opencv4.2.0.34+python3.8.2+(图像直方图、直方图反向投影、模板匹配、图像二值化、超大图像二值化、高斯金字塔和拉普拉斯金字塔 、图像梯度)
(有的运行结果没弄上去,但文中代码本人亲测均通过;至于有人因版本问题出现个别错误,我相信对于大家应该没什么问题,文档就是很好的辅助学习资料)
十四、图像直方图
(1)安装matplotlib
在cmd环境下,输入命令:pip install matplotlib
(2)绘制直方图
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
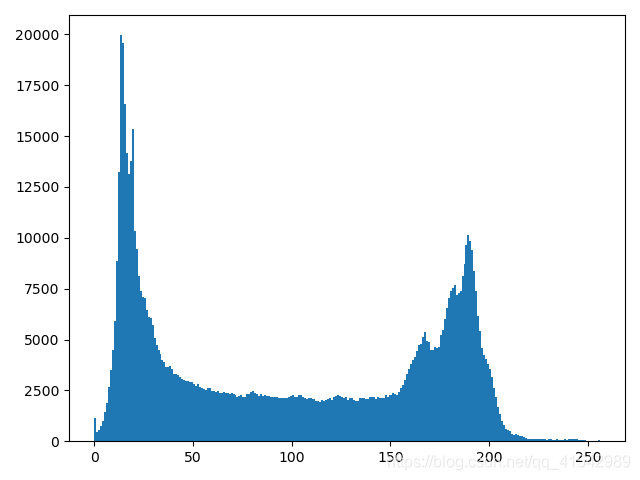
def plot_demo(image):
plt.hist(image.ravel(), 256, [0, 256])
plt.show()
# 画出图像的直方图,相比上个函数,可以控制参数进行干涉,防止失真
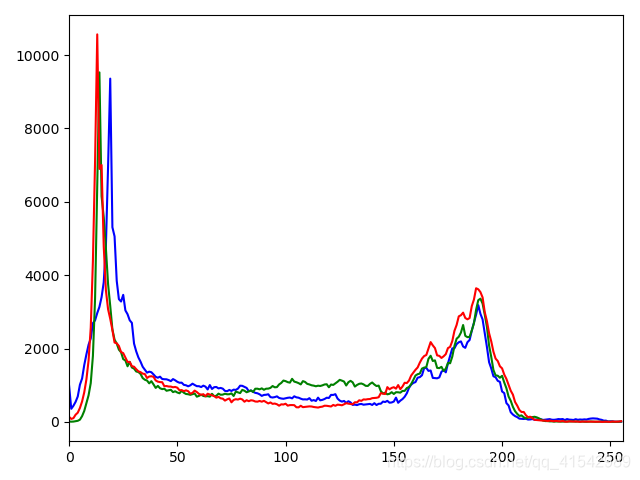
def hist_image(image):
color = ("blue", "green", "red")
for i, color in enumerate(color):
hist = cv.calcHist([image], [i], None, [256], [0, 256])
plt.plot(hist, color=color)
plt.xlim([0, 256])
plt.show()
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# plot_demo(src)
hist_image(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
原图:

plot_demo():
hist_image():
在python中的hist函数参数如下:
hist ( x, bins=None, range=None, normed=False, weights=None, cumulative=False, bottom=None, histtype=‘bar’, align=‘mid’, orientation=‘vertical’, rwidth=None, log=False, color=None, label=None, stacked=False, hold=None, data=None, **kwargs )
下面仅列出一些常用参数,其他参数有待日后补充
x : (n,) array or sequence of (n,) arrays
这个参数是指定每个bin(箱子)分布的数据,对应x轴
bins : integer or array_like, optional
这个参数指定bin(箱子)的个数,也就是总共有几条条状图
normed : boolean, optional
If True, the first element of the return tuple will be the counts normalized to form a probability density, i.e.,n/(len(x)`dbin)
这个参数指定密度,也就是每个条状图的占比例比,默认为1
color : color or array_like of colors or None, optional
这个指定条状图的颜色
facecolor: 直方图颜色
edgecolor: 直方图边框颜色
alpha: 透明度
histtype: 直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’
在python中的calcHist函数参数如下:(实际参数还有很多)
hist = cv.calcHist( images, channels, mask, histSize, ranges[, hist[, accumulate]] )
images
源数组。它们都应具有相同的深度CV_8U,CV_16U或CV_32F和相同的大小。它们每个都可以具有任意数量的通道。
channels
用于计算直方图的暗淡通道列表。第一个数组通道的编号从0到images [0] .channels()-1,第二个数组通道的编号从images [0] .channels()到images [0] .channels()+ images [1]。 channel()-1,依此类推。
mask
可选的面具。如果矩阵不为空,则它必须是与images [i]大小相同的8位数组。非零掩码元素标记在直方图中计数的数组元素。
histSize
每个维度中的直方图大小数组。
ranges
每个维度数组的直方图的边界。当直方图是均匀的(均匀=真)时,对于每个维度i,只需指定第0个直方图bin的下(包括)边界L0和最后一个直方图bin histSize[i]-1的上(独占)边界UhistSize[i]−1。也就是说,在均匀直方图的情况下,范围[i]中的每一个都是2个元素的数组。当直方图不一致时(统一=假),则每个范围[i]包含histSize[i]+1个元素:L0,U0=L1,U1=L2,…,UhistSize[i]−2=LhistSize[i]−1,UhistSize[i]−1。不在L0和UhistSize[i]−1之间的数组元素不在直方图中计数。
hist
输出直方图,它是密集或稀疏的暗维数组。
暗淡 直方图维数必须为正且不大于CV_MAX_DIMS(在当前OpenCV版本中等于32)。
accumulate
累积标志。如果已设置,则分配直方图时不会在开始时清除它。此功能使您可以从几组数组中计算单个直方图,或者及时更新直方图。
plot()函数
plt.plot(x,y,format_string,**kwargs)
说明:
x:x轴数据,列表或数组,可选
y:y轴数据,列表或数组
format_string:控制曲线的格式字符串,可选
**kwargs:第二组或更多,(x,y,format_string)
plot函数具体学习可参考该篇文章
【https://blog.csdn.net/skyli114/article/details/77508136】
xlim()函数:用于设置当前x轴的范围
(3)直方图应用(均衡化和比较)
