

深度学习入门(鱼书)学习笔记:第6章 与学习相关的技巧
第6章 与学习相关的技巧
6.1 参数的更新
各种优化方法源代码见common/optimizer.py。
源代码在ch06/optimizer_compare_naive.py中:
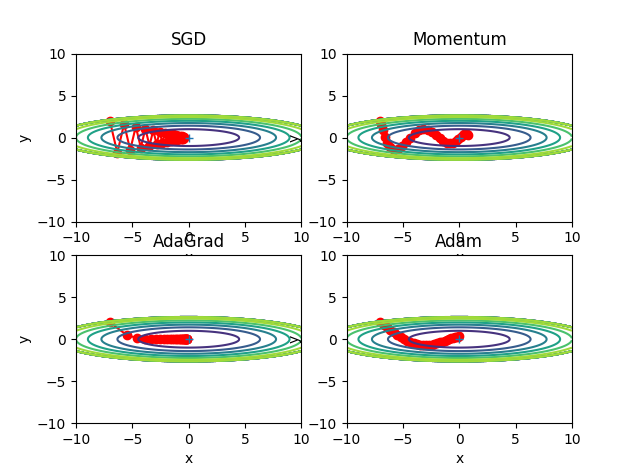
Fig.6-8 最优化方法的比较
基于MNIST数据集的更新方法的比较,源代码在ch06/optimizer_compare_mnist.py中:
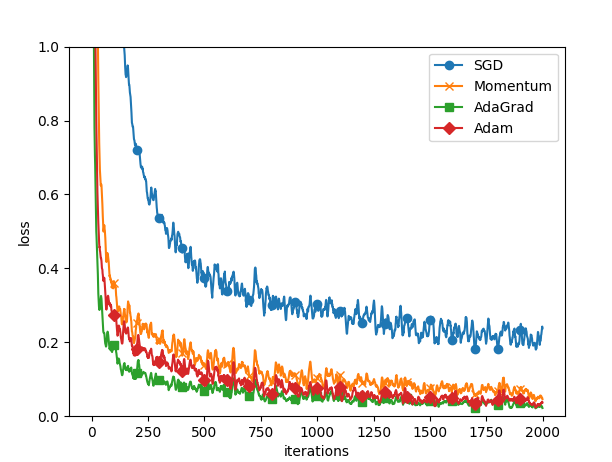
Fig.6-9 基于MNIST数据集的4种更新方法的比较
6.2 权重的初始值
设置不同的权重的标准差,观察各层激活值分布的代码见ch06/weight_init_activation_histogram.py。
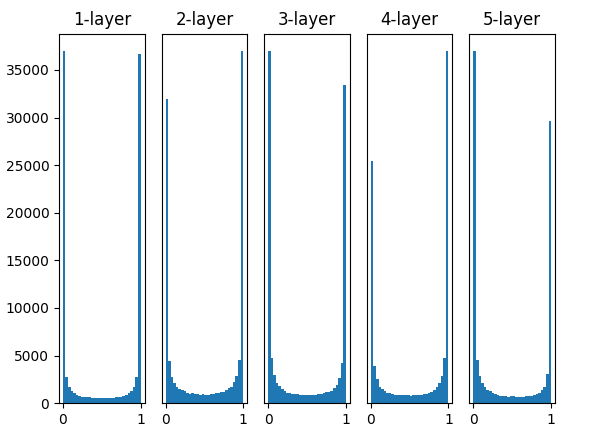
Fig.6-10 使用标准差为1的高斯分布作为权重初始值时的各层激活值的分布
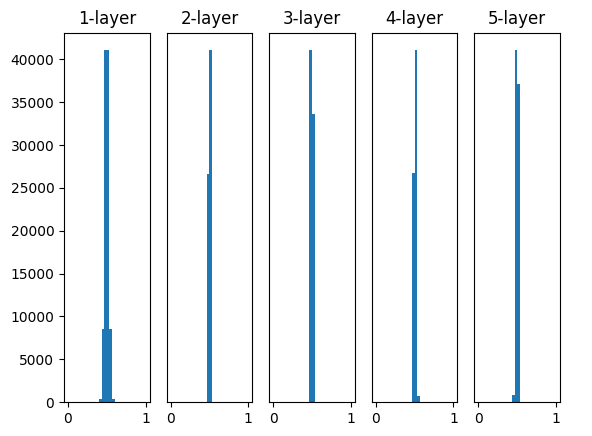
Fig.6-11 使用标准差为0.01的高斯分布作为权重初始值时的各层激活值的分布
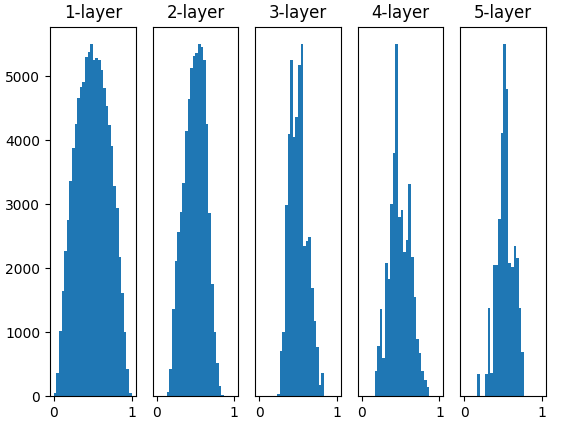
Fig.6-13 使用Xavier初始值作为权重初始值时的各层激活值的分布
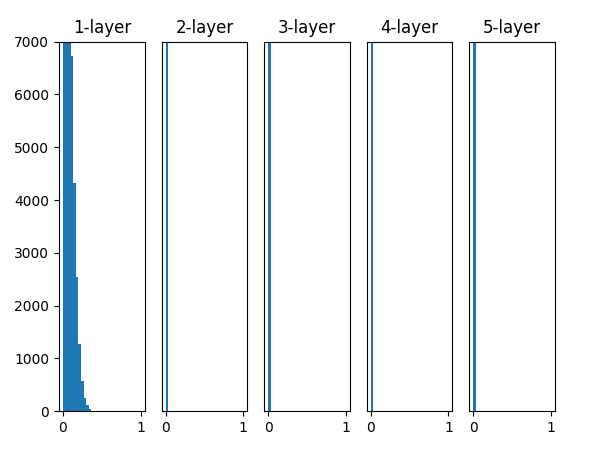
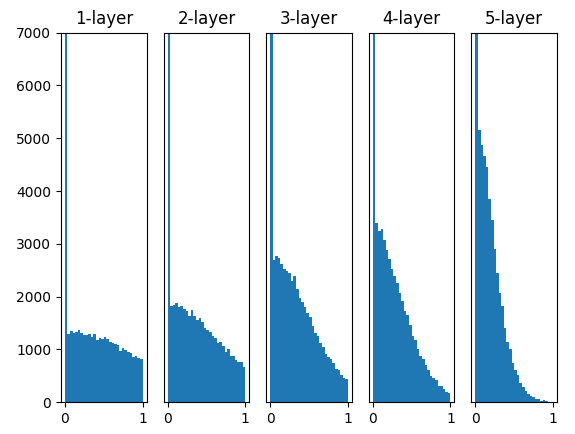
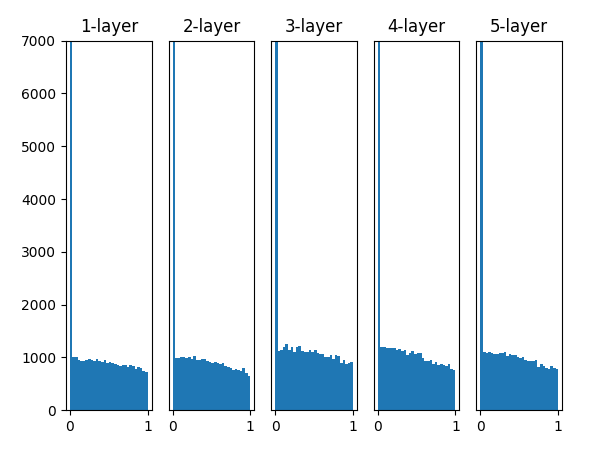
Fig.6-14 激活函数使用ReLU时,不同权重初始值的激活值的分布变化(左:0.01标准差,中:Xavier,右:He)
基于MNIST数据集的权重初始值的比较,源代码在ch06/weight_init_compare.py中。
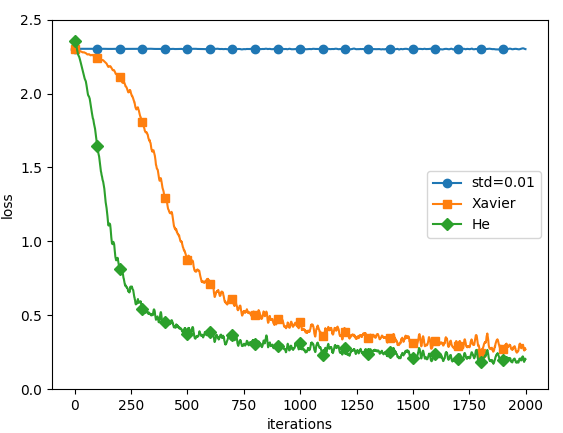
