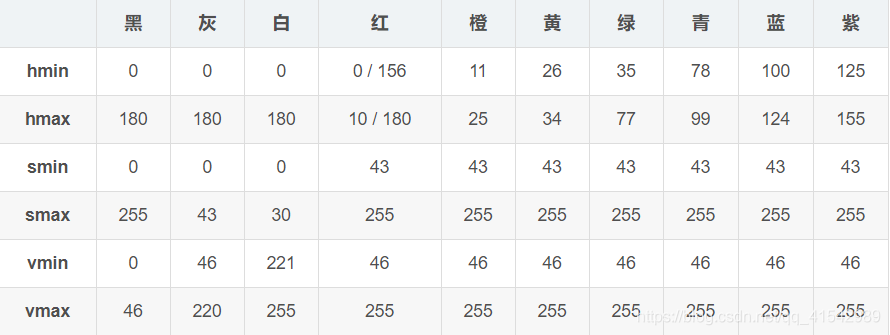
(2)通道合并
# -*- coding=GBK -*-
import cv2 as cv
import numpy as np
def merge_channel(image):
# 使用split将图片切分为三个通道
b, g, r = cv.split(image)
cv.imshow("blue", b)
cv.imshow("green", g)
cv.imshow("red", r)
# 使用merge进行通道的合并
img = cv.merge([b, g, r])
cv.imshow("merge", img)
# 修改某个单通道的值
img[:, :, 2] = 100
cv.imshow("单通道", img)
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("start", cv.WINDOW_AUTOSIZE)
cv.imshow("start", src)
merge_channel(src)
cv.waitKey(0)
cv.destroyAllWindows()
八、图片色素的数值运算(加减乘除)和逻辑运算(与或非异或)
(1)数值运算
opencv自带图片色素的处理函数:
相加:add()
相减:subtract()
相乘:multiply()
相除:divide()
原理就是:通过获取两张(一次只能是两张)个图片的同一个位置的色素值来实现运算。
运算的要求:两张图片的shape要一样。
例图:(自己保存为图片格式即可)


import cv2 as cv
import numpy as np
def add_pixels(m1, m2):
dst = cv.add(m1, m2)
cv.imshow("add", dst)
def subtract_pixels(m1, m2):
dst = cv.subtract(m1, m2)
cv.imshow("subtract", dst)
# cv.imwrite("D:/image/linux_window.jpg", dst) linux-window还是比较好看就保存了
def multiply_pixels(m1, m2):
dst = cv.multiply(m1, m2)
cv.imshow("multiply", dst)
def divide_pixels(m1, m2):
dst = cv.divide(m1, m2)
cv.imshow("divide", dst)
# 均值和方差 mean表示均值,meanStdDev可返回均值和方差
def others(m1, m2):
M1, dev1 = cv.meanStdDev(m1)
M2, dev2 = cv.meanStdDev(m2)
# 取和图像m1相同的高宽,【:2】涉及切片,左实右虚,取shape前两个
h, w = m1.shape[:2]
print(M1)
print(M2)
print(dev1)
print(dev2)
# 对于像素相同的矩阵,方差均为0,这里使用了全0矩阵,所以输出的均值和方差均为0
# 若使用ones全1矩阵,那么输出均值为1,方差为0
img = np.zeros([h, w], np.uint8)
m, dev = cv.meanStdDev(img)
print(m)
print(dev)
src1 = cv.imread("D:/image/linux.jpg")
src2 = cv.imread("D:/image/window.jpg")
# cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)有没有影响不大,除非对图片有大小变化需求
cv.imshow("Hello linux!", src1)
cv.imshow("Hello window!", src2)
# add
add_pixels(src1, src2)
# subtract
subtract_pixels(src1, src2)
# multiply
multiply_pixels(src1, src2)
# divide
divide_pixels(src1, src2)
others(src1, src2)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
(2)逻辑运算(按位与或非异或运算+粗略提高图像对比度和亮度)
opencv自带图片色素的处理函数:
与:bitwise_add() 全1则1,其他为0
