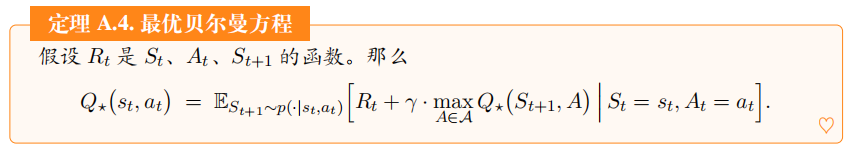深度强化学习DRL(王树森)笔记
资源
DRL慕课@Bilibili
DRL(初稿)2021
DRL@Github
强化学习术语
策略
动作
策略梯度
策略学习
策略网络
行为策略 (Behavior Policy) P53
目标策略(Target Policy)P53
经验回放(Experience Reply)P53
离散状态离散动作:表格型方法
连续状态离散动作:DQN方法
连续状态连续动作:连续控制
DRL目录
点击查看目录
第一部分 基础知识
1 深度学习基础
2 概率论基础与蒙特卡洛
3 马尔可夫决策过程 (MDP)
第二部分 价值学习
4 DQN 与 Q 学习
5 SARSA 算法
6 价值学习高级技巧
第三部分 策略学习
7 策略梯度方法(REINFORCE/Actor-Critic)
8 带基线的策略梯度方法(REINFORCE with Baseline/A2C)
9 策略学习高级技巧(TRPO)
10 连续控制
11 对状态的不完全观测
12 模仿学习
第四部分 多智能体强化学习
13 并行计算
14 多智能体系统(MAS/MARL)
15 合作关系设定下的多智能体强化学习(MAC-A2C)
16 非合作关系设定下的多智能体强化学习(MAN-A2C/MADDPG)
17 注意力机制与多智能体强化学习
第五部分 应用与展望
18 AlphaGo 与蒙特卡洛树搜索(MCTS)
19 现实世界中的应用
慕课笔记
深度强化学习基础
1.基本概念

2.价值学习(Value-Based Reinforcement Learning)


3.策略学习(Policy-Based Reinforcement Learning)


4.Actor-Critic方法



附录 贝尔曼方程