

动手学强化学习(笔记)
配套资源
全书目录
点击查看目录
强化学习基础篇
第 1 章 初探强化学习
第 2 章 多臂Tiger机(中文居然是敏感词= =)
第 3 章 马尔可夫决策过程 MDP
第 4 章 动态规划算法 DP
第 5 章 时序差分算法 (Sarsa/Q-learning)
第 6 章 Dyna-Q 算法
强化学习进阶篇
第 7 章 DQN 算法
第 8 章 DQN 改进算法(Double DQN 和 Dueling DQN)
第 9 章 策略梯度算法
第 10 章 Actor-Critic 算法
第 11 章 TRPO 算法(信任区域策略优化)
第 12 章 PPO 算法(Proximal Policy Optimization)
第 13 章 DDPG 算法(深度确定性策略梯度 deep deterministic policy gradient)
第 14 章 SAC 算法(Soft Actor-Critic)
强化学习前沿篇
第 15 章 模仿学习(imitation learning)
第 16 章 模型预测控制(MPC)
第 17 章 基于模型的策略优化(MBPO)
第 18 章 离线强化学习
第 19 章 目标导向的强化学习(GoRL/HER)
第 20 章 多智能体强化学习入门(MARL)
第 21 章 多智能体强化学习进阶(MADDPG)
第3章 马尔可夫决策过程MDP
3.3 MRP
回报
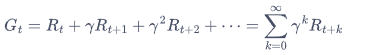
价值函数
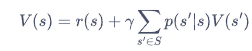
3.4 MDP
状态价值函数
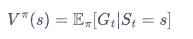
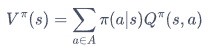
动作价值函数

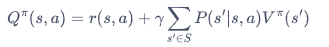
这两个价值函数是相互融合的
贝尔曼期望方程(红框?)
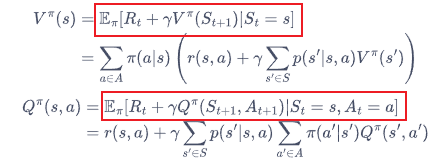
MDP退化成MRP问题:消去动作a
消去动作变量a的方法,即为对策略概率取平均
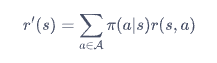

表示下一个状态,如表示下一个状态,表示下一个状态的回报。
第5章 时序差分算法
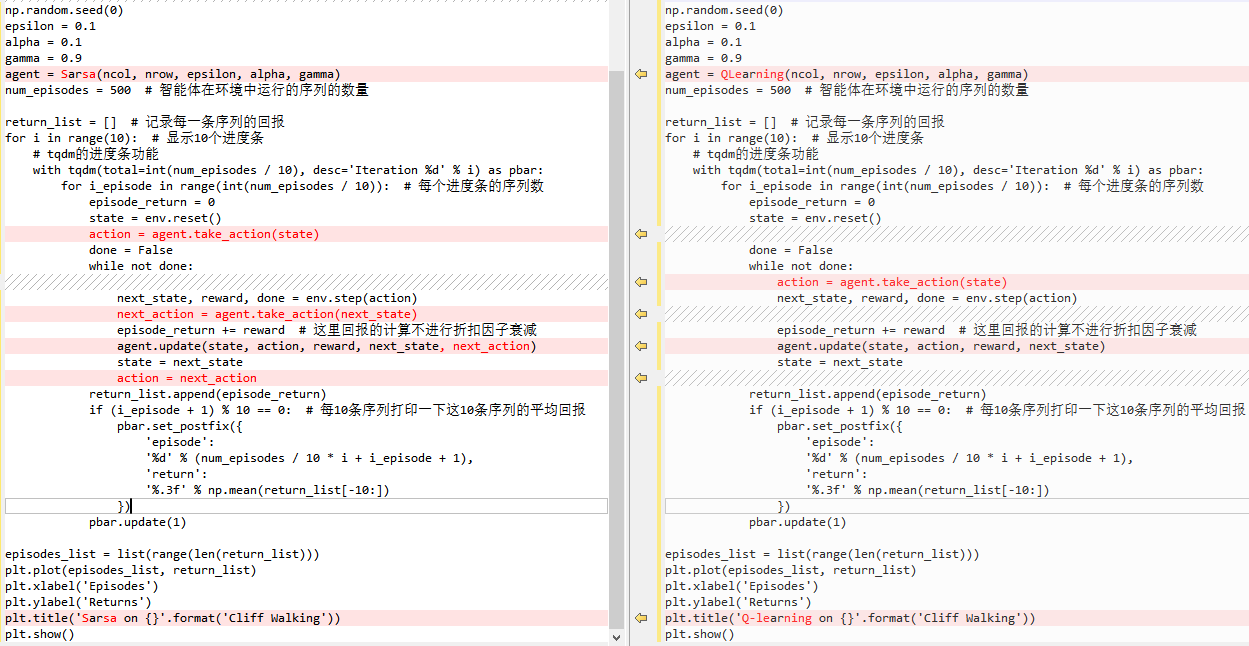
5.3 Sarsa算法
更新公式:
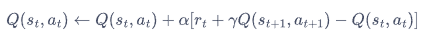
Sarsa算法:

4*12的悬崖漫步,结果如下:
点击查看迭代过程
Iteration 0: 100%|██████████| 50/50 [00:00<00:00, 1351.95it/s, episode=50, return=-119.400, ii=49, i=0]
Iteration 1: 100%|██████████| 50/50 [00:00<00:00, 1352.01it/s, episode=100, return=-63.000, ii=49, i=1]
Iteration 2: 100%|██████████| 50/50 [00:00<00:00, 2381.88it/s, episode=150, return=-51.200, ii=49, i=2]
Iteration 3: 100%|██████████| 50/50 [00:00<00:00, 3573.33it/s, episode=200, return=-48.100, ii=49, i=3]
Iteration 4: 100%|██████████| 50/50 [00:00<00:00, 3847.63it/s, episode=250, return=-35.700, ii=49, i=4]
Iteration 5: 100%|██████████| 50/50 [00:00<00:00, 5557.87it/s, episode=300, return=-29.900, ii=49, i=5]
Iteration 6: 100%|██████████| 50/50 [00:00<00:00, 5002.63it/s, episode=350, return=-28.300, ii=49, i=6]
Iteration 7: 100%|██████████| 50/50 [00:00<00:00, 5557.87it/s, episode=400, return=-27.700, ii=49, i=7]
Iteration 8: 100%|██████████| 50/50 [00:00<00:00, 6253.62it/s, episode=450, return=-28.500, ii=49, i=8]