或:bitwise_or() 有1为1,其他为0
非:bitwise_not() 1为0,0为1
异或:bitwise_xor() 相同为0,不同为1
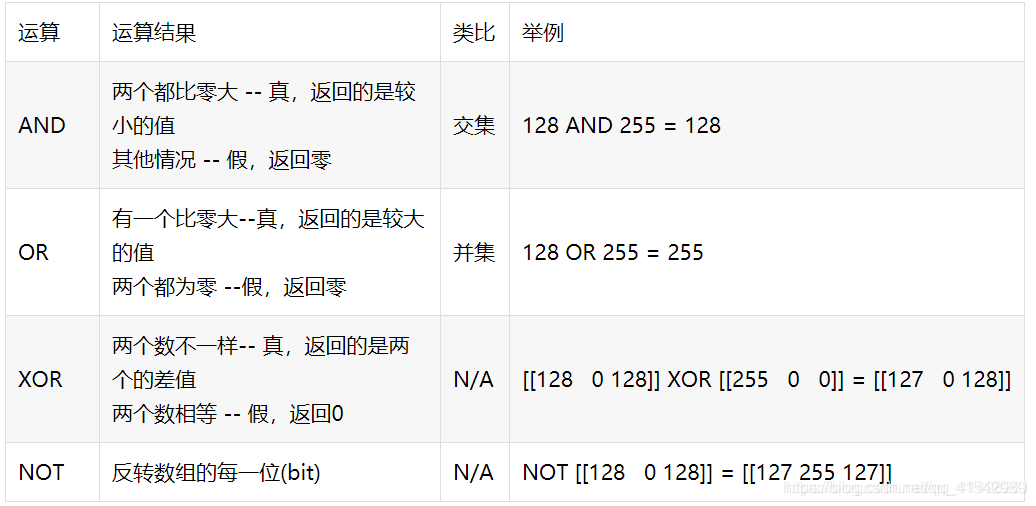
对于0 1 的来说,这四种操作比较好理解,对于像素值来说要采用下表方式进行按位与或非、异或操作:
import cv2 as cv
import numpy as np
def logic_demo(m1, m2):
"""
逻辑运算 与或非异或
:param m1: 第一张图片
:param m2: 第二张图片
"""
dst = cv.bitwise_and(m1, m2)
cv.imshow("and", dst)
dst = cv.bitwise_or(m1, m2)
cv.imshow("or",dst)
dst = cv.bitwise_not(m1)
cv.imshow("not1", dst)
dst = cv.bitwise_not(m2)
cv.imshow("not2", dst)
dst = cv.bitwise_xor(m1, m2)
cv.imshow("xor", dst)
def contrast_brightness_demo(image, c, b):
"""
调整图像对比度和亮度
:param image: 要调整的图片
:param c: 对比度
:param b: 亮度
"""
h, w, ch = image.shape
# blank是一个全0的矩阵,是黑色的
blank = np.zeros([h, w, ch], image.dtype)
dst = cv.addWeighted(image, c, blank, 1-c, b)
cv.imshow("demo", dst)
src1 = cv.imread("D:/image/linux.jpg")
src2 = cv.imread("D:/image/window.jpg")
# cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello linux!", src1)
cv.imshow("Hello window!", src2)
# 逻辑运算 与或非异或
# logic_demo(src1, src2)
# 调整图像对比度和亮度
contrast_brightness_demo(src2, 1.5, 0)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype=-1);
一共有七个参数:前4个是两张要合成的图片及它们所占比例,第5个double gamma起微调作用,第6个OutputArray dst是合成后的图片,第七个输出的图片的类型(可选参数,默认-1)
有公式得出两个图片加成输出的图片为:dst=src1alpha+src2beta+gamma
九、图像的切割,合并和填充
从被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出需要处理的区域,称为感兴趣区域ROI(region of interest)
import cv2 as cv
import numpy as np
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# 切割图像,范围的查找要自己慢慢试
img = src[50:200, 230:350]
# 将切割出的图像填充变成灰色
gray = cv.cvtColor(img, cv.COLOR_RGB2GRAY)
# 下面这行代码是为了增加通道,因为gray为灰度图像,是单通道,而src是三通道,所以需要cvtColor一下,将其转换为三通道
# 而且由于灰度图像无法再恢复成彩色图像,所以cvtColor之后,只会增加通道数,图像表现还是灰色
backface = cv.cvtColor(gray, cv.COLOR_RGB2BGR)
# 合并图像
src[50:200, 230:350] = backface
cv.imshow("gray", src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
十、floodFill填充函数(泛洪填充)
floodFill函数:漫水填充算法
基本思想:
所谓漫水填充,简单来说,就是自动选中了和种子点相连的区域,接着将该区域替换成指定的颜色,这是个非常有用的功能,经常用来标记或者分离图像的一部分进行处理或分析.漫水填充也可以用来从输入图像获取掩码区域,掩码会加速处理过程,或者只处理掩码指定的像素点.