直方图均衡化: 主要用于增强动态范围较小的图像的灰度反差,该方法的基本思想是把原始图像的直方图变换为均匀分布的形式,这样就增加了像素灰度值的动态范围,从而达到增强图像整体对比度的目的。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
# 直方图均衡化仅可以用于灰度图像,可达到对比度增强效果
def equalHist_demo(image):
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
dst = cv.equalizeHist(gray)
cv.imshow("equalHist_demo", dst)
# 局部直方图均衡化(自定义参数),防止过于失真
def clahe_demo(image):
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
# clipLimit是对比度的大小,tileGridSize是每次处理块的大小
clahe = cv.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
dst = clahe.apply(gray)
cv.imshow("clahe_demo", dst)
src = cv.imread("D:/image/lena_gray.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
equalHist_demo(src)
clahe_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
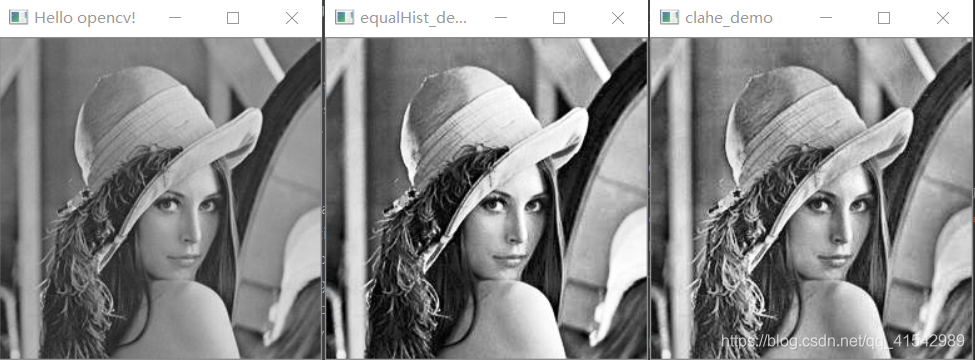
直方图比较:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
# 直方图比较
def create_rgb_hist(image):
h, w, c = image.shape
# 必须是float32,否则在hist_compare中compareHist函数会出错
rgbHist = np.zeros([16*16*16, 1], np.float32)
bsize = 256 / 16
for row in range(h):
for col in range(w):
b = image[row, col, 0]
g = image[row, col, 1]
r = image[row, col, 2]
index = np.int(b/bsize)*16*16 + np.int(g/bsize)*16 + np.int(r/bsize)
rgbHist[np.int(index), 0] +=1
return rgbHist
def hist_compare(image1, image2):
hist1 = create_rgb_hist(image1)
hist2 = create_rgb_hist(image2)
# 巴氏距离(数值越小,越相似)
match1 = cv.compareHist(hist1, hist2, cv.HISTCMP_BHATTACHARYYA)
# 相关性(数值越大,越相似)
match2 = cv.compareHist(hist1, hist2, cv.HISTCMP_CORREL)
# 卡方(数值越小,越相似)
match3 = cv.compareHist(hist1, hist2, cv.HISTCMP_CHISQR)
print("巴氏距离: %s, 相关性: %s, 卡方: %s" % (match1, match2, match3))
# 两张图片大小最好一样,如果不一样,最后要做归一化处理,该代码中未给出
img1 = cv.imread("D:/image/lena_gray.jpg")
cv.imshow("img1", img1)
img2 = cv.imread("D:/image/lena_pepper_salt.jpg")
cv.imshow("img2", img2)
hist_compare(img1, img2)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
十五、直方图反向投影
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
# 2D直方图反向投影
def back_projection_demo():
sample = cv.imread("D:/image/sample.jpg")
target = cv.imread("D:/image/target.jpg")
# 1.转换到色彩空间
roi_hsv = cv.cvtColor(sample, cv.COLOR_RGB2HSV)
target_hsv = cv.cvtColor(target, cv.COLOR_RGB2HSV)
# show images
cv.imshow("sample", sample)
cv.imshow("target", target)
# 2.生成样本的直方图
# [180, 256]值如果调小,那么bins值就会缩小,反向投影效果更好,bins值可以理解为x轴和y轴
roiHist = cv.calcHist([roi_hsv], [0, 1], None, [32, 32], [0, 180, 0, 256])
# 3.对样本的直方图做归一化处理到0-255之间,下方两种方式都可以,但是第一种效果更好,原因暂时未知。
cv.normalize(roiHist, roiHist, 255, cv.NORM_MINMAX)
# roiHist = cv.normalize(roiHist, 255, cv.NORM_MINMAX)
# 4.直方图反向投影。最后一个1代表大小不需要放缩
dst = cv.calcBackProject([target_hsv], [0, 1], roiHist, [0, 180, 0, 256], 1)
cv.imshow("backProjectionDemo", dst)
# 2D直方图显示
def hist2d_demo(image):
hsv = cv.cvtColor(image, cv.COLOR_RGB2HSV)
# 该处使用了hsv的h和s维度的空间,所以是[0, 1],h维度最大180,s和v都是255
hist = cv.calcHist([hsv], [0, 1], None, [32, 32], [0, 180, 0, 256])
