import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
data = pd.read_csv(r'D:\Anaconda\ana\envs\python32\Lib\site-packages\sklearn\datasets\data\iris.csv')
data.drop_duplicates(inplace = True)
class Perceptron:
def __init__(self,alpha,times):
self.alpha = alpha
self.times = times
def step(self,z):
return np.where(z >= 0,1,-1)
def fit(self,X,y):
X = np.asarray(X)
y = np.asarray(y)
self.w_ = np.zeros(1 + X.shape[1])
self.loss = []
for i in range(self.times):
loss = 0
for x,target in zip(X,y):
y_hat = self.step(np.dot(x,self.w_[1:]) + self.w_[0])
# 计算顺序为先返回y_hat != target的逻辑值1 / 0再加到loss上从而实现阶跃损失函数
loss += y_hat != target
self.w_[0] += self.alpha * (target - y_hat)
self.w_[1:] += self.alpha * (target - y_hat) * x
self.loss.append(loss)
def predict(self,X):
return self.step(np.dot(X,self.w_[1:]) + self.w_[0])
data1 = data[data["species"] == 1]
data0 = data[data["species"] == 0]
data0["species"] = data0["species"].map({0:-1})
data1 = data1.sample(len(data1),random_state = 0)
data0 = data0.sample(len(data0),random_state = 0)
train_X = pd.concat([data1.iloc[:40,:-1],data0.iloc[:40,:-1]],axis = 0)
train_y = pd.concat([data1.iloc[:40,-1],data0.iloc[:40,-1]],axis = 0)
test_X = pd.concat([data1.iloc[40:,:-1],data0.iloc[40:,:-1]],axis = 0)
test_y = pd.concat([data1.iloc[40:,-1],data0.iloc[40:,-1]],axis = 0)
P = Perceptron(0.1,10)
P.fit(train_X,train_y)
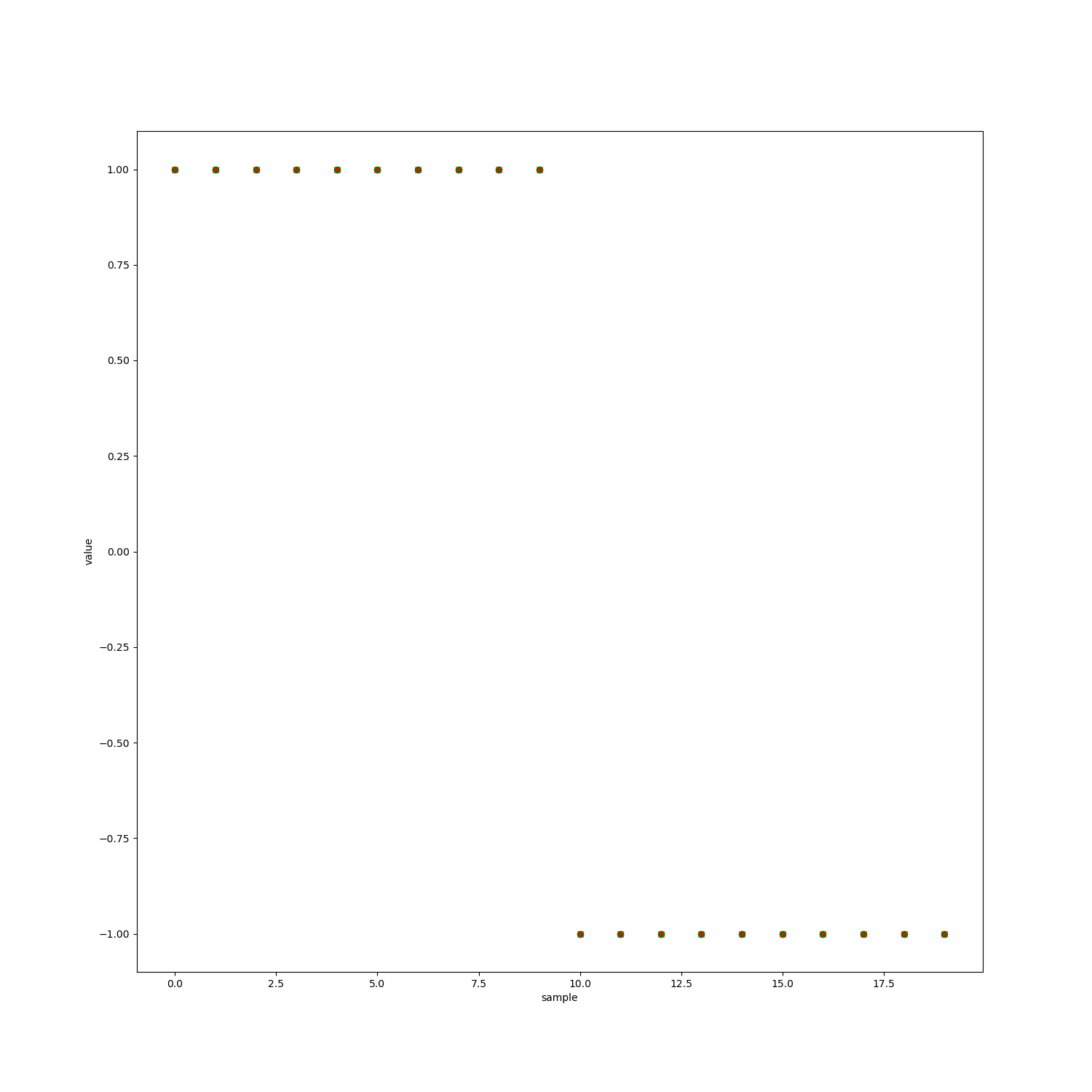
result = P.predict(test_X)
print(result)
plt.figure(figsize = (15,15))
plt.plot(result,"go",label = "predict")
plt.plot(test_y.values,"rx",label = "real")
plt.xlabel("sample")
plt.ylabel("value")
plt.savefig(r"C:\Users\Y_ch\Desktop\perceptron_iris\iris.png")
plt.figure(figsize = (15,15))
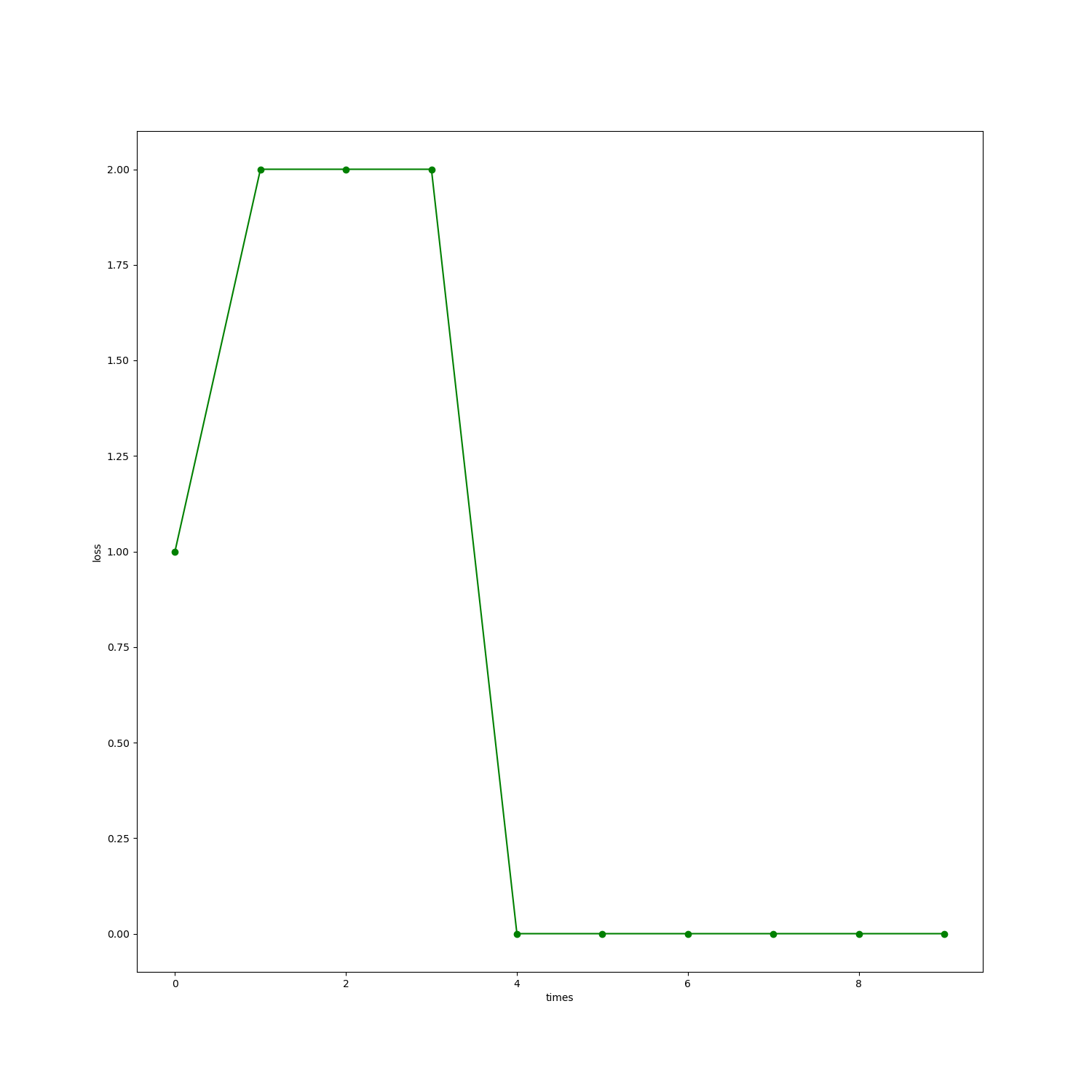
plt.plot(P.loss,"go-")
plt.xlabel("times")
plt.ylabel("loss")
plt.show()
plt.savefig(r"C:\Users\Y_ch\Desktop\perceptron_iris\loss.png")
![]()
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号