

python识别图片中的文本保存到word中
python可以使用第三方库pytesseract实现图像的文本识别,并将识别的结果保存到word中,代码本生不复杂pytesseract环境有点麻烦这里整理总结一下
一、简介
Tesseract是一个 由HP实验室开发 由Google维护的开源的光学字符识别(OCR)引擎,可以在 Apache 2.0 许可下获得。它可以直接使用,或者(对于程序员)使用 API 从图像中提取输入,包括手写的或打印的文本。
二、包安装
1 | pip install pytesseract |
三、代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import pytesseractfrom PIL import Imagefrom docx import Documentdef convert_image_to_editable_docx(image_file, docx_file): # 读取图片并进行OCR识别 image = Image.open(image_file) # 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别, text = pytesseract.image_to_string(image, lang='chi_sim') # 创建Word文档并插入文本 doc = Document() doc.add_paragraph(text) doc.save(docx_file)# 示例用法input_image = "1.png" # 输入图片文件路径output_docx = "output.docx" # 输出Word文档路径convert_image_to_editable_docx(input_image, output_docx) |
不安装环境运行代码会报错:pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
四、Tesseract的常用网址
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
官方网站:https://github.com/tesseract-ocr/tesseract
官方文档:https://github.com/tesseract-ocr/tessdoc
语言包地址:https://github.com/tesseract-ocr/tessdata
语言包国内地址:https://gitcode.com/mirrors/tesseract-ocr/tessdata/tree/main?utm_source=csdn_github_accelerator&isLogin=1
五、安装
我下载的是:tesseract-ocr-w64-setup-v5.1.0.20220510.exe
我的安装地址是:D:\Program Files\Tesseract-OCR
六、设置环境变量
path中添加
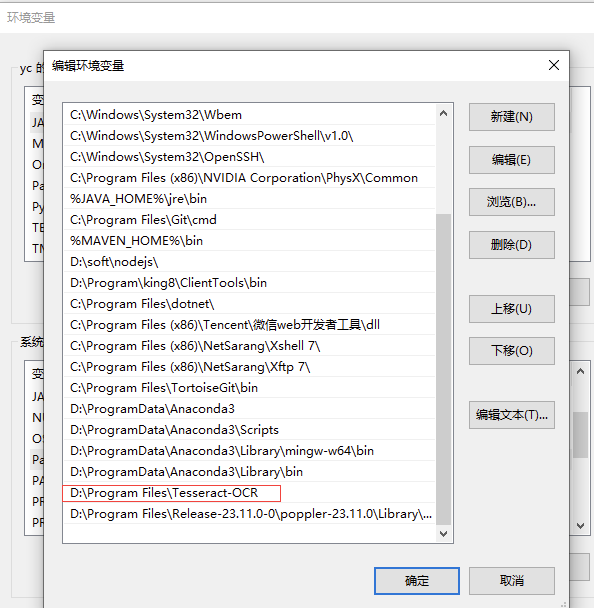
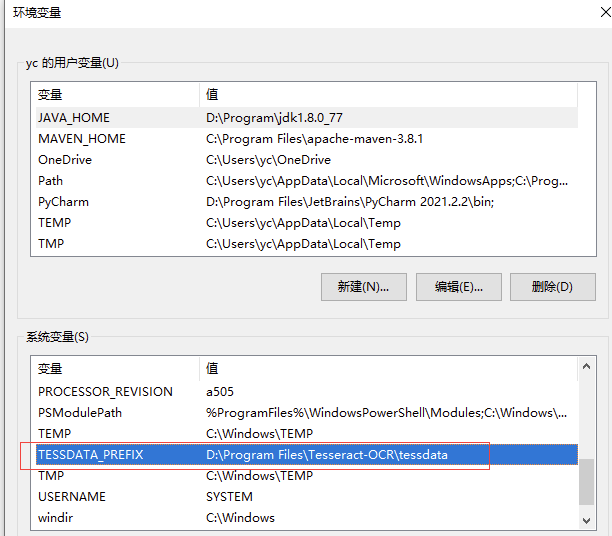
新增:TESSDATA_PREFIX
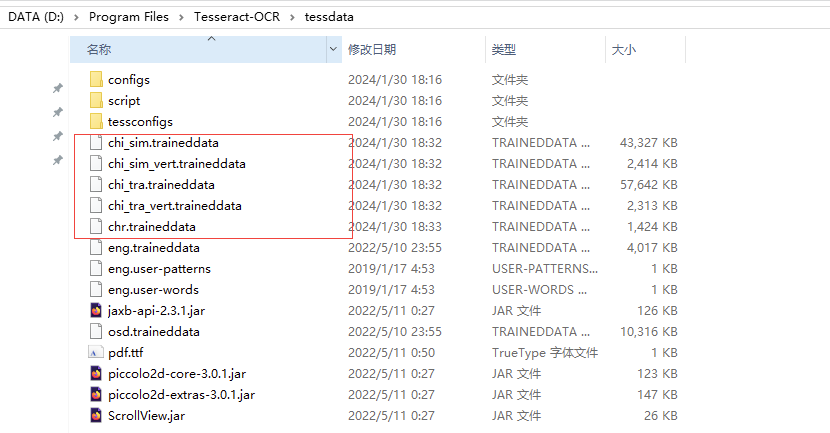
下载语言包:语言包国内地址:https://gitcode.com/mirrors/tesseract-ocr/tessdata/tree/main?utm_source=csdn_github_accelerator&isLogin=1
下载如下这几个包,放到D:\Program Files\Tesseract-OCR\tessdata

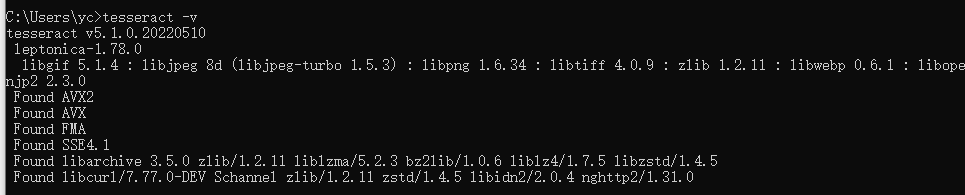
七、验证环境变量
1.查看是否安装成功
打开cmd,输入tesseract -v回车,若显示版本号即为安装成功。
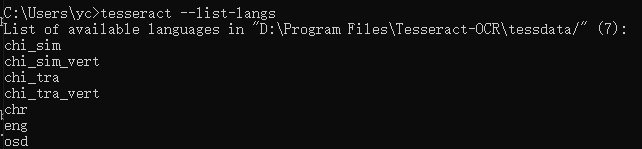
2.查看已经安装的语言
在cmd中输入tesseract --list-langs回车,若显示版本号即为安装成功。
八、效果
1.png图片

识别后的效果



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2023-01-31 H2嵌入式数据库集成springboot