Fig.6-15 基于MNIST数据集的权重初始值的比较:横轴是学习的迭代次数(iterations),纵轴是损失函数的值(loss)
6.3 Batch Normalization
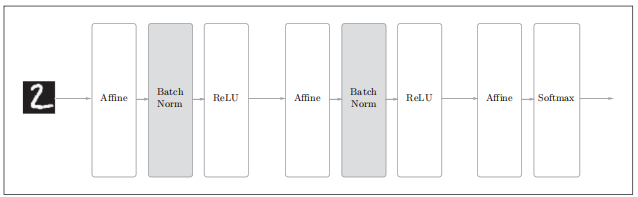
Fig.6-16 使用了Batch Normalization的神经网络的例子(Batch Norm层的背景为灰色)
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按mini batch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的正规化(或归一化):
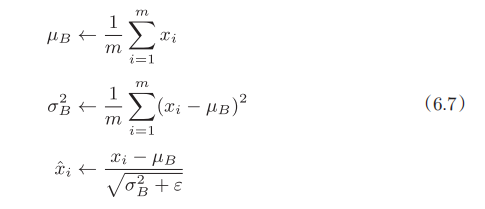
观察使用Batch Norm层和不使用Batch Norm层时学习的过程会如何变化(源代码在ch06/batch_norm_test.py中,并且使用了新函数common/multi_layer_net_extend.py),结果如图6-19所示:
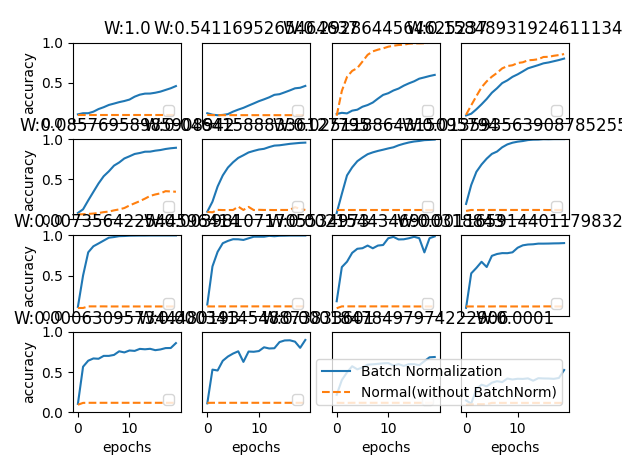
Fig.6-19 图中的实线是使用了Batch Norm时的结果,虚线是没有使用Batch Norm时的结果:图的标题处标明了权重初始值的标准差
6.4 正则化
6.4.1 过拟合
以下实验可以看出明显的过拟合现象。代码见ch06/overfit_weight_decay.py。
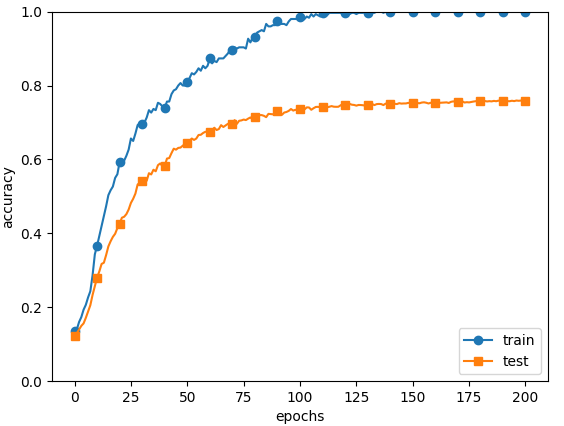
Fig.6-20 训练数据(train)和测试数据(test)的识别精度的变化
6.4.2 权值衰减
权值衰减通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。对于所有权重,权值衰减方法都会为损失函数加上\(\lambda W^2/2\)。
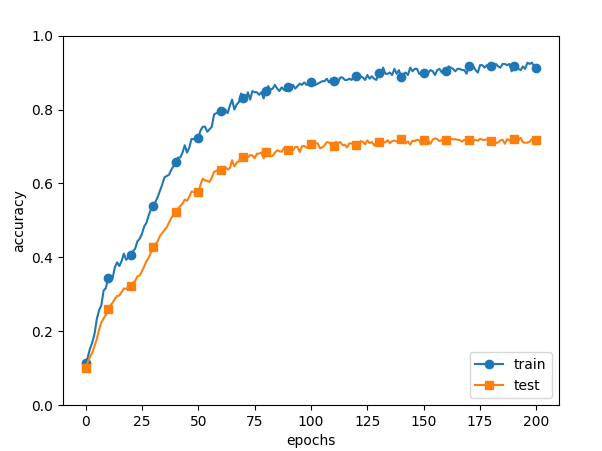
6.4.3 Dropout
Dropout是一种在学习的过程中随机删除神经元的方法。
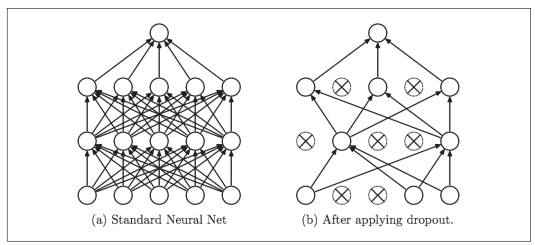
Fig.6-22 Dropout的概念图(引用自文献[14]):左边是一般的神经网络,右边是应用了Dropout的网络。Dropout通过随机选择并删除神经元,停止向前传递信号
Dropout类在common/layers.py中实现。
点击查看class Dropout代码
class Dropout:
"""
http://arxiv.org/abs/1207.0580
"""
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
源代码在ch06/overfit_dropout.py中。另外,源代码中使用了Trainer类(common/trainer.py)来简化实现。
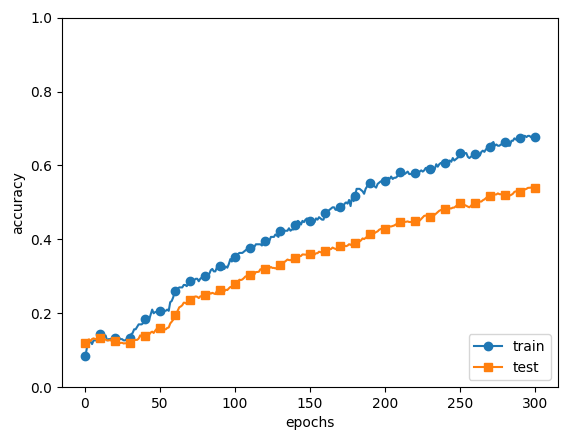
Fig.6-23 左边没有使用Dropout,右边使用了Dropout(dropout_rate=0.2)
可以理解成,
Dropout将集成学习的效果(模拟地)通过一个网络实现了。
6.5 超参数的验证
训练数据用于参数(权重和偏置)的学习,验证数据用于超参数的性能评估。为了确认泛化能力,要在最后使用(比较理想的是只用一次)测试数据。
超参数的最优化步骤
步骤0
设定超参数的范围。
步骤1
从设定的超参数范围中随机采样。
步骤2
使用步骤1中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将epoch设置得很小)。
步骤3
重复步骤1和步骤2(100次等),根据它们的识别精度的结果,缩小超参数的范围。
超参数最优化的实现
使用MNIST数据集进行超参数的最优化。这里将优化“学习率”和“权值衰减系数”这两个超参数。
源代码在ch06/hyperparameter_optimization.py中。
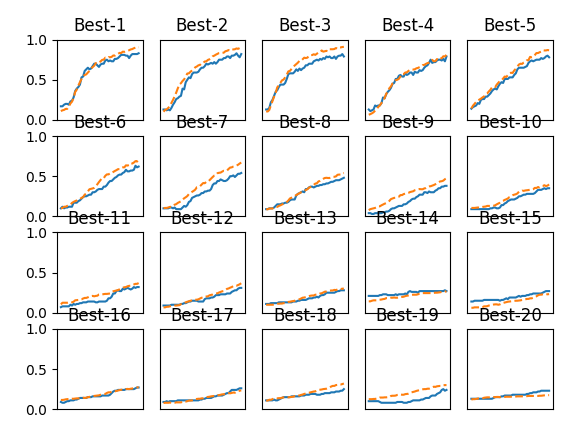
图6-24 实线是验证数据的识别精度,虚线是训练数据的识别精度
点击查看Best1-20超参数的值
=========== Hyper-Parameter Optimization Result ===========
Best-1(val acc:0.83) | lr:0.008810968318640746, weight decay:1.1758595814182495e-06
Best-2(val acc:0.82) | lr:0.008765685024080542, weight decay:7.518188488112639e-07
Best-3(val acc:0.79) | lr:0.008463438405539906, weight decay:6.107815569367644e-06
Best-4(val acc:0.79) | lr:0.006765141581899231, weight decay:5.250802075312128e-07
Best-5(val acc:0.78) | lr:0.009085894747347363, weight decay:5.863529962728907e-07
Best-6(val acc:0.62) | lr:0.0037078828500800125, weight decay:3.723198692559057e-06
Best-7(val acc:0.54) | lr:0.005012414660405193, weight decay:1.2134604482641728e-08
Best-8(val acc:0.48) | lr:0.0033814604633099787, weight decay:1.363834241595748e-06
Best-9(val acc:0.38) | lr:0.002854104995365807, weight decay:1.1679722742252107e-06
Best-10(val acc:0.35) | lr:0.0025578541351428488, weight decay:2.13811847147454e-05
Best-11(val acc:0.32) | lr:0.0020864811765931163, weight decay:3.150589272861672e-05
Best-12(val acc:0.31) | lr:0.001484903781067173, weight decay:1.1602244846361431e-06
Best-13(val acc:0.28) | lr:0.002077454702210735, weight decay:5.181521372762224e-07
Best-14(val acc:0.27) | lr:0.0008939464072589195, weight decay:2.4212420008228246e-07
Best-15(val acc:0.27) | lr:0.0010168585828838179, weight decay:2.887052405974142e-07
Best-16(val acc:0.27) | lr:0.0007451844924650946, weight decay:9.365039871227353e-06
Best-17(val acc:0.26) | lr:0.0010624747407791736, weight decay:7.947366902798932e-07
Best-18(val acc:0.25) | lr:0.0021681955840812677, weight decay:8.365369908936944e-07
Best-19(val acc:0.24) | lr:0.001122910467503502, weight decay:3.4642243296546025e-08
Best-20(val acc:0.23) | lr:0.00036920101540212385, weight decay:4.665007415127146e-08
6.6 小结
本章我们介绍了神经网络的学习中的几个重要技巧。参数的更新方法、权重初始值的赋值方法、Batch Normalization、Dropout等,这些都是现代神经网络中不可或缺的技术。另外,这里介绍的技巧,在最先进的深度学习中也被频繁使用。