# cv.imshow("hist2d", hist)
plt.imshow(hist, interpolation='nearest')
plt.title("2D Histogram")
plt.show()
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# hist2d_demo(src)
back_projection_demo()
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
hist2d_demo(src)函数的运行结果如下:
原图:
hist = cv.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
![[180, 256]](https://img-blog.csdnimg.cn/20200710180658856.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNTQyOTg5,size_16,color_FFFFFF,t_70)
hist = cv.calcHist([hsv], [0, 1], None, [32, 32], [0, 180, 0, 256])
![[32, 32]](https://img-blog.csdnimg.cn/20200710180725129.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNTQyOTg5,size_16,color_FFFFFF,t_70)
可以看出,当bins值比较小的时候,直方图会更加具体,出现像素块,而且对于反向效果会更显著(如下)
back_projection_demo()运行结果如下:
sample:
target:
roiHist = cv.calcHist([roi_hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])结果如下:
![[180, 256]](https://img-blog.csdnimg.cn/20200710184100910.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNTQyOTg5,size_16,color_FFFFFF,t_70)
roiHist = cv.calcHist([roi_hsv], [0, 1], None, [32, 32], [0, 180, 0, 256])结果如下:
![[32, 32]](https://img-blog.csdnimg.cn/20200710184218901.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNTQyOTg5,size_16,color_FFFFFF,t_70)
可见将bins值调小,可以很好的进行直方图的反向投影,效果更加的显著
十六、模板匹配
模式匹配的算法很多(有兴趣的可以具体了解),cv.TM_SQDIFF_NORMED, cv.TM_CCORR_NORMED, cv.TM_CCOEFF_NORMED,本文用到这三个:

1. CV_TM_SQDIFF 平方差匹配法:该方法采用平方差来进行匹配;最好的匹配值为0;匹配越差,匹配值越大。
2. CV_TM_CCORR 相关匹配法:该方法采用乘法操作;数值越大表明匹配程度越好。
3. CV_TM_CCOEFF 相关系数匹配法:1表示完美的匹配;-1表示最差的匹配。
4. CV_TM_SQDIFF_NORMED 归一化平方差匹配法
5. CV_TM_CCORR_NORMED 归一化相关匹配法
6. CV_TM_CCOEFF_NORMED 归一化相关系数匹配法
1和4方法为越小的值表示越匹配,其他四种方法值越大越匹配。
1. matchTemplate()函数如下
void cv::matchTemplate ( InputArray image,
InputArray templ,
OutputArray result,
int method,
InputArray mask = noArray()
)
Python:
result = cv.matchTemplate( image, templ, method[, result[, mask]] )
image
搜索正在运行的图像。它必须是8位或32位浮点。
templ
搜索的模板。它必须不大于源图像并且具有相同的数据类型。
result
比较结果图。它必须是单通道32位浮点。如果图像是w ^× 高 和庙会是 瓦特× ħ ,则结果是 (W- 瓦特+ 1 )× (ħ− h + 1 ) 。
method
指定比较方法的参数,请参见TemplateMatchModes
mask
搜索模板的掩码。它必须与templ具有相同的数据类型和大小。默认情况下未设置。当前,仅支持TM_SQDIFF和TM_CCORR_NORMED方法。这是opencv4.2情况下,后序版本可能支持的算法会增多
2. minMaxLoc()函数如下:
void cv::minMaxLoc ( InputArray src,
double * minVal,
double * maxVal = 0,
Point * minLoc = 0,
Point * maxLoc = 0,
InputArray mask = noArray()
)
Python:
minVal, maxVal, minLoc, maxLoc = cv.minMaxLoc( src[, mask] )
src
输入单通道数组。
minVal
指向返回的最小值的指针;如果不需要,则使用NULL。
maxVal
指向返回的最大值的指针;如果不需要,则使用NULL。
minLoc
指向返回的最小位置的指针(在2D情况下);如果不需要,则使用NULL。
maxLoc
指向返回的最大位置的指针(在2D情况下);如果不需要,则使用NULL。
mask
用于选择子阵列的可选掩码。
3. rectangle()函数如下:
void cv::rectangle ( InputOutputArray img,
Point pt1,
Point pt2,
const Scalar & color,
int thickness = 1,
