线段树初步
0、更新日志
2021.12.11 纠正了“3、实现”部分存在的的小问题;增加了 “0、更新日志”
2021.7.29 首次发布本文
感谢
1、综述
假设有编号从1到
线段树的用处就是,对编号连续的一些点进行修改或者统计操作,修改和统计的复杂度都是
线段树的原理,就是将[1,n]分解成若干特定的子区间(数量不超过
由此看出,用线段树统计的东西,必须符合区间加法,否则,不可能通过分成的子区间来得到[L,R]的统计结果。
符合区间加法的例子:
-
数字之和——总数字之和 = 左区间数字之和 + 右区间数字之和
-
最大公因数(GCD)——总GCD = gcd( 左区间GCD , 右区间GCD );
-
最大值——总最大值=max(左区间最大值,右区间最大值)
不符合区间加法的例子:
-
众数——只知道左右区间的众数,没法求总区间的众数
-
01序列的最长连续零——只知道左右区间的最长连续零,没法知道总的最长连续零
一个问题,只要能化成对一些连续点的修改和统计问题,基本就可以用线段树来解决了
2、原理 & 结构
线段树是一种基于分治思想的二叉树结构,用于在区间上进行信息统计。与树状数组相比,线段树是一种更加通用的结构:
-
线段树的每个节点代表一个区间
-
线段树具有唯一的根节点,代表的区间是整个统计范围,如 [1,N]
-
线段树的每个叶节点都代表一个长度为1的元区间 [x,x]。
-
对于每个内部节点[l,r],它的左子节点是[l,mid],右子节点是[mid+1,r],其中
- 区间视角
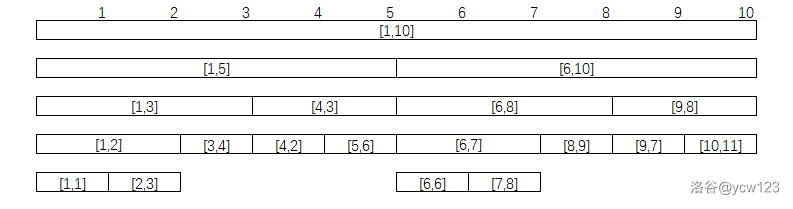
- 二叉树视角
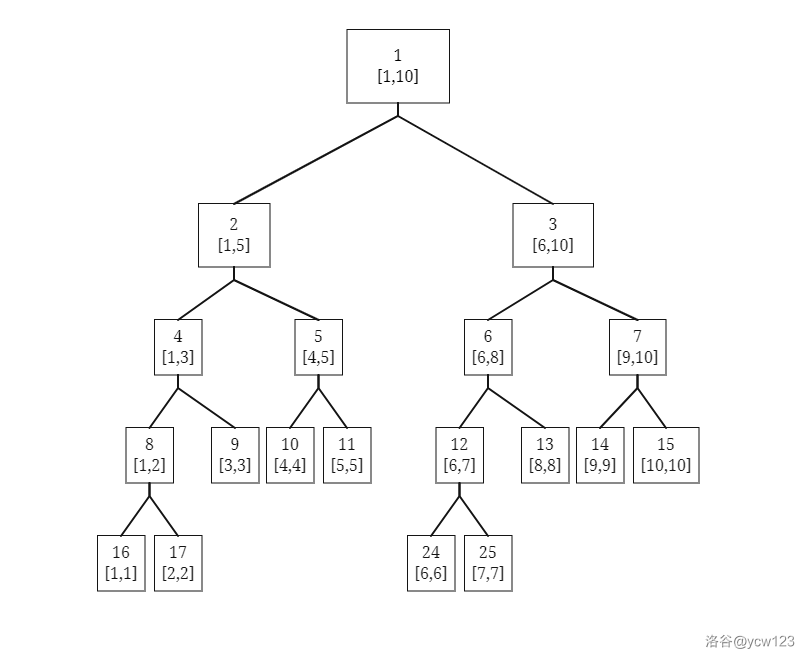
上图展示了一棵线段树。可以发现,去除树的最后一层,整棵线段树一定是一颗完全二叉树,树的深度为
- 根节点编号为1。
- 编号为
这样一来我们就能简单的使用一个 struct 数组来保存线段树。当然,树的最后一层节点在数组中保存的位置不是连续的,直接空出数组中多余的位置即可。
在理想情况下,
3、实现
- 线段树的建树
线段树的基本用途是对序列进行维护,支持查询与修改指令。
给定一个长度为
显然
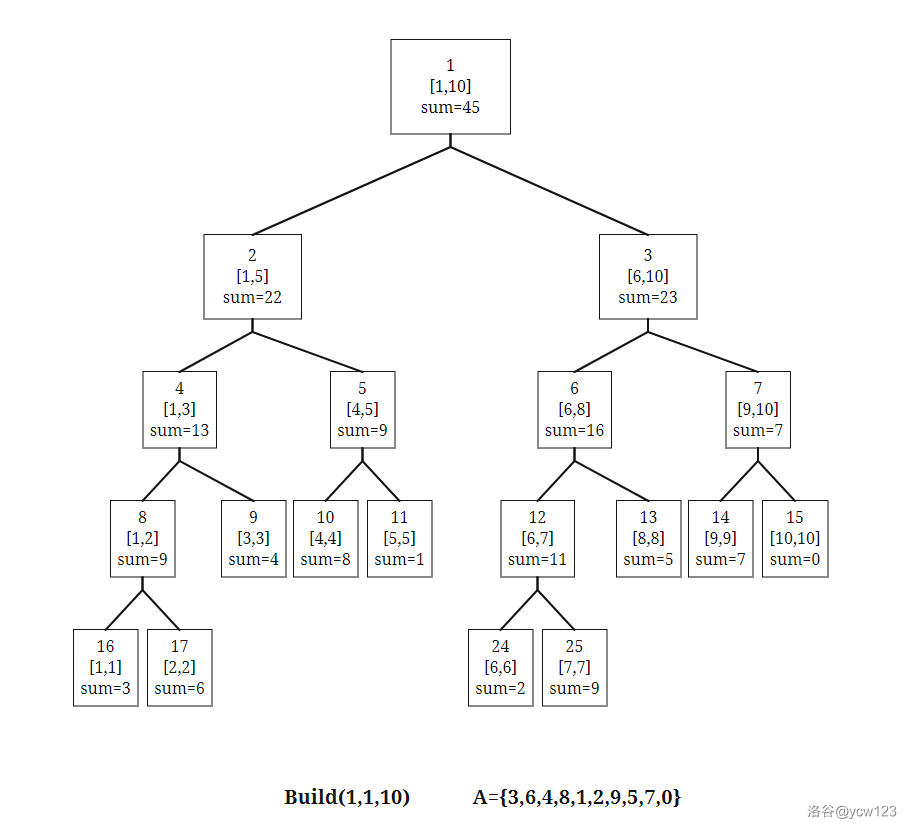
下面这段代码建立了一颗线段树并在每个节点上保存了对应区间的和。
struct Tree {
int l,r;
int sum;
} t[SIZE*4]; //struct数组存储线段树
void Pushup(int x){
t[x].sum = t[x*2].sum + t[x*2+1].sum;
}
