Python的Requests库与网页爬取
requests库的几种方法

其他几个方法内部实际都调用了requests.request()方法
Response对象的属性

首先要使用r.status_code判断连接是否成功。
Request库的异常

爬取网页的通用代码
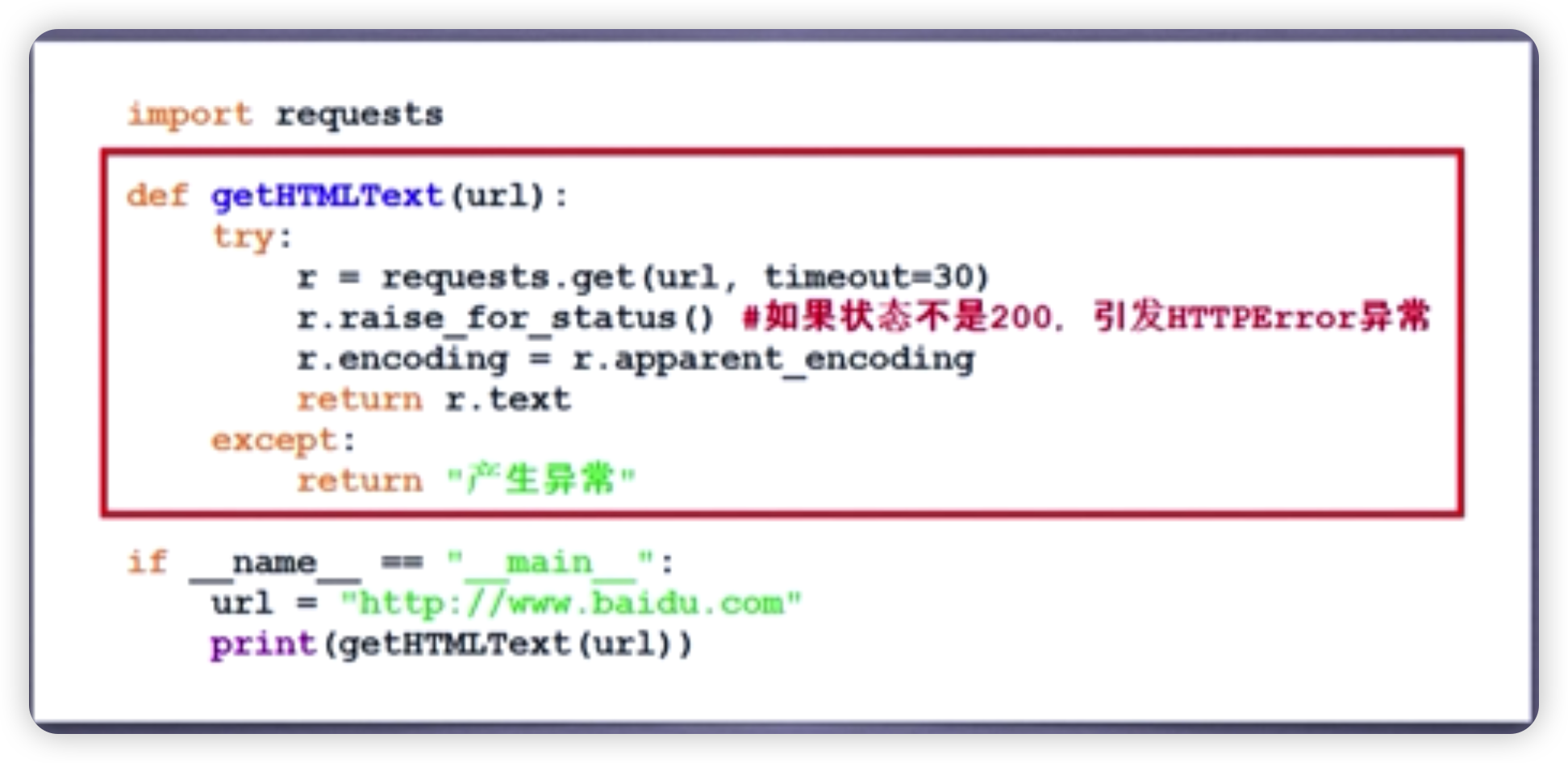
需要处理异常,使爬取网页变得更有效、可靠、稳定。
HTTP

无状态:第一次请求和第二次请求并无直接关联
HTTP协议对资源的操作

PUT也可以起到更新局部资源的效果,不过相比PUT,PATCH更加节省网络带宽
head方法允许用很少的网络流量获取网页资源的概要信息

POST或PUT方法根据用户提交数据的不同会在服务器上进行整理


GET方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号