int lineType = LINE_8,
int shift = 0
)
Python(本文使用第一种):
img = cv.rectangle( img, pt1, pt2, color[, thickness[, lineType[, shift]]] )
img = cv.rectangle( img, rec, color[, thickness[, lineType[, shift]]] )
img 图片。
pt1 矩形的顶点。
pt2 与pt1相反的矩形的顶点。
color 矩形的颜色或亮度(灰度图像)。
thickness
组成矩形的线的粗细。负值(如FILLED)表示该函数必须绘制一个填充的矩形。
lineType 线的类型。查看线型(可自行搜索相关资料,应该是4种)
shift 点坐标中的小数位数。
import cv2 as cv
import numpy as np
def template_demo():
tpl = cv.imread("D:/image/IU_eye.jpg")
target = cv.imread("D:/image/IU.jpg")
cv.imshow("template image", tpl)
cv.imshow("target image", target)
methods = [cv.TM_SQDIFF_NORMED, cv.TM_CCORR_NORMED, cv.TM_CCOEFF_NORMED]
th, tw = tpl.shape[:2]
for md in methods:
# 对每一个算法(md)进行匹配
print(md)
# 第一个参数是目标图像,第二个参数是模板,第三个图像是匹配算法,返回匹配的结果
result = cv.matchTemplate(target, tpl, md)
# 返回的最小值和最大值指针以及返回的最小、最大位置的指针
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(result)
# 如果是平方差匹配法设置tl为min_loc,其他设置为max_loc,至于为什么这样设置,可能和算法有关系,具体情况暂时未知
if md == cv.TM_SQDIFF_NORMED:
tl = min_loc
else:
tl = max_loc
# tl是左上角的那个点,br是右下角的那个点
br = (tl[0] + tw, tl[1] + th)
cv.rectangle(target, tl, br, (0, 255, 0), 0)
cv.imshow("match-" + np.str(md), target)
# 保存图像 cv.imwrite("D:/image/match-" + np.str(md) + ".jpg", target)
# 下方展示result图像
# cv.imshow("match-" + np.str(md), result)
# src = cv.imread("D:/image/dingxia.jpg")
# cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
# cv.imshow("Hello opencv!", src)
template_demo()
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
结果如下:
tpl图:
target图:
三种匹配结果:
1 3 5序号分别对应我的三种算法,没有为什么,pycharm中输出的也是这个意思

算法1的结果图:

算法3的结果图:

算法5的结果图:

cv.imshow(“match-” + np.str(md), result)该函数输出是三个黑白色图像(这里就不放图片了~):
可以参考0-255像素值,越接近0越黑,越接近255越白,就是值越大越白
对于第一个算法,最好的匹配值是0,所以该图像最黑的地方就是目标位置
对于第二个算法,匹配值越大匹配效果越好,所以该图像最白的地方就是目标位置
对于第三个算法,最好的匹配值是1,匹配值越大匹配效果越好,所以该图像最白的地方就是目标位置
其实模板匹配的使用和直方图反向投影calcBackProject函数很像,只是直方图反向投影对比的是直方图,而模板匹配对比的是图像的像素值,相比较而言,直方图反向投影的匹配鲁棒性更好。
总结这个函数,感觉功能不是很强大,应用不是很广,因为只能在图像中搜索出指定的模板,如果模板是从待搜索目标中截取出来的,效果会很好,如果模板不是待搜素图像的一部分,效果就差的多了,所以该函数的使用还是有很大的局限性。
十七、图像二值化
图像二值化:基于图像的直方图来实现的,0白色 1黑色
包含全局、局部和自定义阈值二值化
import cv2 as cv
import numpy as np
# 全局阈值二值化
def threshold_demo(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# 1. THRESH_OTSU和THRESH_TRIANGLE是两种阈值化方法,将大于阈值设置为白色,小于阈值设置为黑色
# 大律法THRESH_OTSU适用于直方图有多个波峰的图像,而THRESH_TRIANGLE适用于直方图有单个波峰的图像
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_TRIANGLE)
# 2. 如果要自己指定阈值,后面的阈值化方法就要去掉,第二个参数代表阈值,大于127的是白色 小于的是黑色
# ret, binary = cv.threshold(gray, 127, 255, cv.THRESH_BINARY)
# 3. THRESH_BINARY_INV方法表示将黑与白调换,大于127的是黑色 小于的是白色
# ret, binary = cv.threshold(gray, 127, 255, cv.THRESH_BINARY_INV)
# 4. THRESH_TRUNC表示截断,大于指定阈值127的设置为指定阈值127,小于指定阈值127的不变
# ret, binary = cv.threshold(gray, 127, 255, cv.THRESH_TRUNC)
# 5. THRESH_TOZERO小于指定阈值的设置为0黑色,大于指定阈值的不变
# ret, binary = cv.threshold(gray, 127, 255, cv.THRESH_TOZERO)
print("threshold value %s" % ret)