void build(int x, int l, int r) {
t[x].l = l, t[x].r = r; //节点x代表区间[l,r]
if (l==r) { t[x].sum = a[l]; return; } //叶节点
int mid = (l + r) / 2; //折半
build(x*2, l, mid); //左子节点[l,mid],编号 x*2
build(x*2+1, mid+1, r); //右子节点[mid+1,r],编号 x*2+1
Pushup(x); //更新函数,从下往上传递信息
}
build(1, 1, n); //调用入口
- 线段树的单点修改
单点修改是形如“ C p k ”的指令,表示把
在线段树中,根节点(编号为1的节点)是执行各种指令的入口。我们需要从根节点出发,递归找到代表区间 [p,p] 的叶节点,然后从下往上更新 [p,p] 以及它的所有祖先节点上保存的信息,如下图所示。时间复杂度为 O(log2(N))。
void Pushup(int x){ //更新信息函数
t[x].sum = t[x*2].sum + t[x*2+1].sum;
}
void updata(int x,int p,int k){
if (t[x].l == t[x].r) { t[x].sum += k; return; } //找到叶节点
int mid = (t[x].l + t[x].r) / 2;
if (p <= mid) updata(x*2,p,k); //x属于左半区间
else updata(x*2+1,p,k); //x属于右半区间
Pushup(x); //从下往上更新信息
}
updata(1,p,k);
- 线段树的区间查询
区间查询是形如一条“Q l r”的指令,例如查询序列A在区间 [l,r] 上的和。我们只需要从根节点开始,递归执行以下过程:
- 若 [l,r] 完全覆盖了当前节点代表的区间,则立即回溯,并且答案加上该节点的sum值。
- 递归访问两个子节点,若与 [l,r] 无交集,则立即回溯,返回零。
int query(int x, int l, int r){
if (t[x].l > r || t[x].r < l) return 0; //与[l,r]无交集
if (t[x].l >= l && t[x].r <= r) return t[x].sum; //完全包含
return query(x*2, l, r) + query(x*2+1, l, r); //递归两个子节点
}
printf("%d\n",query(1,l,r)) //调用入口
该查询过程会把询问区间 [l,r] 在线段树上分成
为什么是
-
-
(1).