以此填充算法为基础,类似photoshop的魔术棒选择工具就很容易实现了。漫水填充(FloodFill)是查找和种子点联通的颜色相同的点,魔术棒选择工具则是查找和种子点联通的颜色相近的点,将和初始种子像素颜色相近的点压进栈作为新种子
在OpenCV中,漫水填充是填充算法中最通用的方法。且在OpenCV 2.X中,使用C++重写过的FloodFill函数有两个版本。一个不带掩膜mask的版本,和一个带mask的版本。这个掩膜mask,就是用于进一步控制哪些区域将被填充颜色(比如说当对同一图像进行多次填充时)。这两个版本的FloodFill,都必须在图像中选择一个种子点,然后把临近区域所有相似点填充上同样的颜色,不同的是,不一定将所有的邻近像素点都染上同一颜色,漫水填充操作的结果总是某个连续的区域。当邻近像素点位于给定的范围(从loDiff到upDiff)内或在原始seedPoint像素值范围内时,FloodFill函数就会为这个点涂上颜色。
官方定义为:
第一个版本的floodfill(该版本没有mask参数)
int floodFill(InputOutputArray image, Point seedPoint, Scalar newVal, Rect* rect=0, Scalar loDiff=Scalar(), Scalar upDiff=Scalar(), int flags=4 )
第二个版本的floodfill
int floodFill(InputOutputArray image, InputOutputArray mask, Point seedPoint,Scalar newVal, Rect* rect=0, Scalar loDiff=Scalar(), Scalar upDiff=Scalar(), int flags=4 )
以第二个版本进行介绍,但不知道为什么,python中调用这个函数,Rect* rect=0这个参数没有,剩下7个参数 ,至于Rect*类型的rect,有默认值0,一个可选的参数,用于设置floodFill函数将要重绘区域的最小边界矩形区域。在pycharm中没有暂时不考虑
通俗解释:floodFill( 1.操作的图像, 2.掩模, 3.起始像素点,4.填充的颜色, 6.填充颜色的低值, 7.填充颜色的高值 ,8.填充的方法)第五个rect忽略
参数6.填充颜色的低值就是:参数3位置的像素 减去 参数6
参数7.填充颜色的高值就是:参数3位置的像素 加上 参数7
即是这两个数值之间的色素替换为参数4的颜色
彩色图像一般是FLOODFILL_FIXED_RANGE 指定颜色填充
还有一种是FLOODFILL_MASK_ONLY,mask的指定的位置为零时才填充,不为零不填充
最后一个参数的比较:
FLOODFILL_FIXED_RANGE - 如果设置为这个标识符的话,就会考虑当前像素与种子像素之间的差,否则就考虑当前像素与其相邻像素的差。也就是说,这个范围是浮动的。
FLOODFILL_MASK_ONLY - 如果设置为这个标识符的话,函数不会去填充改变原始图像 (也就是忽略第四个参数newVal),而是去填充掩模图像(mask)。这个标识符只对第二个版本的floodFill有用,因第一个版本里面压根就没有mask参数。
至于指定颜色填充的过程,就和FLOODFILL_FIXED_RANGE解释的一样,会和相邻的像素作比较,采用泛洪的方法填充(个人理解,没有找到可信度高的介绍,很遗憾)
该链接是我参考的一篇博客,专门讲解floodfill函数,有兴趣可以看一看
【https://blog.csdn.net/qq_27901569/article/details/49934763】
import cv2 as cv
import numpy as np
# 指定颜色填充
def fill_color_demo(image):
copyImg = image.copy()
h, w = image.shape[:2]
# zeros和ones不写通道数默认单通道
# mask它应该为单通道、8位、长和宽上都比输入图像 image 大两个像素点的图像 +2是官方函数要求
# 需要注意的是,漫水填充不会填充掩膜mask的非零像素区域。也就是只填充掩膜mask的0的区域
mask = np.zeros([h+2, w+2], np.uint8)
cv.floodFill(copyImg, mask, (100, 100), (0, 255, 255), (100, 100, 100), (50, 50, 50), cv.FLOODFILL_FIXED_RANGE)
cv.imshow("fill_color_demo", copyImg)
# 指定位置填充
def fill_binary():
image = np.ones([400, 400, 3], np.uint8)
image[100:300, 100:300, :] = 255
cv.imshow("fill_binary", image)
# zeros和ones不写通道数默认单通道
mask = np.ones([402, 402], np.uint8)
# 将要填充位置的像素设为0
mask[101:301, 101:301] = 0
cv.floodFill(image, mask, (100, 100), (0, 0, 255), cv.FLOODFILL_MASK_ONLY)
cv.imshow("filled binary", image)
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# 第一个使用图片填充,第二个自己在函数内随便建了一个图像进行填充的
fill_color_demo(src)
fill_binary()
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
十一、利用卷积对图像模糊处理
1.均值模糊函数blur():定义:blur(src,ksize,dst=None, anchor=None, borderType=None)
定义是有5个参数,但最后三个均为none,所以也就2个参数
src:要处理的原图像
ksize: 周围关联的像素的范围:代码中(5,5)就是5*5的大小,就是计算这些范围内的均值来确定中心位置的大小
2.中值模糊函数medianBlur(): 定义:medianBlur(src, ksize, dst=None)
ksize与blur()函数不同,不是矩阵,而是一个数字,例如为5,就表示了5*5的方阵
3.高斯平滑函数GaussianBlur():定义:GaussianBlur(src, ksize, sigmaX, dst=None, sigmaY=None, borderType=None)
sigmaX:标准差
4.双边滤波函数bilateralFilter():定义:bilateralFilter(src, d, sigmaColor, sigmaSpace, dst=None, borderType=None)
d:邻域直径
sigmaColor:颜色标准差
sigmaSpace:空间标准差
5.自定义模糊
使用的函数为:filter2D():定义为filter2D(src,ddepth,kernel)
ddepth:深度,输入值为-1时,目标图像和原图像深度保持一致
kernel: 卷积核(或者是相关核),一个单通道浮点型矩阵
修改kernel矩阵即可实现不同的模糊
原图:



lena的加入椒盐噪声的彩色图片没找到,只有找到灰色图像,可以用这个加入椒盐噪声的lena图片对均值和中值进行比较,中值会取得比较好的效果
import cv2 as cv
import numpy as np
# 均值模糊
def blur_demo(image):
# (5,5)分别表示横向和竖向,(5,5)比较常用
dst = cv.blur(image, (5, 5))
cv.imshow("blue_demo", dst)
# 中值模糊,用于处理椒盐噪声,比均值处理效果好
def median_blur_demo(image):
dst = cv.medianBlur(image, 5)
cv.imshow("median_blur_demo", dst)
# 高斯模糊
def gaussian_blur_demo(image):
dst = cv.GaussianBlur(image, (5, 5), 2)
cv.imshow("gaussian_blur_demo", dst)
# 双边滤波
def bilateralFilter_demo(image):
dst = cv.bilateralFilter(image, 5, 5, 2)
cv.imshow("bilateralFilter_demo", dst)
# 自定义模糊、锐化处理;
# 总和为0,做边缘梯度;奇数或者总和为1,做增强,锐化处理
def custom_blur_demo(image):
# 自定义矩阵,并防止数值溢出(第一种表示方法)
# kernel = np.ones([5, 5], np.float32)/25
# (第二种表示方法)
# kernel = np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]], np.float32)/9
# 下方数据为标准的锐化算子(一般数据要求奇数或总和为1)
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]], np.float32)
dst = cv.filter2D(image, -1, kernel=kernel)
cv.imshow("median_blur_demo", dst)
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# 均值模糊
# blur_demo(src)
# 中值模糊
# median_blur_demo(src)
# 高斯模糊
# gaussian_blur_demo(src)
# 双边滤波
# bilateralFilter_demo(src)
# 自定义模糊
custom_blur_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
十二、添加高斯噪声并使用高斯模糊处理
import cv2 as cv
import numpy as np
def clamp(pv):
if pv > 255:
return 255
elif pv < 0:
return 0
else:
return pv
# 增加高斯噪声
def gaussian_noise(image):
h, w, c = image.shape
for row in range(h):
for col in range(w):
s = np.random.normal(0, 20, 3)
b = image[row, col, 0] # blue
g = image[row, col, 1] # green
r = image[row, col, 2] # red
image[row, col, 0] = clamp(b + s[0])
image[row, col, 1] = clamp(g + s[1])
image[row, col, 2] = clamp(r + s[2])
cv.imshow("noise image", image)
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
t1 = cv.getTickCount()
# 增加高斯噪声
gaussian_noise(src)
t2 = cv.getTickCount()
time = (t2 - t1) / cv.getTickFrequency()
print("time consume : %s" % (time*1000))
# 高斯模糊处理,结果说明高斯模糊对高斯噪声有抑制作用
dst = cv.GaussianBlur(src, (5, 5), 0)
cv.imshow("Gaussian Blur", dst)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
结果说明高斯模糊对高斯噪声有抑制作用
十三、边缘保留滤波(EPF)
这个堪比磨皮,非常好玩!
高斯双边
dst = cv.bilateralFilter( src,d,sigmaColor,sigmaSpace [,dst [,borderType]] )
dst也就是输出,和borderType都是可选参数
src
源8位或浮点,1通道或3通道图像。
dst
与src大小和类型相同的目标映像。
d
滤波期间使用的每个像素邻域的直径。如果它不是正值,则从sigmaSpace计算得出。
sigmaColor
在色彩空间中过滤sigma。参数的较大值表示像素邻域内的其他颜色(请参见sigmaSpace)将混合在一起,从而导致较大区域的半均等颜色。
sigmaSpace
在坐标空间中过滤sigma。该参数的值越大,表示越远的像素就会相互影响,只要它们的颜色足够接近即可(请参见sigmaColor)。当d> 0时,它指定邻域大小,而不考虑sigmaSpace。否则,d与sigmaSpace成比例。
borderType
用于推断图像外部像素的边框模式
均值迁移
dst = cv.pyrMeanShiftFiltering( src,sp,sr [,dst [,maxLevel [,termcrit]]] )
dst也就是输出,和maxLevel、termcrit都是可选参数
src
源8位3通道图像。
dst
与源格式和大小相同的目标图像。
SP
空间窗口半径。
SR
彩色窗口半径。
maxLevel
用于分割的金字塔的最高级别。
termcrit
终止标准:何时停止均值漂移迭代。
import cv2 as cv
import numpy as np
# 高斯双边
def bi_demo(image):
dst = cv.bilateralFilter(image, 0, 100, 15)
cv.imshow("bi_demo", dst)
# 均值迁移
def shift_demo(image):
dst = cv.pyrMeanShiftFiltering(image, 10, 50)
cv.imshow("shift_demo", dst)
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
bi_demo(src)
shift_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
运行结果如下:
原图像

高斯双边后图像:

均值迁移后图像:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号