cv.imshow("binary", binary)
# 局部阈值二值化
def local_threshold(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# dst = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 25, 10)
# 高斯阈值ADAPTIVE_THRESH_GAUSSIAN_C
binary = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 25, 10)
cv.imshow("binary", binary)
# 自定义阈值
def custom_threshold(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
h, w = gray.shape[:2]
# 化为一维数组
m = np.reshape(gray, [1, w*h])
# 计算数组元素的总和。
# 函数sum针对每个通道独立计算并返回数组元素的总和。
# 参量 src 输入数组必须具有1到4个通道。
mean = m.sum() / (w*h)
print("mean :", mean)
ret, binary = cv.threshold(gray, mean, 255, cv.THRESH_BINARY)
cv.imshow("binary", binary)
src = cv.imread("D:/image/dingxia.jpg")
cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
cv.imshow("Hello opencv!", src)
# threshold_demo(src)
# local_threshold(src)
custom_threshold(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
全局阈值化:
threshold()
double cv::threshold ( InputArray src,
OutputArray dst,
double thresh,
double maxval,
int type
)
Python:
retval, dst = cv.threshold( src, thresh, maxval, type[, dst] )
src 输入数组(多通道,8位或32位浮点)。
dst 与src具有相同大小,类型和相同通道数的输出数组。
thresh 阈值。
maxval THRESH_BINARY和THRESH_BINARY_INV阈值类型使用的最大值。
type 阈值类型
局部阈值化:
adaptiveThreshold()
void cv::adaptiveThreshold ( InputArray src,
OutputArray dst,
double maxValue,
int adaptiveMethod,
int thresholdType,
int blockSize,
double C
)
Python:
dst = cv.adaptiveThreshold( src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst] )
src 源8位单通道图像。
dst 与src具有相同大小和相同类型的目标图像。
maxValue 分配给满足条件的像素的非零值
adaptiveMethod 要使用的自适应阈值算法
thresholdType 阈值类型必须为THRESH_BINARY或THRESH_BINARY_INV
blockSize 用于计算像素阈值的像素邻域的大小:3、5、7等。必须是奇数
C 从平均值或加权平均值中减去常数。通常,它为正,但也可以为零或负。
十八、超大图像二值化
import cv2 as cv
import numpy as np
def super_image_binary(image):
ch = 256
cw = 256
h, w = image.shape[:2]
gray = cv.cvtColor(image, cv.COLOR_RGB2GRAY)
for row in range(0, h, cw):
for col in range(0, w, ch):
roi = gray[row:row+cw, col:col+ch]
# 1. 全局阈值,效果不太好
# ret, binary = cv.threshold(roi, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# gray[row:row+cw, col:col+ch] = binary
# 2. 局部阈值方法,效果比较好,个人喜欢局部阈值,感觉效果更好
# binary = cv.adaptiveThreshold(roi, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 127, 10)
# gray[row:row+cw, col:col+ch] = binary
# 3. 全局阈值方法,换一种做法,通过图像空白过滤,效果和局部效果差不多,但标准差小于的值是要自己一个一个尝试的,比较麻烦
dev = np.std(roi)
if dev < 15:
gray[row:row+cw, col:col+ch] = 255
else:
ret, binary = cv.threshold(roi, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
gray[row:row + cw, col:col + ch] = binary
# mean均值,var方差,std标准差
# print(np.std(binary), np.mean(binary))
cv.imwrite("D:/image/IU.small.jpg", gray)
src = cv.imread("D:/image/IU.jpg")
