

【机器学习】简介
一、定义
机器学习的核心思想是创造一种算法,它能从数据中挖掘出有规律的东西,而不需要针对某个问题去写代码。你需要做的只是把数据“投喂”给这个算法,然后它会在数据上建立自己的逻辑。最基本的机器学习算法是解决分类和回归两大类问题。
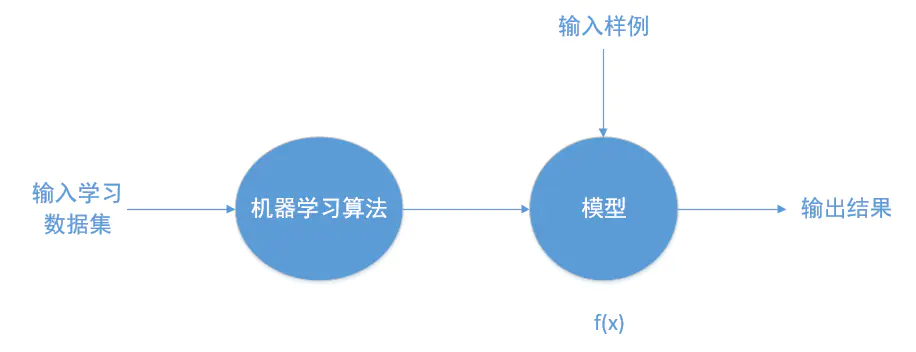
二、分类
从机器学习算法本身来看,可分为监督学习、非监督学习、半监督学习、增强学习。
监督学习:给机器的训练数据拥有标记或标签的学习方式是监督学习。监督学习主要处理分类和回归问题,本系列大部分算法都是监督学习类算法,主要的监督学习算法有下面几种。
k近邻 线性回归和多项式回归 逻辑回归 SVM支持向量机 决策树和随机森林
非监督学习:给机器的训练数据没有任何标记或标签答案。
它经常对这些数据做聚类分析型分类和异常值检测。另外非监督学习可用于对数据进行降维,降维包括特征提取和特征压缩,经典的PCA算法就是非监督学习算法用于实现特征压缩,降维把高纬特征向量变为低纬,方便计算和可视化。
半监督学习:顾名思义是监督学习和非监督学习的组合,给机器的训练数据一部分有标记或答案,另一部分没有。这种情况往往更常见,现实中各种原因都可能导致标记缺失。比如手机照片的分类,有些我们自己标记了类别,有些没有,对手机照片的分类就类似一个半监督学习。这类问题一般先使用无监督学习对数据进行处理,之后使用监督学习手段做模型的训练和预测。
增强学习:也叫强化学习,它根据周围环境的情况采取行动,根据每次行动的结果和反馈,学习和调整行动方式,它必须学习什么是最好的策略从而随着时间推移能获得最大回报。如AlphaGo内部的算法。现在无人驾驶,机器人等都是这种方式进行学习。监督学习和半监督学习依然是增强学习的基础。
机器学习的其它分类
在线(online)学习和批量(batch)学习
批量学习:这种学习方式首先要准备一定量的样本数据集资料,将数据集送给模型训练,训练之后即将模型投入生产。其优点是简单,不考虑后来喂入的数据如何优化算法,缺点是模型适应环境变化的能力弱。解决办法是定时重新批量学习,但是计算开销大。
在线学习:训练过程批量学习一样,不同的是在线学习的输入样例也参与模型训练,迭代更新模型。在线学习的优点是及时反应环境变化,但新的数据可能带来不好的变化,比如一些离群点和不正常数据点。解决办法是及时进行异常值检测。
参数学习和非参数学习
参数学习:是对模型做一些规律(函数)性假设,一旦学习到参数,就不再需要原有的数据集执行预测了,如线性回归确定线性模型参数,参数确定后,执行预测时按函数运算就行而无需数据集值的作用。
非参数学习:不对模型做过多假设,参与训练的数据集通常都要参与预测。但非参数学习并不意味没有参数,而是并不对整个问题进行某种模型定义。
三、机器学习步骤
通常学习一个好的函数,分为以下三步:
1、选择一个合适的模型,这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
2、判断一个函数的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
3、找出“最好”的函数,如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
学习得到“最好”的函数后,需要在新样本上进行测试,只有在新样本上表现很好,才算是一个“好”的函数。
四、机器学习案例
数据挖掘
- 血糖值预测:根据性别、年龄、血液各种参数(血小板、白蛋白等等)预测血糖值
- 有无糖料病预测:根据性别、年龄、血液各种参数预测有无糖尿病
计算机视觉
- 图像分类
- 根据输入的手写数字图片,预测数字。或者我们数据库中有很多种动物,训练一种模型,能根据不同动物的图片预测其所属种类。
- 一个应用场景是手写支票的文字识别。
原始图像 --> 机器学习模型 --> 类别

- 目标检测
- 目标检测比图像分类更进一步,模型的输入是一副图像,输出是物体(Object)在图中的区域和类型。
- 比较典型的应用场景是无人驾驶领域。
原始图像 --> 机器学习模型 --> 标签(包括区域信息和类别)

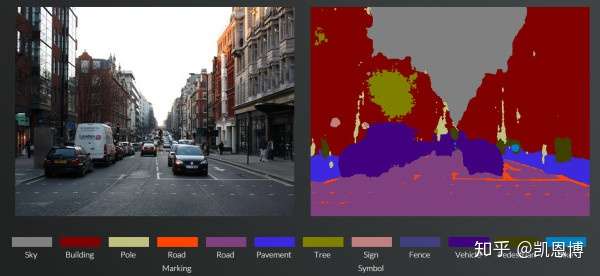
- 语义分割
- 可以理解为是一个分类问题,从检测到的目标图像中,分割出和检测物体相关的像素点信息。
原始图像 --> 机器学习模型 --> 标签(包括区域信息、类别和物体包括的像素信息)

- 场景理解
- 将图片中不同区域的图像分解为不同的区域和场景。
- 典型的案例还是无人驾驶,根据识别的场景,从而规划可行的路线。
自然语言处理
- 文本分类
- 输入新闻稿件,得到新闻所属的类别。
- 典型的案例是Google或百度的新闻自动聚合。
- 机器翻译
- 从一种语言文字翻译为另外一种语言文字。例如常用的Google翻译。
- 生成文章摘要
- 输入文章,生成文字摘要(abstract)
- 情感分析 (sentiment analysis)
- 包括情感分类(sentiment classification)、观点抽取(opinion extraction)、观点问答和观点摘要等。
- 应用案例:通过对微博文字的情感分析,获取客户对企业品牌的评价、分析营销活动的影响、民意调查等
- 问答系统
- 问答系统能够准确地理解以自然语言形式描述的用户提问,并通过检索异构语料库或问答知识库返回简洁、精确的匹配答案。当然除了NLP的技术外还涉及知识图谱等相关技术。
- 例如Apple Siri也是先将文字转换为文本,然后输入到问答系统。
- 人机系统
- 类似问答系统,不同的是人机系统不以获取答案为目的,甚至可以闲聊。例如微软小冰。
- 图像描述(image captioning)
- 输入图像,输出图像对应的文字描述。需要计算机视觉里的场景理解作为前提。
语音识别
- 输入是语音数据,输出文本数据
- 比较常见应用的是语音输入法,现在几乎所有的手机都有类似功能。
机器决策
- 自动驾驶(Autopilot):有一种端到端学习(End-to-End Learning)的技术。输入为图像和雷达数据,输出为车辆控制信号。
- 游戏AI:比如AlphaStar可以根据游戏屏幕数据操作键盘和鼠标,控制游戏里的角色。最新的消息是AlphaStar已经可以打败星际争霸2顶级职业玩家。
- 机器人:循环输入摄像头数据,输出机械臂等控制信号,以协助机械臂执行相应操作。可以应用在比如家用服务机器人、救援机器人、工业机器人手臂等。
上述几类问题大多需要深度学习+强化学习来解决。
参考:https://www.jianshu.com/p/b9583c7cb6c3
https://blog.csdn.net/hohaizx/article/details/80584307


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)