Iteration 9: 100%|██████████| 50/50 [00:00<00:00, 7146.78it/s, episode=500, return=-18.900, ii=49, i=9]
Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ooo> ^ooo ooo> ooo> ooo> ooo> ^ooo ^ooo ooo> ooo> ovoo
^ooo xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx EEEE
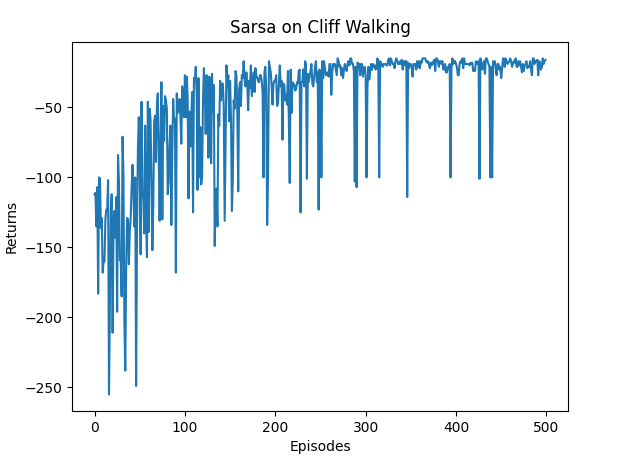
换成4*4的悬崖漫步,结果如下:
Sarsa算法最终收敛得到的策略为:
ovoo ^ooo ooo> ovoo
ooo> ooo> ooo> ovoo
^ooo ^ooo ooo> ovoo
^ooo **** **** EEEE
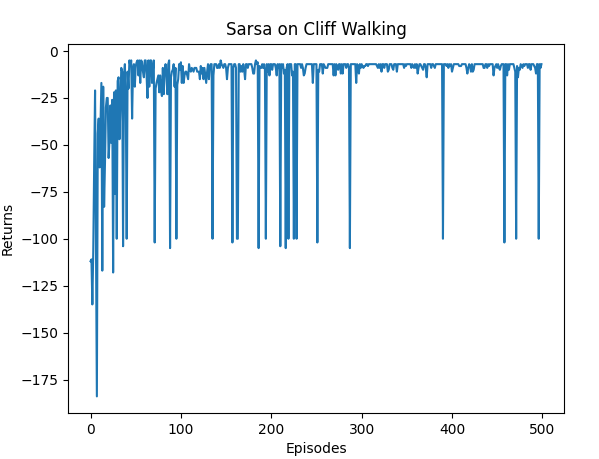
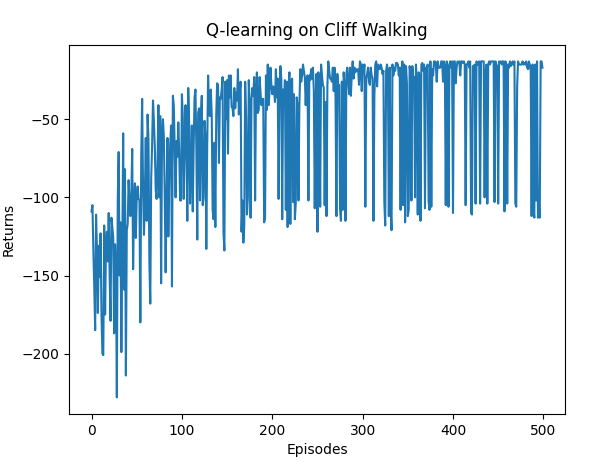
由上图可见,由于环境比较简单,收敛较快。但也可以看出,回报在后段波动较大。
5.4 多步Sarsa算法
更新公式:
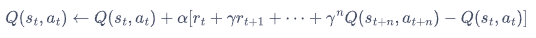
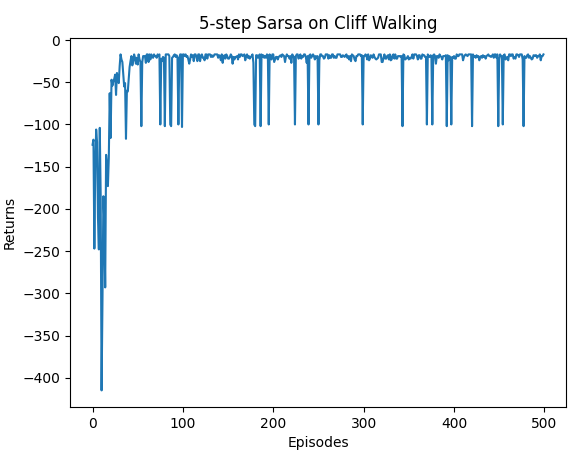
5步Sarsa算法最终收敛得到的策略为:
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ^ooo ^ooo oo<o ^ooo ^ooo ^ooo ^ooo ooo> ooo> ^ooo ovoo
ooo> ^ooo ^ooo ^ooo ^ooo ^ooo ^ooo ooo> ooo> ^ooo ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
5.5 Q-learning算法
更新公式:
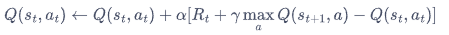
Q-learning算法:

从代码实现的差异可以看出,Q-learning不需要用到一下步的动作:

Q-learning算法最终收敛得到的策略为:
^ooo ovoo ovoo ^ooo ^ooo ovoo ooo> ^ooo ^ooo ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ^ooo ooo> ooo> ooo> ooo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
第7章 DQN算法
DQN是深度强化学习的基础,掌握了该算法才算是真正进入了深度强化学习领域。
7.3 DQN
Q-learning 的更新规则(参见 5.5 节):
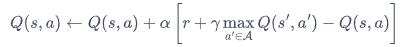
Q 网络的损失函数:
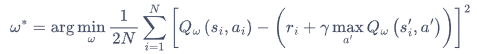
7.4 DQN代码实践
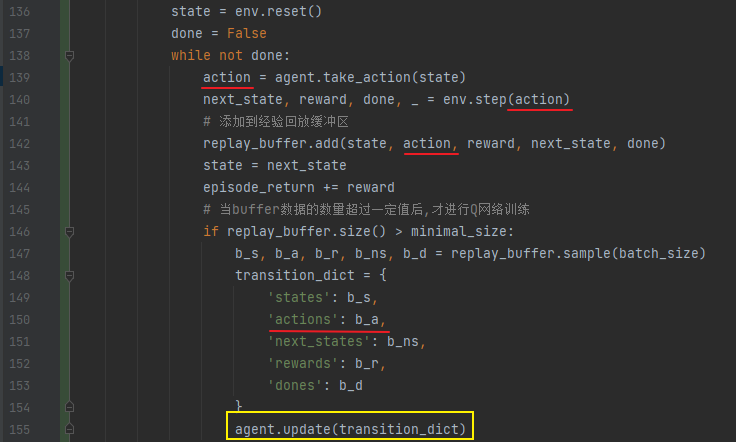
DQN算法流程:

四元组的产生、添加到缓冲区、经验回放以及更新目标网络,以action为例:agent.take_action方法产生action,然后通过replay_buffer.add添加到缓冲区,通过replay_buffer.sample抽样出经验进行回放,最后通过agent.update使用梯度下降方法进行神经网络更新。
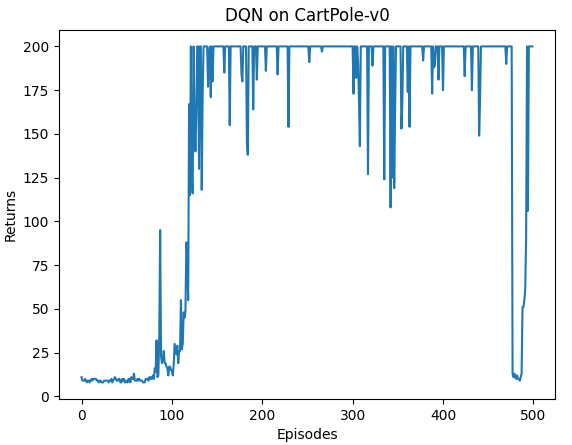
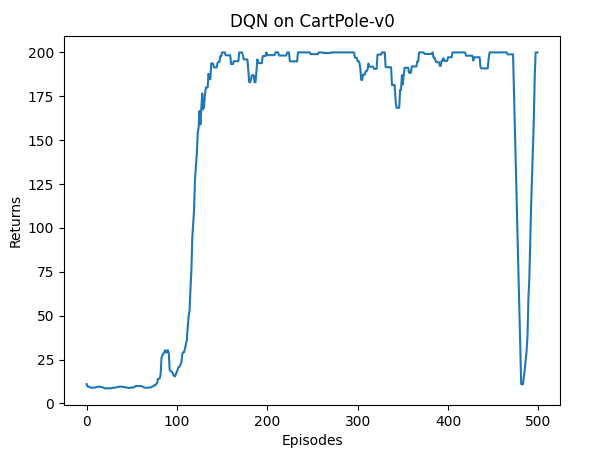
训练结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本