# cv.namedWindow("Hello opencv!", cv.WINDOW_AUTOSIZE)
# cv.imshow("Hello opencv!", src)
super_image_binary(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
十九、高斯金字塔和拉普拉斯金字塔
拉普拉斯金字塔时,图像大小必须是2的n次方*2的n次方,不然会报错
(pyrDown-高斯滤波+降采样,pyrUp-扩大+高斯还原)
高斯金字塔算法流程:
(1)对图像进行高斯卷积(高斯滤波)
(2)删除偶数行和偶数列(降采样)
拉普拉斯金字塔算法流程:(用于低分辨率恢复高分辨率图像时计算残差)
对于高斯金字塔中的低分辨率图像,
(1)先将图像每个方向放大至原来的两倍(上采样),新增的行和列以0填充
(2)对图像进行高斯卷积(高斯滤波)
(3)用下一层的高分辨率图像减去高斯卷积后的图像
import cv2 as cv
import numpy as np
# 高斯金字塔
def pyramid_demo(image):
level = 3
temp = image.copy()
pyramid_images = []
for i in range(level):
dst = cv.pyrDown(temp)
pyramid_images.append(dst)
cv.imshow("pyramid_demo_" + str(i), dst)
temp = dst.copy()
return pyramid_images
# 拉普拉斯金字塔
def lapalian_demo(image):
pyramid_images = pyramid_demo(image)
level = len(pyramid_images)
for i in range(level-1, -1, -1):
if (i-1) < 0:
expand = cv.pyrUp(pyramid_images[i], dstsize=image.shape[:2])
lpls = cv.subtract(image, expand)
cv.imshow("lapalian" + str(i), lpls)
else:
expand = cv.pyrUp(pyramid_images[i], dstsize=pyramid_images[i-1].shape[:2])
lpls = cv.subtract(pyramid_images[i-1], expand)
cv.imshow("lapalian" + str(i), lpls)
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("lena!", cv.WINDOW_AUTOSIZE)
cv.imshow("lena!", src)
# pyramid_demo(src)
lapalian_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
二十、图像梯度
作用:反映像素梯度的变化
(1)Sobel算子
Sobel()
void cv::Sobel (
InputArray src,
OutputArray dst,
int ddepth,
int dx,
int dy,
int ksize = 3,
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
Python:
dst = cv.Sobel( src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]] )
src 输入图像。
dst 输出与src相同大小和相同通道数的图像。
ddepth 输出图像深度;对于8位输入图像,它将导致导数被截断。
dx 导数x的阶数。
dy 导数y的阶数。
ksize 扩展的Sobel内核的大小;它必须是1、3、5或7。
scale 计算的导数值的可选比例因子;默认情况下,不应用任何缩放
delta 在将结果存储到dst之前将其添加到结果中的可选增量值。
borderType 像素外推方法
(2)convertScaleAbs()函数
convertScaleAbs()
void cv::convertScaleAbs ( InputArray src,
OutputArray dst,
double alpha = 1,
double beta = 0
)
Python:
dst = cv.convertScaleAbs( src[, dst[, alpha[, beta]]] )
在输入数组的每个元素上,函数convertScaleAbs依次执行三个操作:缩放,获取绝对值,转换为无符号的8位类型:
src 输入的数组
dst 输出的数组
alpha 可选比例因子。
beta 可选增量添加到缩放值。
(3)addWeighted()函数
addWeighted()
void cv::addWeighted ( InputArray src1,
double alpha,
InputArray src2,
double beta,
double gamma,
OutputArray dst,
int dtype = -1
)
Python:
dst = cv.addWeighted( src1, alpha, src2, beta, gamma[, dst[, dtype]] )
作用:计算两个数组的加权和。
公式:dst = src1 * alpha + src2 * beta + gamma;
src1 第一个输入数组。
alpha 第一个数组元素的权重。
src2 第二个输入数组,其大小和通道号与src1相同。
beta 第二个数组元素的权重。
gamma 标量添加到每个和。
dst 输出数组,其大小和通道数与输入数组相同。
dtype 输出数组的可选深度;当两个输入数组的深度相同时,可以将dtype设置为-1,这等效于src1.depth()。
(4) 拉普拉斯算子
Laplacian()
void cv::Laplacian ( InputArray src,
OutputArray dst,
int ddepth,
int ksize = 1,
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
Python:
dst = cv.Laplacian( src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]]
src 源图像。
