

深度学习入门(鱼书)学习笔记:第5章 误差反向传播
第5章 误差反向传播
5.1 计算图
计算图解题流程:
1.构建计算图
2.在计算图上,从左向右进行计算
使用计算图的原因:可以通过反向传播高效计算导数。
计算图的优点:可以通过正向传播和反向传播高效地计算各个变量的导数值。
举例问题1:太郎在超市买了2个100日元一个的苹果,消费税是10%,请计算支付金额。

Fig.5-1 基于计算图求解的问题1的答案
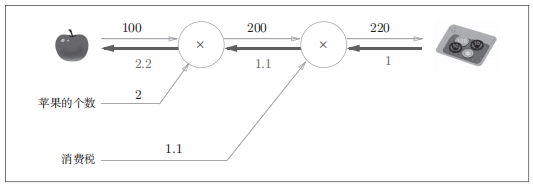
Fig.5-2 基于反向传播的导数的传递
5.2 链式法则
定义:如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。
举例:
反向传播计算过程如下:
Fig.5-7 计算图的正向传播
Fig.5-8 计算图的反向传播
5.3 反向传播
加法的反向传播:将上游的值传给下游,不需要正向传播的输入信号。
乘法的反向传播:将上游的值乘以正向传播时的输入信号的“翻转值”后传给下游,需要正向传播的输入信号。
Fig.5-14 购买苹果的反向传播的例子
5.4 简单层的实现
Fig.5-17 购买2个苹果和3个橘子
5.5 激活层函数的实现
Fig.5-18 ReLU层的计算图
Fig.5-21 Sigmoid层的计算图(简洁版)
为什么是exp(-x)而不是exp(x)?
Fig.5-22 Sigmoid层的计算图:可以根据正向传播的输出y计算反向传播
5.6 Affine/Softmax层的实现
5.6.1 Affine层
5.6.2 批版本的Affine层
源代码common/layers.py中类的实现class Affine如下:
点击查看Affine代码
# 中间仿射层(不考虑张量的版本)
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
# 权重和偏置参数的导数
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx
5.6.3 Softmax-with-Loss层
神经网络中进行的处理有推理和学习两个阶段,前者通常不使用Sotfmax层,后者则需要Softmax层。
Softmax-with-Loss层的推导结果见附录A。
神经网络的输出与监督数据的误差越大,Softmax层前面的层会从这个误差中学习到的内容越“大”;误差越小,学习到的内容越“小”。
源代码common/layers.py中的类class SoftmaxWithLoss实现如下:
点击查看SoftmaxWithLoss代码
# 输出层(不考虑张量的版本)
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 损失
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t) # 交叉熵误差
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size # 除以批的大小,传递给前面层的是单个数据的误差
return dx
5.7 误差反向传播法的实现
5.7.1 神经网络学习的全貌图
步骤1(mini-batch)->步骤2 (计算梯度)->步骤3 (更新参数)->步骤4 (重复)
5.7.2 对应误差反向传播法的神经网络的实现
源代码ch05/two_layer_net.py中的类实现class TwoLayerNet如下:
点击查看TwoLayerNet代码
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from common_all.layers import *
from common_all.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values(): # layers.values是什么?
x = layer.forward(x)
return x
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1:
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
5.7.3 误差反向传播法的梯度确认
梯度确认:确认数值微分求出的梯度结果和误差反向传播法求出的结果是否一致的操作。
梯度确认的源代码ch05/gradient_check.py实现如下 :
点击查看gradient_check.py代码
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from dataset_all.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
x_batch = x_train[:3]
t_batch = t_train[:3]
# 通过数值方法和反向传播方法计算梯度
grad_numerical = network.numerical_gradient(x_batch, t_batch)
grad_backprop = network.gradient(x_batch, t_batch)
# 求各个权重的绝对误差的平均值
for key in grad_numerical.keys():
diff = np.average(np.abs(grad_backprop[key] - grad_numerical[key]))
print(key + ":" + str(diff))
点击查看梯度确认运行结果
"D:\Program Files\Python\Python37\python.exe" D:/Code/CodePython/02_dl_from_scratch_demo/ch05/gradient_check.py
W1:3.8190704844174565e-10
b1:2.014022811625037e-09
W2:5.339842233418217e-09
b2:1.4011187530055257e-07
可以看出,数值微分和误差反向传播法求出的梯度结果误差很小,证明误差反向传播法的实现是正确的。
5.7.4 使用误差反向传播法的学习
源代码ch05/train_neuralnet.py的实现如下:
点击查看train_neuralnet.py代码
# coding: utf-8
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset_all.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 通过数值微分法求梯度
#grad = network.numerical_gradient(x_batch, t_batch)
# 通过误差反向传播法求梯度
grad = network.gradient(x_batch, t_batch)
# 更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(i, iter_per_epoch, train_acc, test_acc)
设定迭代10000次,学习过程的print(i, iter_per_epoch, train_acc, test_acc)打印输出如下:
点击查看打印输出
"D:\Program Files\Python\Python37\python.exe" D:/Code/CodePython/02_dl_from_scratch_demo/ch05/train_neuralnet.py
0 600.0 0.09676666666666667 0.0934
600 600.0 0.9013333333333333 0.9071
1200 600.0 0.9202166666666667 0.9211
1800 600.0 0.9369666666666666 0.9354
2400 600.0 0.94495 0.941
3000 600.0 0.95205 0.9507
3600 600.0 0.9587666666666667 0.9565
4200 600.0 0.9636833333333333 0.959
4800 600.0 0.9661 0.9625
5400 600.0 0.9697166666666667 0.965
6000 600.0 0.9718 0.9646
6600 600.0 0.9734666666666667 0.9666
7200 600.0 0.9743 0.9669
7800 600.0 0.97685 0.9689
8400 600.0 0.9783166666666666 0.9696
9000 600.0 0.9797333333333333 0.9713
9600 600.0 0.9804 0.9723
5.8 小结
本章我们介绍了将计算过程可视化的计算图,并使用计算图,介绍了神经网络中的误差反向传播法,并以层为单位实现了神经网络中的处理。我们学过的层有ReLU层、Softmax-with-Loss层、Affine层、Softmax层等,这些层中实现了forward和backwart方法。通过将数据正向和反向地传播,可以高效地计算权重参数的梯度。通过使用层进行模块化,神经网络中可以自由地组装层,轻松构建出自己喜欢的网络。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY