


sqlserver xml 操作:1、使用for xml
sqlserver xml 操作:1、使用for xml
说实话,老顾觉得其实看看这两个文章基本就能满足学习的需要了,毕竟里面也有不少示例了,不过有qq群的同学想问些基本概念、语法、用法、数据库里面的应用等等,那老顾就来水几篇文章好了
[ FOR { BROWSE | <XML> } ]
<XML> ::=
XML
{
{ RAW [ ('ElementName') ] | AUTO }
[
<CommonDirectives>
[ , { XMLDATA | XMLSCHEMA [ ('TargetNameSpaceURI') ]} ]
[ , ELEMENTS [ XSINIL | ABSENT ]
]
| EXPLICIT
[
<CommonDirectives>
[ , XMLDATA ]
]
| PATH [ ('ElementName') ]
[
<CommonDirectives>
[ , ELEMENTS [ XSINIL | ABSENT ] ]
]
}
<CommonDirectives> ::=
[ , BINARY BASE64 ]
[ , TYPE ]
[ , ROOT [ ('RootName') ] ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
for xml 就是基本的sql查询语句后追加的一个输出方式的限定
这里以master…spt_values表的数据作为依据来进行展示
先来个正常的select
select * from master..spt_values
------------------------------------------
name number type low high status
----------------------------------- ----------- ---- ----------- ----------- -----------
rpc 1 A NULL NULL 0
pub 2 A NULL NULL 0
sub 4 A NULL NULL 0
dist 8 A NULL NULL 0
dpub 16 A NULL NULL 0
rpc out 64 A NULL NULL 0
data access 128 A NULL NULL 0
......
backup device 16 V NULL NULL 0
serial writes 32 V NULL NULL 0
read only 4096 V 0 1 0
deferred 8192 V 0 1 0
(2552 行受影响)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
然后来个追加了for xml的语句,因为有四种模式,各自来一遍
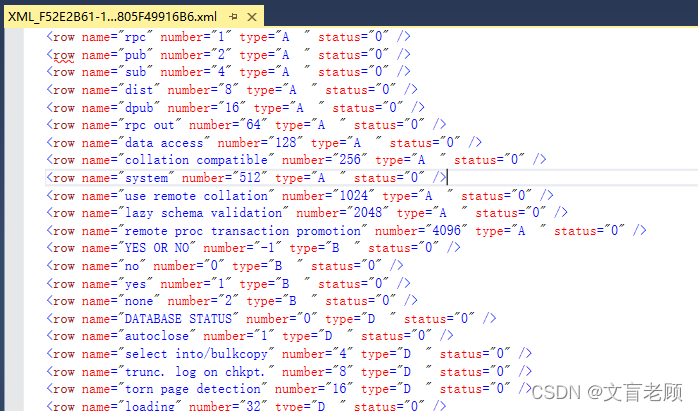
select * from master..spt_values for xml raw- 1
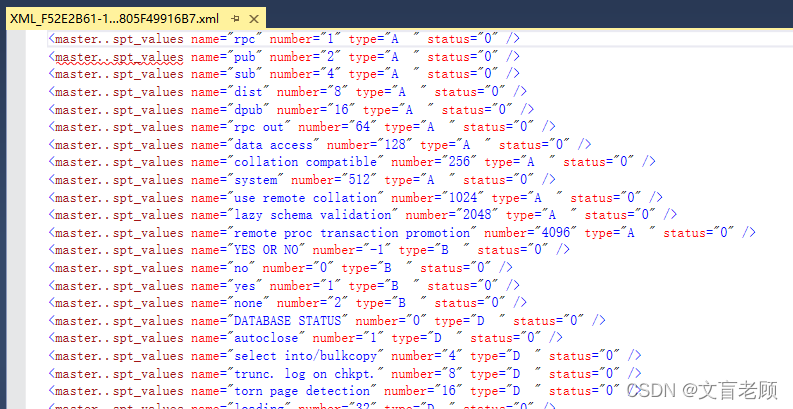
select * from master..spt_values for xml auto- 1
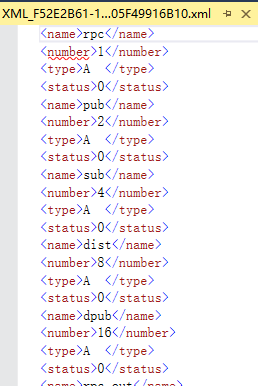
-- path不指定节点名
select * from master..spt_values for xml path('')- 1
- 2
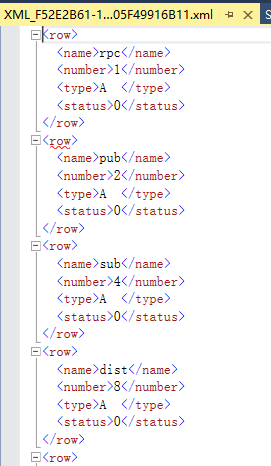
-- path 指定节点名
select * from master..spt_values for xml path('row')- 1
- 2
关于explicit模式,是更灵活的模式,不过相对来说也复杂很多,并且有格式要求,参考https://docs.microsoft.com/zh-cn/sql/relational-databases/xml/use-explicit-mode-with-for-xml?view=sql-server-ver15
个人感觉虽然这个模式下,灵活性确实高出不少,但相对来说,指令也复杂不少,通常情况下,生成多层xml的话,老顾是不会这么写的,有兴趣的同学可以参考https://blog.csdn.net/Beirut/article/details/8163236
大概意思呢,就是自行定义好层深,然后通过嵌套方式来得到一个序列化的xml结果,例如
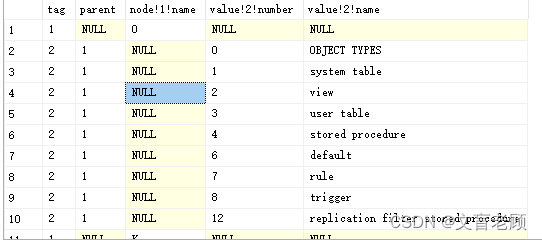
select b.*
from (
select 1 tag,null parent,type [node!1!name],null [value!2!number] ,null [value!2!name]
from (
select distinct type
from master..spt_values
) a
) a
cross apply (
select a.*
union all
select 2,1,null,number,name
from master..spt_values
where type=a.[node!1!name]
) b- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
select b.*
from (
select 1 tag,null parent,type [node!1!name],null [value!2!number] ,null [value!2!name]
from (
select distinct type
from master..spt_values
) a
) a
cross apply (
select a.*
union all
select 2,1,null,number,name
from master..spt_values
where type=a.[node!1!name]
) b
for xml explicit,root('spt_values')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
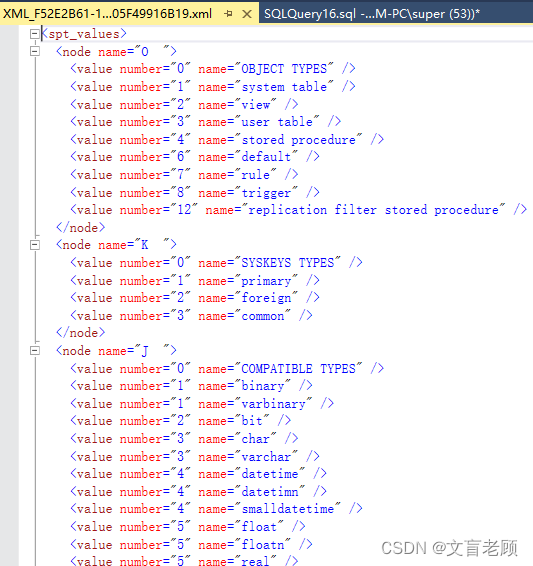
也就是说,这个东西对不确定的东西支持不太好,比如无限级分类,我可能有三级,也可以能有6级,但是实现起来就完全不同,需要通过对应数量的cross来实现确定级数的xml,这里用老顾的无限级分类来做个示范
select lv6.*
from (
-- 定义顶级分类,tag固定为1,父类固定为null
select 1 tag,null parent,cate_id [lv1!1!id],cate_name [lv1!1!name]
-- 预留出2级之后的字段
,null [lv2!2!id],null [lv2!2!name]
,null [lv3!3!id],null [lv3!3!name]
,null [lv4!4!id],null [lv4!4!name]
,null [lv5!5!id],null [lv5!5!name]
,null [lv6!6!id],null [lv6!6!name]
from v_categories with (nolock)
where cate_parent=0
) lv1
cross apply (
select lv1.*
union all
select 2,1,null,null,cate_id,cate_name,null,null,null,null,null,null,null,null
from v_categories with (nolock)
where cate_parent=lv1.[lv1!1!id]
) lv2
cross apply (
select lv2.*
union all
select 3,2,null,null,null,null,cate_id,cate_name,null,null,null,null,null,null
from v_categories with (nolock)
where cate_parent=lv2.[lv2!2!id]
) lv3
cross apply (
select lv3.*
union all
select 4,3,null,null,null,null,null,null,cate_id,cate_name,null,null,null,null
from v_categories with (nolock)
where cate_parent=lv3.[lv3!3!id]
) lv4
cross apply (
select lv4.*
union all
select 5,4,null,null,null,null,null,null,null,null,cate_id,cate_name,null,null
from v_categories with (nolock)
where cate_parent=lv4.[lv4!4!id]
) lv5
cross apply (
select lv5.*
union all
select 6,5,null,null,null,null,null,null,null,null,null,null,cate_id,cate_name
from v_categories with (nolock)
where cate_parent=lv5.[lv5!5!id]
) lv6
for xml explicit,root('产品分类')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50

这语句写下来就突出一个离谱。。。。总之呢,就是层级要预先定义,所有用到的字段需要提前按照[节点名!层级!属性名]方式预先定义,然后各种子查询
好了,四种查询模式我们已经都看过效果了,然后是各个参数的使用,我们在之后的使用中再一一介绍