dst 与src相同大小和相同通道数的目标图像。
ddepth 所需目标图像的深度。
ksize 用于计算二阶导数滤波器的孔径大小。有关详细信息,请参见getDerivKernels。大小必须为正数和奇数。
scale 计算的Laplacian值的可选比例因子。默认情况下,不应用缩放。有关详细信息,请参见getDerivKernels。
delta 在将结果存储到dst之前将其添加到结果中的可选增量值。
borderType 像素外推方法
(5)filter2D()函数: 将图像与内核卷积。
filter2D()
void cv::filter2D ( InputArray src,
OutputArray dst,
int ddepth,
InputArray kernel,
Point anchor = Point(-1,-1),
double delta = 0,
int borderType = BORDER_DEFAULT
)
Python:
dst = cv.filter2D( src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]] )
src 输入图像。
dst 输出与src具有相同大小和相同通道数的图像。
ddepth 目标图像的所需深度,请参见
kernel 卷积核(或更确切地说是相关核),单通道浮点矩阵;如果要将不同的内核应用于不同的通道,请使用split将图像划分为单独的色彩平面,并分别进行处理。
anchor 内核的锚点,指示内核中已过滤点的相对位置;锚点应位于内核内;默认值(-1,-1)表示锚位于内核中心。
delta 在将像素存储到dst中之前将其添加到过滤的像素的可选值。
borderType 像素外推方法
import cv2 as cv
import numpy as np
# Laplacian 拉普拉斯算子
def lapalian_demo(image):
# dst = cv.Laplacian(image, cv.CV_32F)
# lpls = cv.convertScaleAbs(dst)
# 自定义卷积核
# kernel = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]]) 四领域算子,和Laplacian效果差不多,说明Laplacian默认使用四领域算子
# 八领域算子,四领域的增强版
kernel = np.array([[1, 1, 1], [1, -8, 1], [1, 1, 1]])
dst = cv.filter2D(image, cv.CV_32F, kernel=kernel)
lpls = cv.convertScaleAbs(dst)
cv.imshow("lapalian_demo", lpls)
# sobel 索贝尔算子
def sobel_image(image):
# Scharr是Sobel的增强版
grad_x = cv.Scharr(image, cv.CV_32F, 1, 0)
grad_y = cv.Scharr(image, cv.CV_32F, 0, 1)
# grad_x = cv.Sobel(image, cv.CV_32F, 1, 0)
# grad_y = cv.Sobel(image, cv.CV_32F, 0, 1)
gradx = cv.convertScaleAbs(grad_x)
grady = cv.convertScaleAbs(grad_y)
cv.imshow("gradient-x", gradx)
cv.imshow("gradient-y", grady)
gradxy = cv.addWeighted(gradx, 0.5, grady, 0.5, 0)
cv.imshow("gradient", gradxy)
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("lena!", cv.WINDOW_AUTOSIZE)
cv.imshow("lena!", src)
# sobel_image(src)
lapalian_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
二十一、Canny边缘检测算法
五步:
1.高斯模糊-GaussianBlur
2.灰度转换-cvtColor
3.计算梯度-Sobel/Scharr
4.非最大信号抑制
5.高低阈值输出二值图像
非最大信号抑制:
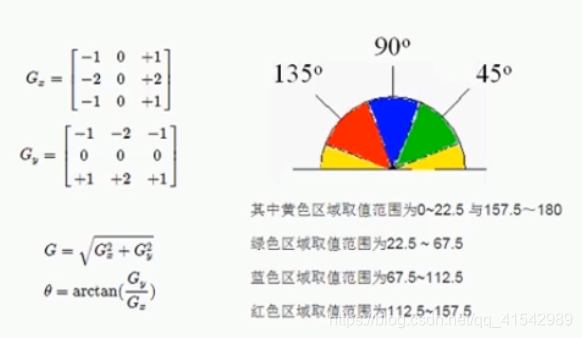
高低阈值链接:

(第四步和第五步不是很理解,日后补充)
算法参考资料:https://www.cnblogs.com/mightycode/p/6394810.html
Canny() 函数
void cv::Canny ( InputArray image,
OutputArray edges,
double threshold1,
double threshold2,
int apertureSize = 3,
bool L2gradient = false
)
Python:
edges = cv.Canny( image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]] )
edges = cv.Canny( dx, dy, threshold1, threshold2[, edges[, L2gradient]] )
两种实现方法
第一种参数如下:
image 8位输入图像。
edges 输出边缘图;单通道8位图像,其大小与image相同。
threshold1 磁滞过程的第一阈值。
threshold2 磁滞过程的第二阈值。
apertureSize Sobel操作的光圈大小。(Sobel是以某一光圈从左到右,从上到下依次判断)
L2gradient 一个标志,指示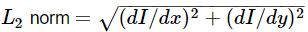 应该用来计算图像的梯度大小( L2gradient=true ), 或者是否违约
应该用来计算图像的梯度大小( L2gradient=true ), 或者是否违约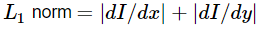 就够了 ( L2gradient=false ).
就够了 ( L2gradient=false ).