(2).
-
-
(1).
(2).
也就是说,只有情况4(2)会真正产生对左两棵子树的递归。
请读者思考,这种情况至多发生一次,之后在子节点上就会变成情况2或3。
因此,上述查询过程的时间复杂度为
从宏观上解,相当于
- 线段树的区间修改
在线段树的“区间查询”指令中,每当遇到被问区间 [l,r] 完全覆盖的节点时可以立即把该节点上存储的信息回溯。我们已经证明,被询问区间 [l,r] 在线段树上会被分成
不过,在“区间修改”指令中,如果某个节被修改区间 [l,r] 完全覆盖,那么以该节点为根的整棵子树中的所有节点存储的信息会发生变化,若逐一进行更新,将使得一次区间修改指令的时间复杂度增加到
试想,如果我们在一次修改指令中发现节点代表的区间 [pl,pr] 被修改区间 [l,r] 完全覆盖,并且逐一更新了子树
换言之,我们在执行修改指令时,同样可以在
如果在后续的指令中,需要从节点
也就是说,除了在修改指令中直接划分成的
这样一来,每条查询或修改指令的时间复杂度都降低到了
延迟标记提供了线段树中从上往下传递信息的方式。这“延迟”也是设计算法与解决问题的一个重要思路。
标记有相对标记和绝对标记之分:
相对标记是将区间的所有数
所以,可以在区间修改的时候不下推标记,留到查询的时候再下推。
注意:如果区间修改时不下推标记,那么Pushup函数中,必须考虑本节点的标记。而如果所有操作都下推标记,那么Pushup函数可以不考虑本节点的标记,因为本节点的标记一定已经被下推了(也就是对本节点无效了)
绝对标记是将区间的所有数变成
注意:有多个标记的时候,标记下推的顺序也很重要,错误的下推顺序可能会导致错误。
再以区间求和为例:
void Pushdown(int x){ //下推标记函数
t[x*2].add += t[x].add;
t[x*2+1].add += t[x].add;
t[x*2].sum += t[x].add*(t[x*2].r - t[x*2].l + 1);
t[x*2+1].sum += t[x].add*(t[x*2+1].r - t[x*2+1].l + 1);
t[x].add=0;
}
void updata(int x, int k, int l, int r){
if(l>t[x].r||r<t[x].l) return; //无交集
if(l<=t[x].l&&r>=t[x].r){ //完全包含
t[x].add += k;
t[x].sum += (t[x].r - t[x].l + 1) * k;
return;
}
Pushdown(x); //下推标记
updata(x*2, k, l, r);
updata(x*2+1, k, l, r);
Pushup(x); //从下往上更新信息
}
完整代码:
#include<bits/stdc++.h>
using namespace std;
const int SIZE=1e5;
struct Tree {
int l,r;
int sum;
int add;
} t[SIZE*4]; //struct数组存储线段树
int n,a[SIZE];
void Pushup(int x){
t[x].sum = t[x*2].sum + t[x*2+1].sum;
}
void Pushdown(int x){
t[x*2].add += t[x].add;
t[x*2+1].add += t[x].add;
t[x*2].sum += t[x].add*(t[x*2].r - t[x*2].l + 1);
t[x*2+1].sum += t[x].add*(t[x*2+1].r - t[x*2+1].l + 1);
t[x].add=0;
}
void build(int x, int l, int r) {
t[x].l = l, t[x].r = r; //节点x代表区间[l,r]
if (l==r) { t[x].sum = a[l]; return; } //叶节点
int mid = (l + r) / 2; //折半
build(x*2, l, mid); //左子节点[l,mid],编号 x*2
build(x*2+1, mid+1, r); //右子节点[mid+1,r],编号 x*2+1
Pushup(x); //更新函数,从下往上传递信息
}
void updata(int x, int k, int l, int r){
if(l>t[x].r||r<t[x].l) return; //无交集
if(l<=t[x].l&&r>=t[x].r){ //完全包含
t[x].add += k;
t[x].sum += (t[x].r - t[x].l + 1) * k;
return;
}
Pushdown(x); //下推标记
updata(x*2, k, l, r);
updata(x*2+1, k, l, r);
Pushup(x); //从下往上更新信息
}
int query(int x,int l,int r){
int res=0;
if(l>t[x].r||r<t[x].l) return 0; //无交集
if(l<=t[x].l&&r>=t[x].r) return t[x].sum; //完全包含
Pushdown(x); //下推标记
res= query(x<<1,l,r)+query(x<<1|1,l,r); //累计答案
Pushup(x); //从下往上更新信息
return res; //回溯
}
作为一个灵活的数据结构,线段树支持的操作还远不止于此,还可以用来维护一些别的东西,比如:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?