curl-awk-grep
() ⼦shell中运⾏
[root@VM_0_14_centos ~]# a=zs [root@VM_0_14_centos ~]# (a=1;echo $a;);echo $a; 1 zs
{} 当前shell中执⾏
[root@VM_0_14_centos ~]# a=zs [root@VM_0_14_centos ~]# { a=1;echo $a;};echo $a; 1 1
shell 输入输出
❖ > file 将输出重定向到另⼀个⽂件
[root@VM_0_14_centos test]# echo 'abcdef123456' > t02.txt [root@VM_0_14_centos test]# ls t01 t02.txt [root@VM_0_14_centos test]# cat t02.txt abcdef123456
❖ >> 表⽰追加 等价于tee -a
[root@VM_0_14_centos test]# echo '\nhello' >> t02.txt [root@VM_0_14_centos test]# cat t02.txt abcdef123456 \nhello [root@VM_0_14_centos test]# echo '12312312312hello' >> t02.txt [root@VM_0_14_centos test]# cat t02.txt abcdef123456 \nhello 12312312312hello
grep

❖ | 表⽰管道,也就是前⼀个命令的输出传⼊下⼀个命令 的输⼊
[root@VM_0_14_centos test]# cat t01
1aaa
2s
0000
3ddd
4fff
afff
bfffFF
cffFFF
dFFF
FFFFF
1FF2FF3FF
查询出含有fff的字符串
[root@VM_0_14_centos test]# cat t01 | grep -i 'fff' 4fff afff bfffFF cffFFF dFFF FFFFF
查询含有fff的字符串,只输出fff [root@VM_0_14_centos test]# cat t01 | grep -o 'fff' fff fff fff
查询含有fff的字符串,忽略大小写 [root@VM_0_14_centos test]# cat t01 | grep -io 'fff' fff fff fff ffF FFF FFF
匹配以c开头的一个字符
[root@VM_0_14_centos test]# echo abcdefg | grep -o "c."
cd
匹配以c开头的多个字符(.*表示一个或者多个)
[root@VM_0_14_centos test]# echo abcdefg | grep -o "c.*"
cdefg
curl
[root@VM_0_14_centos test]# curl http://www.baidu.com/s?wd=shell | grep "结果约" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0<div class="head_nums_cont_outer OP_LOG new_head_nums_cont_outer" ><div class="head_nums_cont_inner" style="top:-42px"><div class="search_tool_conter new_search_tool_conter"><span class="c-gap-left-samll search_tool_close"><i class="c-icon searchTool-up c-icon-chevron-top-gray-s"></i>收起工具</span><span class="search_tool_tf ">时间不限<i class="c-icon c-icon-triangle-down"></i></span><span class="search_tool_ft c-gap-left">所有网页和文件<i class="c-icon c-icon-triangle-down"></i></span><span class="search_tool_si c-gap-left">站点内检索<i class="c-icon c-icon-triangle-down"></i></span></div><div class="nums new_nums"><div class="search_tool" ><i class="c-icon searchTool-spanner c-icon-setting"></i>搜索工具</div><span class="nums_text">百度为您找到相关结果约79,100,000个</span></div></div></div><script type="text/javascript"> 100 361k 0 361k 0 0 1134k 0 --:--:-- --:--:-- --:--:-- 1136k
curl + grep
[root@VM_0_14_centos test]# curl http://www.baidu.com/s?wd=shell | grep -o "结果约[0-9,]*" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0结果约79,100,000 100 361k 0 361k 0 0 1260k 0 --:--:-- --:--:-- --:--:-- 1263k [root@VM_0_14_centos test]# curl http://www.baidu.com/s?wd=shell | grep -o "结果约[0-9,]*" | grep -o '[0-9,]*' % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 363k 0 363k 0 0 674k 0 --:--:-- --:--:-- --:--:-- 674k 100,000,000
curl+grep+ while读取文件,进行搜索匹配
例如:读取bd.keywod,输入curl网址,配置搜索到的数据量
[root@VM_0_14_centos test]# cat bd.keyword shell bash linux centos redhat[root@VM_0_14_centos test]# while read k;do echo $k;curl -s http://www.baidu.com/s?wd=$k;done < bd.keyword | grep -o "结果约[0-9,]*" 结果约79,100,000 结果约64,700,000 结果约100,000,000 结果约64,700,000 结果约48,700,000
awk
awk是一个强大的文本分析工具,简单来说awk就是把文件逐行读入,(空格,制表符)为默认分隔符将每行切片,切开的部分再进行各种分析处理
-F 参数指定字段分隔符
$NF 代表最后⼀个字段
BEGIN{RS="_"} 也可以表⽰分隔符
$0代表原来的⾏
$1代表第⼀个字段
$N 代表第N个字段
按照 ,分割
[root@VM_0_14_centos test]# echo "a,c,b,d,e,f" | awk -F ',' '{ print $1 $3}' ab
没写 -f 按照 空格分 [root@VM_0_14_centos test]# echo "this is a test" | awk '{ print $1 }' this
分隔符不存在时,显示全部
[root@VM_0_14_centos test]# echo "123+456-900/200%2" | awk -F '+-/%' '{ print $0 }' 123+456-900/200%2 [root@VM_0_14_centos test]# echo "123+456-900/200%2" | awk -F '+-/%' '{ print $1 }' 123+456-900/200%2 [root@VM_0_14_centos test]# echo "123+456-900/200%2" | awk -F '+-/%' '{ print $2 }'
分隔符中有 | 表示,且 | 两边都存在时,如:'+|-' 表示按照 + -进行分割,将字串分成了3份
[root@VM_0_14_centos etc]# echo "123+456-900" | awk -F '+|-' '{ print $1 }'
123
[root@VM_0_14_centos etc]# echo "123+456-900" | awk -F '+|-' '{ print $2 }'
456
[root@VM_0_14_centos etc]# echo "123+456-900" | awk -F '+|-' '{ print $3 }'
900
BEGIN{RS="_"} 也可以表⽰分隔符

数据计算
[root@VM_0_14_centos test]# echo -e "1|2|3\n4|5|6\n7|8|9" | awk -F "|" 'BEGIN{a=0}{a=a+$2}END{ print a}' 15
获取点赞量
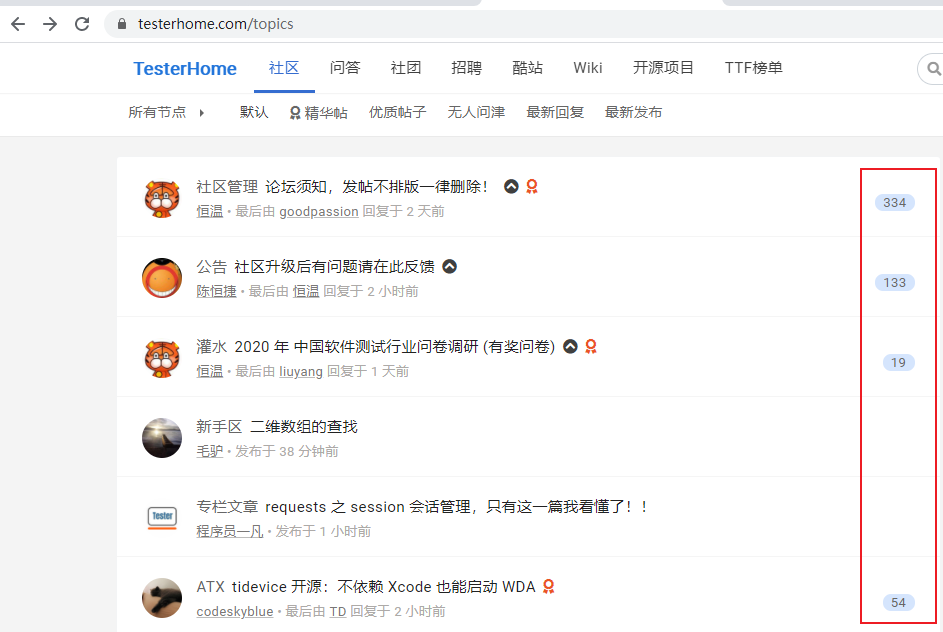

[root@VM_0_14_centos etc]# curl -s https://testerhome.com/topics | grep -o '<a class="state-false" .*</a>' | awk -F '">|</' '{ print $2 }' 334 133 1
再次整理,获取点赞量
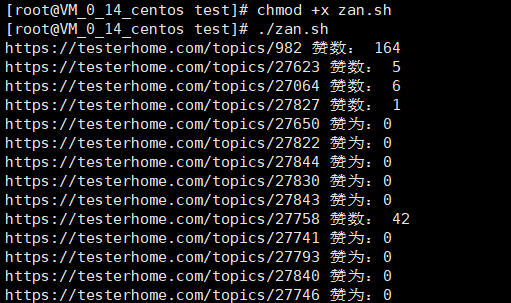
zan.sh
ids=`curl -s https://testerhome.com/topics/ | grep -o 'href="/topics/[0-9]*"' | awk -F '/|"' '{ print $4 }' ` for id in $ids do url=https://testerhome.com/topics/$id zan=`curl -s $url | grep -o -m1 '<span>.*个赞' | awk -F '>|个' '{ print $2 }' ` if [ -n "$zan" ] then echo $url "赞数:" $zan else echo $url "赞为:0" fi done
取出用户名,即单独取出root

命令
取出passwd文档中的信息

[root@VM_0_14_centos etc]# cat passwd | awk -F ':' '{ print $1 }' root
取出passwd文档中的信息

cat passwd | awk -F ':' 'BEGIN{count=0}{name[count]=$1;path[count]=$7;count++}END{for(i=0;i<NR;i++)print i,name[i],path[i] }'
curl+awk

sed
替换单个字符串
[root@VM_0_14_centos test]# echo 'hello zs ls ww' | sed 's/hello/nihao/' nihao zs ls ww
全量替换

替换文件中的字符串,不保存
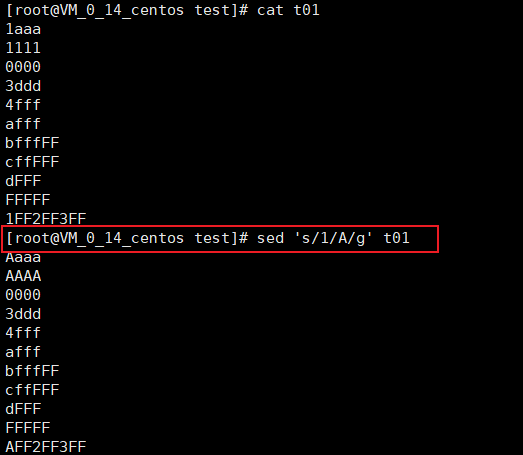
替换文件中的字符串,并保存
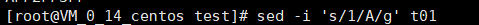
替换文件中的字符串,并保存副本

函数
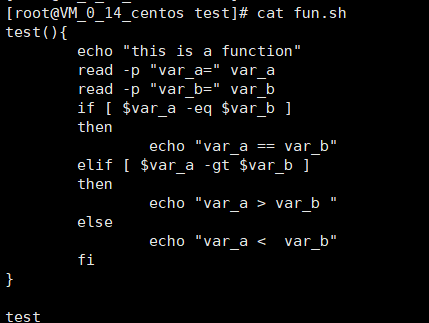
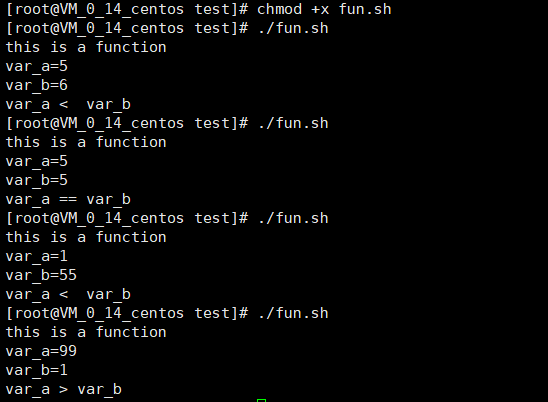
test(){ echo "this is a function" read -p "var_a=" var_a read -p "var_b=" var_b if [ $var_a -eq $var_b ] then echo "var_a == var_b" elif [ $var_a -gt $var_b ] then echo "var_a > var_b " else echo "var_a < var_b" fi } test
传参

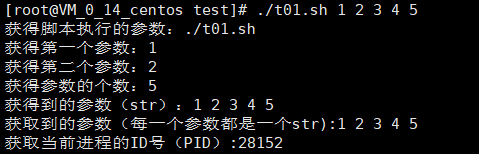
echo "获得脚本执行的参数:$0";
echo "获得第一个参数:$1";
echo "获得第二个参数:$2";
echo "获得参数的个数:$#";
echo "获得到的参数(str):$*";
echo "获取到的参数(每一个参数都是一个str):$@";
echo "获取当前进程的ID号(PID):$$";
利用Python搭建一个小网站
python -m CGIHTTPServer
默认开启8000端口
实现用户循环输入
target=1 while [ $target -eq 1 ] do read -p "输入:" num if [ ${num} != '110' ] then echo "用户输入:" ${num} else target=0 echo "输入结束" fi done echo "while循环结束" 简单写法 while true do read -p "输入:" num if [ ${num} != '110' ] then echo "用户输入:" ${num} else break fi done echo "while循环结束"
对用户输入数据的计算
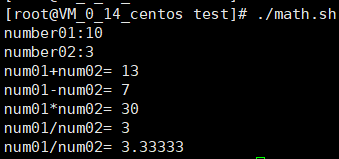
read -p "number01:" num01 read -p "number02": num02 echo "num01+num02=" $(($num01+$num02)) echo "num01-num02=" $(($num01-$num02)) echo "num01*num02=" $(($num01*$num02)) echo "num01/num02=" $(($num01/$num02)) echo "num01/num02=" `awk "BEGIN { print $num01/$num02 }"`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号