第二种参数如下:
dx 输入图像的16位x导数(CV_16SC1或CV_16SC3)。
dy 输入图像的16位y导数(与dx类型相同)。
edges 输出边缘图;单通道8位图像,其大小与image相同。
threshold1 磁滞过程的第一阈值。
threshold2 磁滞过程的第二阈值。
L2gradient 一个标志,指示应该用来计算图像的梯度大小( L2gradient=true ), 或者是否违约 就够了 ( L2gradient=false ).
import cv2 as cv
import numpy as np
def edge_demo(image):
# 1.高斯模糊-GaussianBlur,Canny对噪声比较铭感,而且Canny没有自带的高斯模糊处理,所以需要先使用高斯模糊降噪一下
blurred = cv.GaussianBlur(image, (3, 3), 0)
# 2.灰度转换-cvtColor
gray = cv.cvtColor(blurred, cv.COLOR_BGR2GRAY)
# 3.计算梯度-Sobel/Scharr
xgrad = cv.Sobel(gray, cv.CV_16SC1, 1, 0)
ygrad = cv.Sobel(gray, cv.CV_16SC1, 0, 1)
# 4.非最大信号抑制
# 5.高低阈值输出二值图像
# edge_output = cv.Canny(xgrad, ygrad, 50, 150)
# 直接用灰度图像也可以
edge_output = cv.Canny(gray, 50, 150)
cv.imshow("Canny Edge", edge_output)
# 彩色边缘图像 与或非都可以尝试一下,结果不同
dst = cv.bitwise_and(image, image, mask=edge_output)
# dst = cv.bitwise_not(image, mask=edge_output)
# dst = cv.bitwise_or(image, image, mask=edge_output)
# 异或出不来
# dst = cv.bitwise_xor(image, image, mask=edge_output)
cv.imshow("Color Edge", dst)
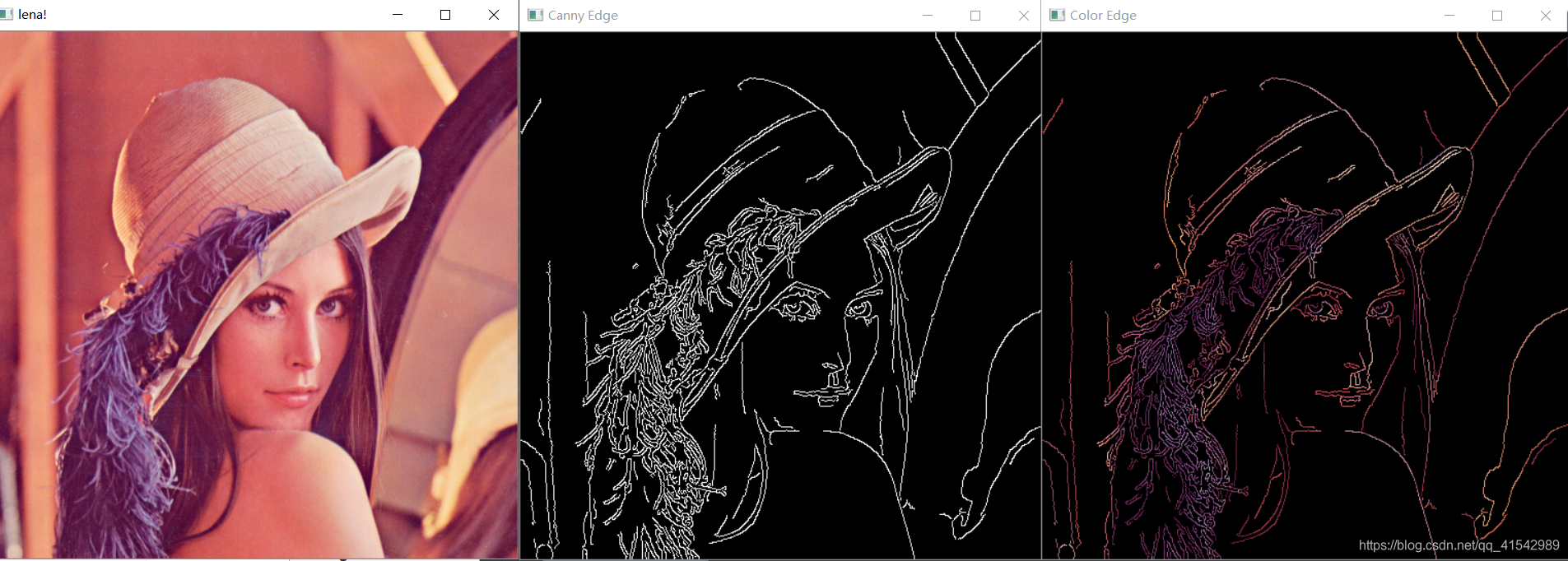
src = cv.imread("D:/image/lena.jpg")
cv.namedWindow("lena!", cv.WINDOW_AUTOSIZE)
cv.imshow("lena!", src)
edge_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
print("Hi,Python!")
结果如下: