
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
一.进程上下文和中断上下文
进程上下文指的是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈上的内容,当内核需要切换到另一个进程时,它 需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
中断上下文是硬件通过触发信号,向CPU发送中断信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核, 内核通过这些参数进行中断处理。中断处理的过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。因为中断处理借用的是当前被中断进程的内核栈来执行。
二.fork系统调用的上下文切换
fork函数内部执行的是do_fork系统调用,下面的是do_fork的代码
1 long _do_fork(struct kernel_clone_args *args) 2 { 3 u64 clone_flags = args->flags; 4 struct completion vfork; 5 struct pid *pid; 6 struct task_struct *p; 7 int trace = 0; 8 long nr; 9 10 /* 11 * Determine whether and which event to report to ptracer. When 12 * called from kernel_thread or CLONE_UNTRACED is explicitly 13 * requested, no event is reported; otherwise, report if the event 14 * for the type of forking is enabled. 15 */ 16 if (!(clone_flags & CLONE_UNTRACED)) { 17 if (clone_flags & CLONE_VFORK) 18 trace = PTRACE_EVENT_VFORK; 19 else if (args->exit_signal != SIGCHLD) 20 trace = PTRACE_EVENT_CLONE; 21 else 22 trace = PTRACE_EVENT_FORK; 23 24 if (likely(!ptrace_event_enabled(current, trace))) 25 trace = 0; 26 } 27 28 p = copy_process(NULL, trace, NUMA_NO_NODE, args); 29 add_latent_entropy(); 30 31 if (IS_ERR(p)) 32 return PTR_ERR(p); 33 34 /* 35 * Do this prior waking up the new thread - the thread pointer 36 * might get invalid after that point, if the thread exits quickly. 37 */ 38 trace_sched_process_fork(current, p); 39 40 pid = get_task_pid(p, PIDTYPE_PID); 41 nr = pid_vnr(pid); 42 43 if (clone_flags & CLONE_PARENT_SETTID) 44 put_user(nr, args->parent_tid); 45 46 if (clone_flags & CLONE_VFORK) { 47 p->vfork_done = &vfork; 48 init_completion(&vfork); 49 get_task_struct(p); 50 } 51 52 wake_up_new_task(p); 53 54 /* forking complete and child started to run, tell ptracer */ 55 if (unlikely(trace)) 56 ptrace_event_pid(trace, pid); 57 58 if (clone_flags & CLONE_VFORK) { 59 if (!wait_for_vfork_done(p, &vfork)) 60 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); 61 } 62 63 put_pid(pid); 64 return nr; 65 }
28行 copy_process函数会copy父进程的一些资源
关键代码
p = dup_task_struct(current, node); retval = sched_fork(clone_flags, p); if (retval) goto bad_fork_cleanup_audit; retval = copy_semundo(clone_flags, p); if (retval) goto bad_fork_cleanup_security; retval = copy_files(clone_flags, p); if (retval) goto bad_fork_cleanup_semundo; retval = copy_fs(clone_flags, p); if (retval) goto bad_fork_cleanup_files; retval = copy_sighand(clone_flags, p); if (retval) goto bad_fork_cleanup_fs; retval = copy_signal(clone_flags, p); if (retval) goto bad_fork_cleanup_sighand; retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; retval = copy_namespaces(clone_flags, p); if (retval) goto bad_fork_cleanup_mm; retval = copy_io(clone_flags, p); if (retval) goto bad_fork_cleanup_namespaces; retval = copy_thread_tls(clone_flags, args->stack, args->stack_size, p, args->tls); if (pid != &init_struct_pid) { pid = alloc_pid(p->nsproxy->pid_ns_for_children); if (IS_ERR(pid)) { retval = PTR_ERR(pid); goto bad_fork_cleanup_thread; } }
- 执行dup_task_struct(),拷贝当前进程task_struct
- 检查进程数是否超过系统所允许的上限(默认32678)
- 执行sched_fork(),设置调度器相关信息,设置task进程状态为TASK_RUNNING,并分配CPU资源
- 执行copy_xxx(),拷贝进程的files, fs, mm, io, sighand, signal等信息
-
- copy_semundo: 当设置CLONE_SYSVSEM,则父子进程间共享SEM_UNDO状态
- copy_files: 当设置CLONE_FILES,则只增加文件引用计数,不创建新的files_struct
- copy_fs: 当设置CLONE_FS,且没有执行exec, 则设置用户数加1
- copy_sighand: 当设置CLONE_SIGHAND, 则增加sighand->count计数
- copy_signal: 拷贝进程信号
- copy_mm:当设置CLONE_VM,则增加mm_users计数
- copy_namespaces:一般情况,不需要创建新用户空间
- copy_io: 当设置CLONE_IO,则父子进程间共享io context,增加nr_tasks计数
- copy_thread_tls:设置子进程的寄存器等信息,从父进程拷贝thread_struct的sp0,sp,io_bitmap_ptr等成员变量值
-
- 执行copy_thread_tls(), 拷贝子进程的内核栈信息
- 执行alloc_pid(),为新进程分配新pid
三.execve系统调用
在execve中会执行do_execve
int do_execve(struct filename *filename, const char __user *const __user *__argv, const char __user *const __user *__envp) { struct user_arg_ptr argv = { .ptr.native = __argv }; struct user_arg_ptr envp = { .ptr.native = __envp }; return do_execveat_common(AT_FDCWD, filename, argv, envp, 0); }
接着调用 do_execveat_common
static int do_execveat_common(int fd, struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp, int flags) { return __do_execve_file(fd, filename, argv, envp, flags, NULL); }
会直接返回 __do_execve_file函数
static int __do_execve_file(int fd, struct filename *filename, struct user_arg_ptr argv, struct user_arg_ptr envp, int flags, struct file *file) { char *pathbuf = NULL; struct linux_binprm *bprm; struct files_struct *displaced; int retval; if (IS_ERR(filename)) return PTR_ERR(filename); /* * We move the actual failure in case of RLIMIT_NPROC excess from * set*uid() to execve() because too many poorly written programs * don't check setuid() return code. Here we additionally recheck * whether NPROC limit is still exceeded. */ if ((current->flags & PF_NPROC_EXCEEDED) && atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) { retval = -EAGAIN; goto out_ret; } /* We're below the limit (still or again), so we don't want to make * further execve() calls fail. */ current->flags &= ~PF_NPROC_EXCEEDED; retval = unshare_files(&displaced); if (retval) goto out_ret; retval = -ENOMEM; bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); if (!bprm) goto out_files; retval = prepare_bprm_creds(bprm); if (retval) goto out_free; check_unsafe_exec(bprm); current->in_execve = 1; if (!file) file = do_open_execat(fd, filename, flags); retval = PTR_ERR(file); if (IS_ERR(file)) goto out_unmark; sched_exec(); bprm->file = file; if (!filename) { bprm->filename = "none"; } else if (fd == AT_FDCWD || filename->name[0] == '/') { bprm->filename = filename->name; } else { if (filename->name[0] == '\0') pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd); else pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s", fd, filename->name); if (!pathbuf) { retval = -ENOMEM; goto out_unmark; } /* * Record that a name derived from an O_CLOEXEC fd will be * inaccessible after exec. Relies on having exclusive access to * current->files (due to unshare_files above). */ if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt))) bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE; bprm->filename = pathbuf; } bprm->interp = bprm->filename; retval = bprm_mm_init(bprm); if (retval) goto out_unmark; retval = prepare_arg_pages(bprm, argv, envp); if (retval < 0) goto out; retval = prepare_binprm(bprm); if (retval < 0) goto out; retval = copy_strings_kernel(1, &bprm->filename, bprm); if (retval < 0) goto out; bprm->exec = bprm->p; retval = copy_strings(bprm->envc, envp, bprm); if (retval < 0) goto out; retval = copy_strings(bprm->argc, argv, bprm); if (retval < 0) goto out; would_dump(bprm, bprm->file); retval = exec_binprm(bprm); if (retval < 0) goto out; /* execve succeeded */ current->fs->in_exec = 0; current->in_execve = 0; rseq_execve(current); acct_update_integrals(current); task_numa_free(current, false); free_bprm(bprm); kfree(pathbuf); if (filename) putname(filename); if (displaced) put_files_struct(displaced); return retval; out: if (bprm->mm) { acct_arg_size(bprm, 0); mmput(bprm->mm); } out_unmark: current->fs->in_exec = 0; current->in_execve = 0; out_free: free_bprm(bprm); kfree(pathbuf); out_files: if (displaced) reset_files_struct(displaced); out_ret: if (filename) putname(filename); return retval; }
在该函数中
1. 分配struct linux_binprm实例,并赋值给bprm。
2. 打开filename指向的程序,并赋值给file变量。
3. 将file变量赋值给bprm->file。
4. 将filename->name赋值给bprm->filename。
5. 调用bprm_mm_init方法,初始化进程内存的相关信息,并分配一个page作为进程的初始堆栈。
6. 调用prepare_binprm方法,从bprm->file中读取256字节到bprm->buf中。
7. 将程序的文件路径拷贝到堆栈中。
8. 将环境变量拷贝到堆栈中。
9. 将程序参数拷贝到堆栈中。
10. 调用exec_binprm方法继续执行该程序。
bprm_mm_init函数
static int __bprm_mm_init(struct linux_binprm *bprm) { int err; struct vm_area_struct *vma = NULL; struct mm_struct *mm = bprm->mm; bprm->vma = vma = vm_area_alloc(mm); if (!vma) return -ENOMEM; vma_set_anonymous(vma); if (down_write_killable(&mm->mmap_sem)) { err = -EINTR; goto err_free; } /* * Place the stack at the largest stack address the architecture * supports. Later, we'll move this to an appropriate place. We don't * use STACK_TOP because that can depend on attributes which aren't * configured yet. */ BUILD_BUG_ON(VM_STACK_FLAGS & VM_STACK_INCOMPLETE_SETUP); vma->vm_end = STACK_TOP_MAX; vma->vm_start = vma->vm_end - PAGE_SIZE; vma->vm_flags = VM_SOFTDIRTY | VM_STACK_FLAGS | VM_STACK_INCOMPLETE_SETUP; vma->vm_page_prot = vm_get_page_prot(vma->vm_flags); err = insert_vm_struct(mm, vma); if (err) goto err; mm->stack_vm = mm->total_vm = 1; arch_bprm_mm_init(mm, vma); up_write(&mm->mmap_sem); bprm->p = vma->vm_end - sizeof(void *); return 0; err: up_write(&mm->mmap_sem); err_free: bprm->vma = NULL; vm_area_free(vma); return err; }
在函数内部会分配类型为struct mm_struct的实例,该实例用来存放有关进程内存的相关信息。接着调用__bprm_mm_init
关键代码
bprm->vma = vma = vm_area_alloc(mm);
vma->vm_end = STACK_TOP_MAX;
vma->vm_start = vma->vm_end - PAGE_SIZE;
err = insert_vm_struct(mm, vma);
在函数里设置里堆栈的起始位置,已经最大的堆栈大小
执行后回到__do_execve_file,接着调用exec_binprm
exec_binprm内部又调用search_binary_handler
ret = search_binary_handler(bprm);
list_for_each_entry(fmt, &formats, lh) { if (!try_module_get(fmt->module)) continue; read_unlock(&binfmt_lock); bprm->recursion_depth++; retval = fmt->load_binary(bprm); bprm->recursion_depth--; read_lock(&binfmt_lock); put_binfmt(fmt); if (retval < 0 && !bprm->mm) { /* we got to flush_old_exec() and failed after it */ read_unlock(&binfmt_lock); force_sigsegv(SIGSEGV); return retval; } if (retval != -ENOEXEC || !bprm->file) { read_unlock(&binfmt_lock); return retval; } }
search_binary_handler遍历所以Linux可识别的可执行文件格式,如果找到,就调用load_binary,停止循环,load_binary函数指针指向的就是一个可执行程序的处理函数,如果对应的是elf文件,则调用load_elf_binary
检查并填充目标ELF的头部
int executable_stack = EXSTACK_DEFAULT; struct { struct elfhdr elf_ex; struct elfhdr interp_elf_ex; } *loc; struct arch_elf_state arch_state = INIT_ARCH_ELF_STATE; struct pt_regs *regs; loc = kmalloc(sizeof(*loc), GFP_KERNEL); if (!loc) { retval = -ENOMEM; goto out_ret; } /* Get the exec-header */ loc->elf_ex = *((struct elfhdr *)bprm->buf);
l
elf_phdata = load_elf_phdrs(&loc->elf_ex, bprm->file); if (!elf_phdata) goto out;
oad_elf_phdrs加载目标程序的程序头表
如果是动态链接,需要寻找并处理解释器段
for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) { char *elf_interpreter; loff_t pos; if (elf_ppnt->p_type != PT_INTERP) continue; retval = kernel_read(interpreter, &loc->interp_elf_ex, sizeof(loc->interp_elf_ex), &pos); if (retval != sizeof(loc->interp_elf_ex)) { if (retval >= 0) retval = -EIO; goto out_free_dentry; } break;
接着检查读取解释器头部
寻找需要装入的段
for(i = 0, elf_ppnt = elf_phdata; i < loc->elf_ex.e_phnum; i++, elf_ppnt++) { int elf_prot, elf_flags; unsigned long k, vaddr; unsigned long total_size = 0; if (elf_ppnt->p_type != PT_LOAD) continue;
最后填入程序入口地址
if (interpreter) { unsigned long interp_map_addr = 0; elf_entry = load_elf_interp(&loc->interp_elf_ex, interpreter, &interp_map_addr, load_bias, interp_elf_phdata);
在从execve函数执行返回后,会用新程序完全替代当前进程的上下文
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); if (pid < 0) { /* error occurred */ fprintf(stderr, "Fork Failed!"); exit(-1); } else if (pid == 0) { /* child process */ execlp("/bin/ls", "ls", NULL); printf("ret_from_execlp");} else { /* parent process */ /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete!\n"); exit(0); } }
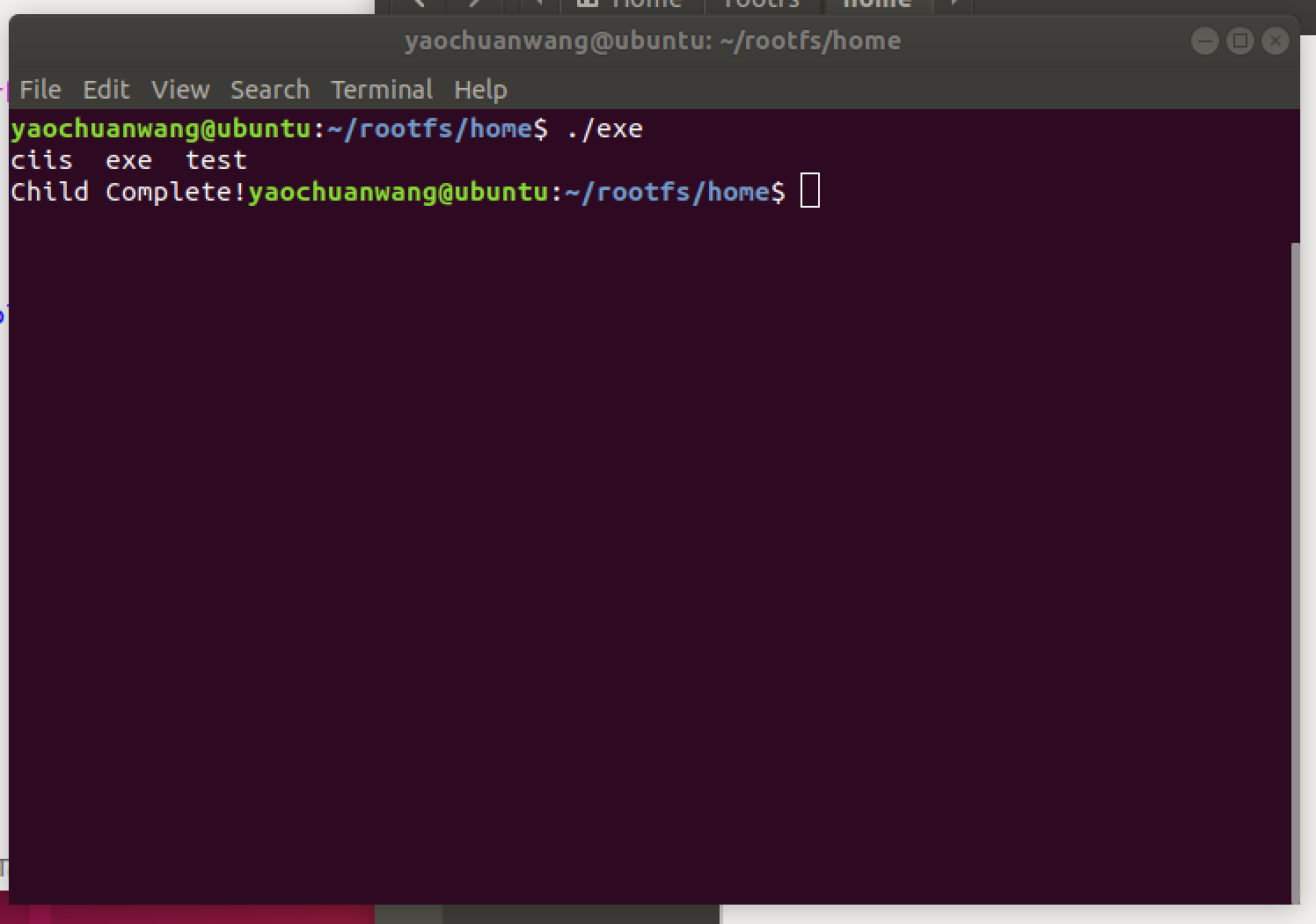
可以看到从execlp返回后,并未执行printf.
四.总结
中断上下文的一般处理过程
swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了一个快照。
-
rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调用是由系统调用入口处的汇编代码实现用户堆栈和内核堆栈的切换。
-
save cs:rip/ss:rsp/rflags:将当前CPU关键上下文压入进程X的内核堆栈,快速系统调用是由系统调用入口处的汇编代码实现的。
此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态。
进程上下文的一般处理过程
• 切换⻚全局目录(CR3)以安装一个新的地址空间,这样不同进程的虚拟地
址如0x8048400(32位x86)就会经过不同的⻚表转换为不同的物理地址。
进程切换
• 切换内核态堆栈和进程的CPU上下文,因为进程的CPU上下文提供了内核执
行新进程所需要的所有信息,包含所有CPU寄存器状态

